郑州春蕾网站建设wordpress本地环境下可以更新使用
随着科技的不断发展,视频已经成为了企业业务中不可或缺的一部分。无论是在线教育、企业培训还是产品展示,视频都发挥着至关重要的作用。为了满足企业对视频应用的需求,美摄视频SDK应运而生,为企业提供了一站式的视频解决方案。
一、多平台SDK快速接入,降低企业开发成本
美摄视频SDK支持多平台接入,包括Android、iOS、Web、Windows等主流操作系统,以及各种主流浏览器。企业只需一次开发,即可实现全平台覆盖,大大降低了开发成本和维护成本。同时,美摄视频SDK还提供了丰富的API接口,方便企业快速集成到现有系统中,提高开发效率。
二、高清画质,提升用户体验
美摄视频SDK采用了先进的视频编码技术,能够实现高清画质的视频传输。在保证视频清晰度的同时,还能够有效降低视频传输的带宽需求,节省企业的网络资源。此外,美摄视频SDK还支持实时美颜、滤镜、特效等功能,让企业的视频内容更加丰富多彩,提升用户体验。
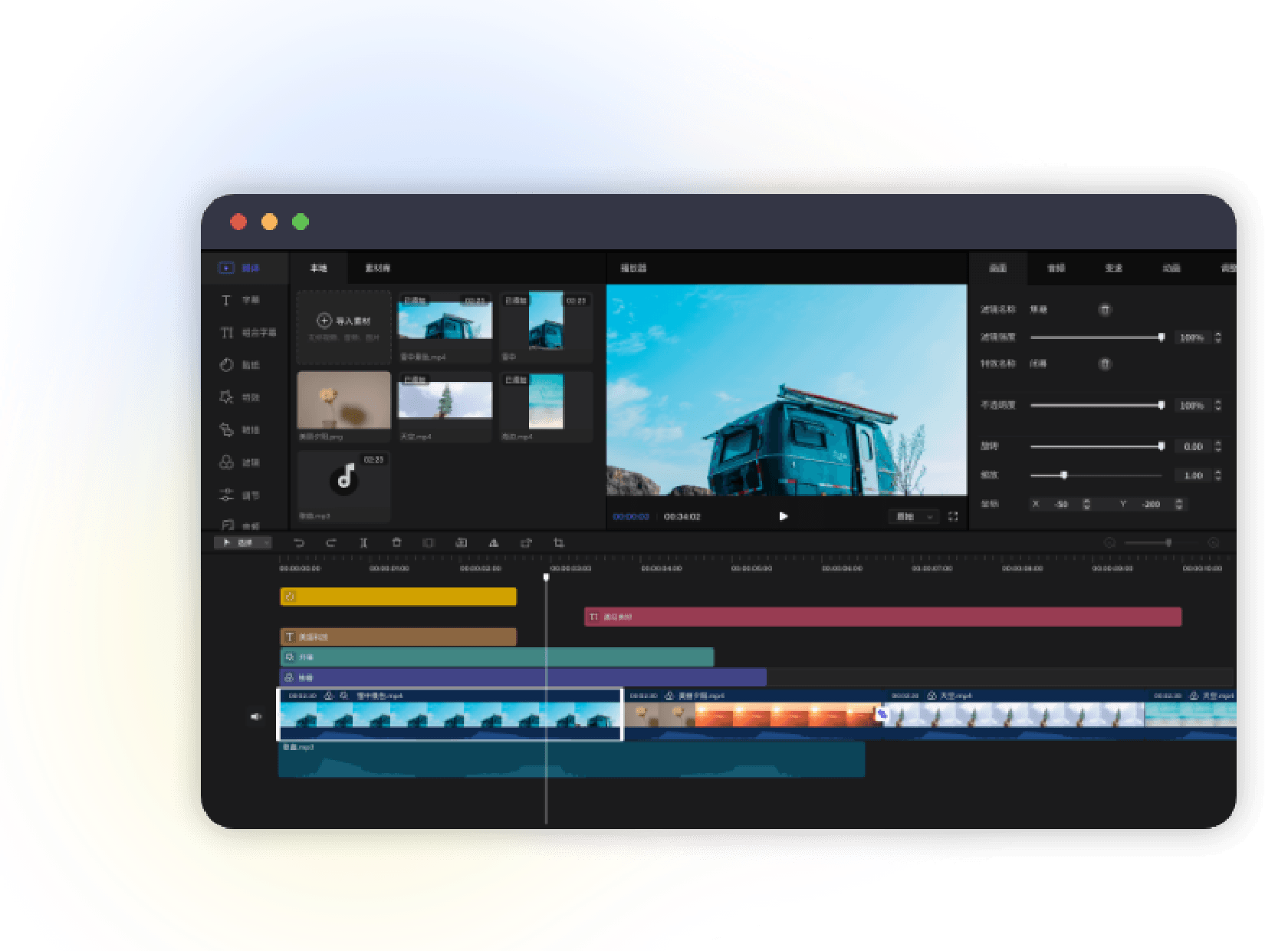
三、稳定可靠,保障企业业务运行
美摄视频SDK经过了严格的测试和优化,确保了其在各种网络环境下的稳定性和可靠性。无论是在4G、Wi-Fi还是弱网环境下,美摄视频SDK都能够保证视频的流畅播放,避免因网络问题导致的业务中断。此外,美摄视频SDK还具备强大的抗丢包能力,能够在网络波动时自动调整视频质量,确保企业业务的正常运行。
四、丰富的功能模块,满足企业多样化需求
美摄视频SDK提供了丰富的功能模块,包括实时音视频通信、直播推流、录制回放、弹幕互动等。企业可以根据自身需求,灵活选择功能模块,快速搭建自己的视频应用。同时,美摄视频SDK还支持多人视频会议、屏幕共享、文件传输等功能,满足企业多样化的沟通需求。
五、专业的技术支持,助力企业业务发展
美摄拥有一支专业的技术团队,为企业提供全方位的技术支持。从SDK的安装部署、功能定制,到后期的系统维护和升级,美摄技术团队都能够提供及时、专业的服务。此外,美摄还提供了丰富的技术文档和示例代码,帮助企业快速上手SDK开发,助力企业业务的快速发展。
美摄视频SDK凭借其多平台接入、高清画质、稳定可靠、丰富功能和专业支持等优势,成为了企业视频应用的最佳选择。无论您是在线教育、企业培训还是产品展示,美摄视频SDK都能为您提供一站式的解决方案,助力您的企业业务飞跃。