百度网站优化是什么意思商城类网站建设+数据库
文章目录
- 专栏
- 前言
- 锚点二次开发
- 添加回调函数
- 辅助Model类
- 下集预告
专栏
Halcon开发 博客专栏
WPF/HALCON机器视觉合集
前言
Halcon控件C#开发是我们必须掌握的,因为只是单纯的引用脚本灵活性过低,我们要拥有Halcon辅助开发的能力
锚点开发是我们常用的开发方式,用于寻找相似点。如图为锚点
锚点二次开发
添加回调函数
回调函数在HDrawingObject的OnDrag函数中,


/// <summary>
/// 画圆
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void Button_Click_1(object sender, RoutedEventArgs e)
{//创建一个圆形,圆心为(100,100),半径为50var drawingObject = HDrawingObject.CreateDrawingObject(HDrawingObject.HDrawingObjectType.CIRCLE, new HTuple[] { 100, 100, 50 });//添加回调drawingObject.OnDrag(HDrawingObjectCallbackClass);//临时存放ListdrawingObjects.Add(drawingObject);//将圆画再hSmart画布上面hSmart.HalconWindow.AttachDrawingObjectToWindow(drawingObject);}/// <summary>
/// 回调函数
/// </summary>
/// <param name="drawid">回调物体</param>
/// <param name="window">窗体</param>
/// <param name="type">类型</param>
public void HDrawingObjectCallbackClass(HDrawingObject drawid, HWindow window, string type)
{//由于是圆形锚点,所以有x,y,radius三个属性var htuples = new HTuple[] {drawid.GetDrawingObjectParams("row"),//x轴坐标drawid.GetDrawingObjectParams("column"),//y轴坐标drawid.GetDrawingObjectParams("radius"),//半径};}
辅助Model类
在Halcon控件中,每个被创建的控件都会有一个唯一的ID,用于区别每个的信息。如果我想实时更新被拖动锚点的坐标,我就需要去调用HDrawingObject的GetDrawingObjectParams方法,就比较麻烦。所以我们可以通过自定义一个类用于方便的管理
/// <summary>
/// 因为HDrawingObject没有坐标参数,所以我们为了方便操作添加创建了一个HDrawingObjectModel
/// </summary>
public class HDrawingObject_CircleModel
{public HTuple? Row { get; set; }public HTuple? Column { get; set; }public HTuple? Radius { get; set; }public readonly HDrawingObject HDrawingObject;public readonly long Id;public HDrawingObject_CircleModel(HDrawingObject hDrawingObject){HDrawingObject = hDrawingObject;Id = HDrawingObject.ID;Update(HDrawingObject);}public void Print(){System.Diagnostics.Debug.WriteLine($"id:[{HDrawingObject.ID}],row:[{Row}],column:[{Column}],radius:[{Radius}]");}public void Update(HDrawingObject hDrawingObject){Row = hDrawingObject.GetDrawingObjectParams("row");Column = hDrawingObject.GetDrawingObjectParams("column");Radius = hDrawingObject.GetDrawingObjectParams("radius");}}然后我们新建一个List用于存放新增的锚点
/// <summary>
/// 用来存放后面所有新增的锚点
/// </summary>
private List<HDrawingObject_CircleModel> drawingObjects;
更新点击事件代码
/// <summary>
/// 画圆
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void Button_Click_1(object sender, RoutedEventArgs e)
{//创建一个圆形,圆心为(100,100),半径为50var drawingObject = HDrawingObject.CreateDrawingObject(HDrawingObject.HDrawingObjectType.CIRCLE, new HTuple[] { 100, 100, 50 });//----添加回调---//添加拖拽回调drawingObject.OnDrag(HDrawingObjectCallbackClass);//放缩变化drawingObject.OnResize(HDrawingObjectCallbackClass);var model = new HDrawingObject_CircleModel(drawingObject);//临时存放ListdrawingObjects.Add(model);model.Print();//将圆画再hSmart画布上面hSmart.HalconWindow.AttachDrawingObjectToWindow(drawingObject);}/// <summary>
/// 回调函数
/// </summary>
/// <param name="drawingObject">回调物体</param>
/// <param name="window">窗体</param>
/// <param name="type">类型</param>
public void HDrawingObjectCallbackClass(HDrawingObject drawid, HWindow window, string type)
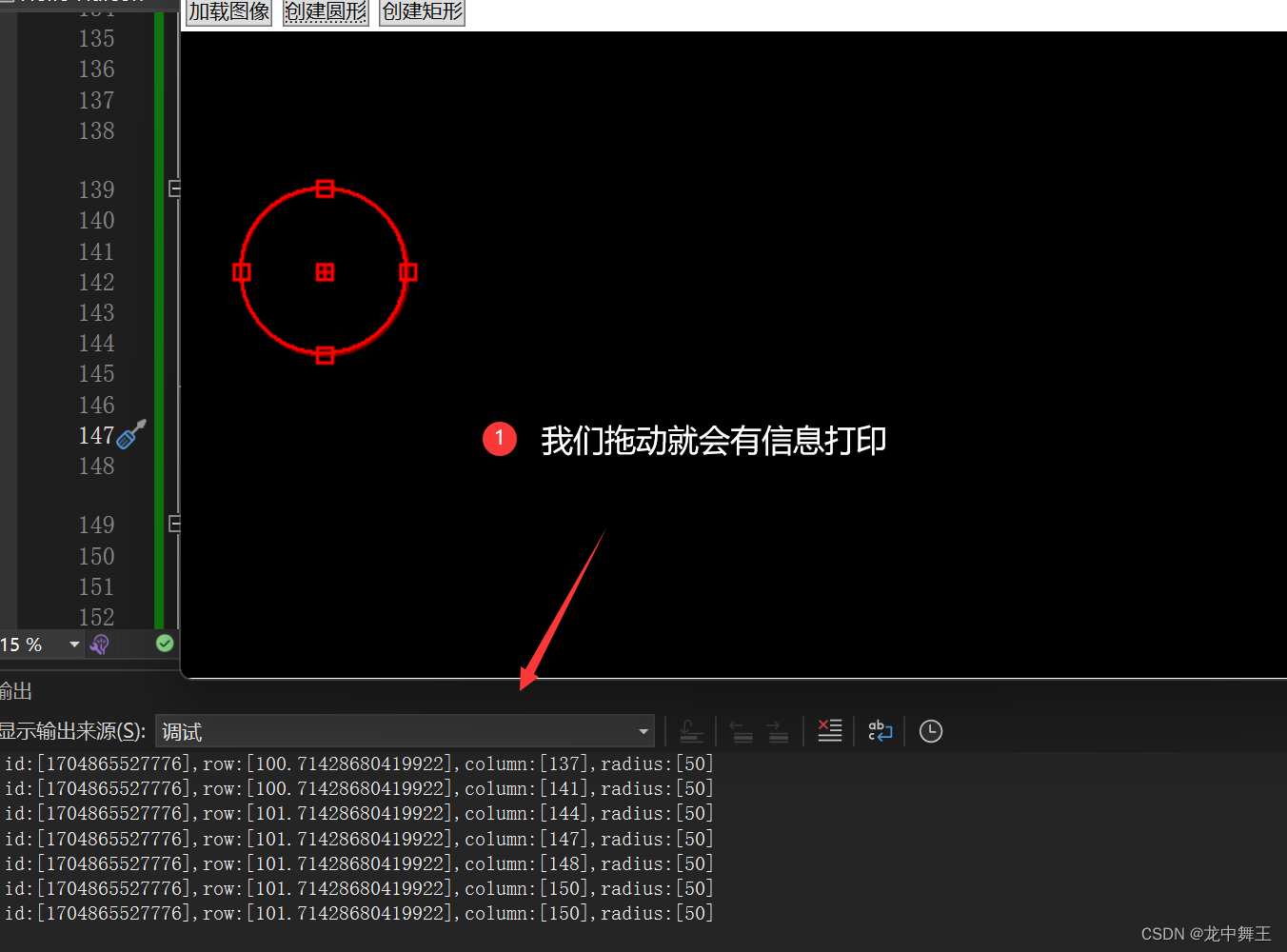
{var drawObj = drawingObjects.FirstOrDefault(t => t.HDrawingObject.ID.Equals(drawid.ID));//如果不为空则打印if (drawObj != null){drawObj.Update(drawid);drawObj.Print();}else{Debug.WriteLine($"drawid.id[{drawid.ID} is not find!]");}}
结果
下集预告
下一期我将会讲解如何使用Halcon和C#进行混合开发,因为难度较大,所以我会咕咕咕一段时间,去了解一下怎么使用。应该是难度不大的,就是把Halcon的语言翻译一下。