梁山做网站价格网站开发使用语言
一、项目概述
1.1 编写目的
本次测试报告,为自动化测试框架性能测试总结报告。目的在于总结我们课程所压测的目标系统的性能点、优化历史和可优化方向。
1.2 项目背景
我们公开课的性能测试目标系统。主要是用于我们课程自动化测试框架功能的实现,以及性能测试和调优的实例系统。
1.3 名词解析
1. 并发用户数:测试同时访问被测系统的线程数。由于测试过程中,每个线程都是以尽快的速度发送请求,与实际用户请求有较大差别,因此它不等同于实际用户并发请求。
2. 响应时间:线程向被测系统发请求,接收到回包的时间统计。
3. 负载能力:系统维持稳定运行的最大负载。
4. 最大并发数:系统崩溃或者处于瓶颈状态的并发数。
二、测试环境说明
2.1 服务器配置
| 服务器名称 | 配置详情 | 数量 | IP |
| 数据库服务器 | Centos7.2,2.8GHz X 1,1G,50G | 1 | 120.24.182.157 |
| Web服务器 | Window10,2.8GHz X 4,2G,500G | 1 | 192.168.1.110 |
三、测试方案
3.1 测试计划
| 测试轮次 | 测试时间 | 人员 | 地点 |
| 第一轮:页面测试 | 2022.12.19 | Perlly | 公开课 |
| 第二轮:接口测试 | 2022.12.20 | Perlly | 公开课 |
| 第三轮:场景压测 | 2022.12.21 | Perlly | 公开课 |
3.2 测试方案
1. 梯度增压方案:确定系统的压力瓶颈。
2. 稳定负载方案:得出系统的负载性能。
3.3 测试场景
场景1:压力场景。设计50个虚拟用户,每20s增加5个,直到增加到50个、或者直到系统出现异常。
场景2:负载场景。分析场景1的结果,得出系统的最大负载;然后直接运行负载对应的虚拟用户数。
四、测试结果
4.1 响应时间
(分析:系统正常运行时,响应时间维持在20ms之内,属于较好的性能情况。当系统到达瓶颈,并且临近崩溃之时,响应时间呈指数上升,属于异常情况。)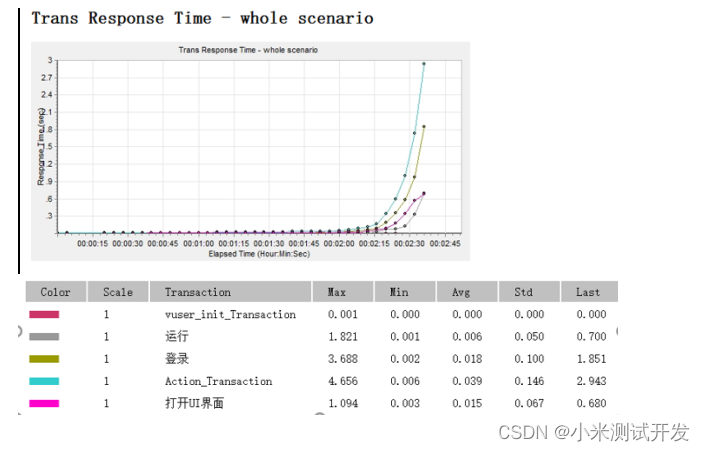
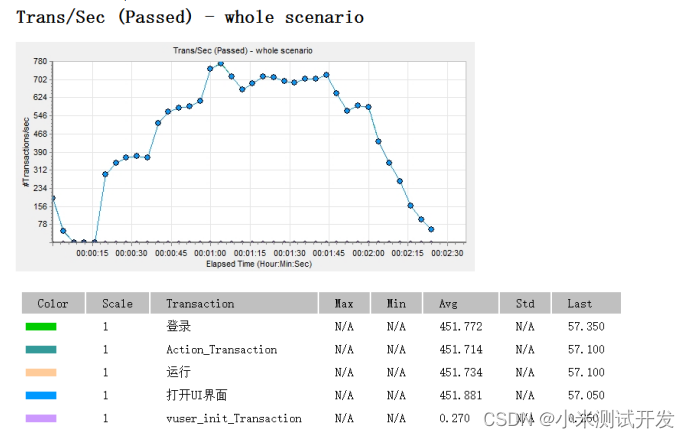
4.2 最大并发
(从图中可以看出,系统在前一分钟,随着请求量的上升,并发数一直处于稳定上升状态,最高时,可以达到800左右。在运行策略一分钟后,用户大概增加到30个的时候,系统的并发到达一个峰值的动态平衡。当用户超过40的时候,系统的并发呈直线下降趋势,也就是说,系统在这样的压力下,崩溃了。因此,系统能支持的最大负载约750,此时的虚拟用户约20-30个。)
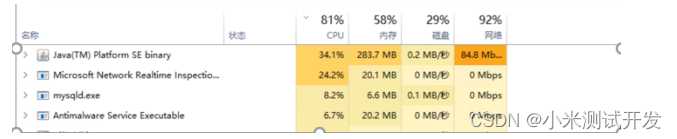
4.3 服务器性能
4.4 服务器报错
错误1:数据库连接池不够

错误2:java jvm内存分配不够

4.4 负载测试结果
五、结果分析
5.1 系统和方案优化记录
1. 优化数据库网络环境
2. 优化日志输出
3. 数据库索引优化
5.2 系统性能结果分析
1. 网络分析。从场景脚本来看,场景涉及网页压测,结合服务器的网络状况,可以得出结论,若要提升静态页面的并发,还需要提升服务器的带宽条件,或者是优化页面元素。
2. 服务器性能分析。服务器的CPU消耗殆尽,主要是原因是java应用程序和数据库都部署在同一服务器,形成了资源抢占的情况。因此,分开部署,可以提升服务器负载。
3. 服务器错误分析。从两个报错,可以得出两个优化方向:其一,优化jvm配置;其二,优化数据库连接池配置。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。