企业建站系统模板东莞有口碑的教育网站建设
如果要评一个2023科技圈的热搜榜,那么以人工智能聊天机器人 ChatGPT 为代表的 AI大模型 绝对会霸榜整个2023。
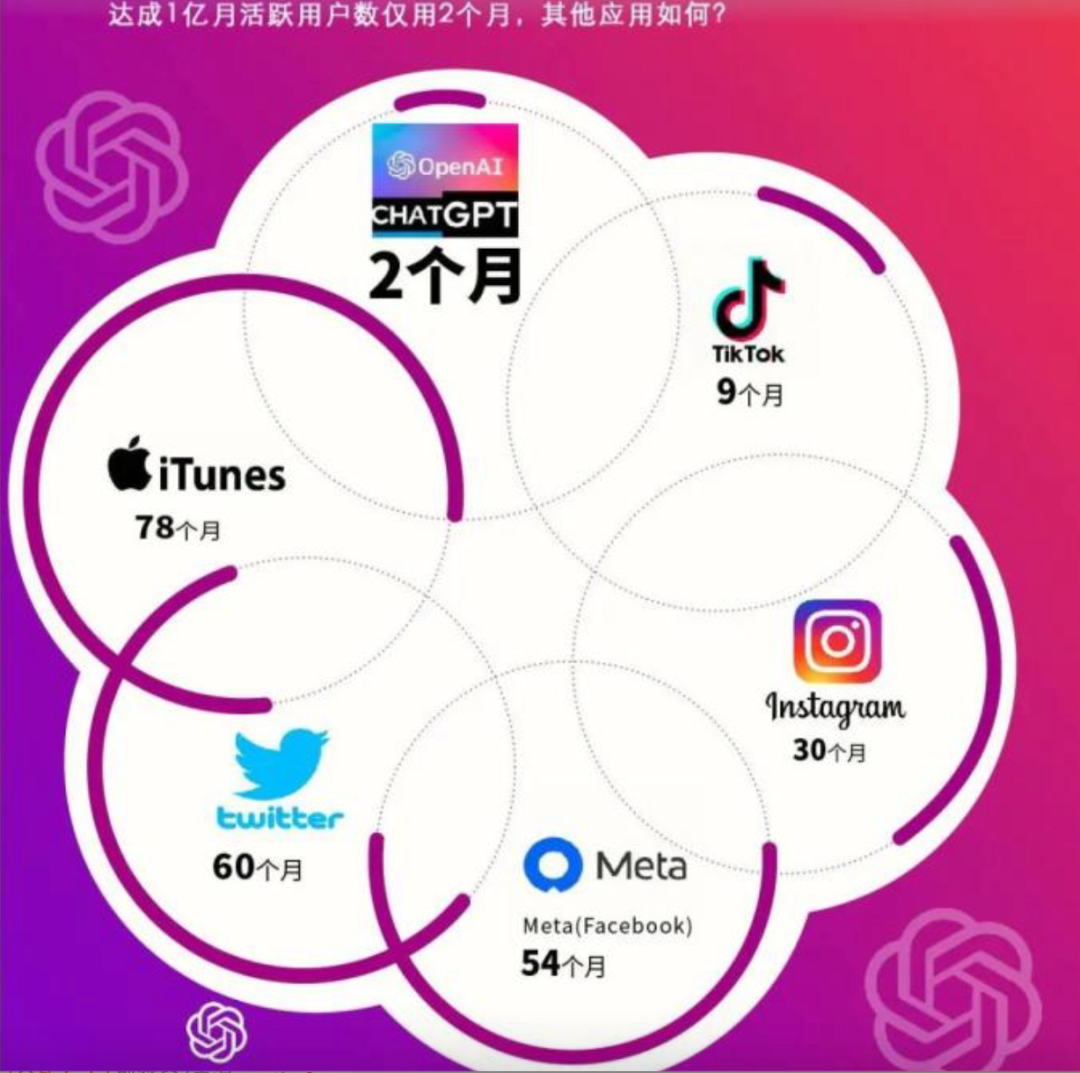
ChatGPT 于2022年11月30日发布。产品发布5日,注册用户数就超过100万。推出仅两个月后,它在2023年1月末的月活用户已经突破了1亿,成为史上用户增长速度最快的消费级应用程序。而此前,火爆全球的短视频社交平台 TikTok 达到1亿用户则用了9个月。
大数据搭“台” AI唱“戏”
ChatGPT 的横空出世掀起一波席卷全球的大模型浪潮,各大互联网巨头纷纷发布了发布了自己的大模型产品,例如微软的 Copilot、谷歌的 Gemini、阿里的通义千问、百度的文心一言等等。各种强劲的需求瞬间传导至上下游,押中智能算力的宝,“卖铲人”英伟达赚得盆满钵满。而随着 AIGC、大模型等新应用、新业态不断涌现,越来越多互联网企业也选择了对接大模型应用,或者训练自己的 AI 模型以提升自有产品的竞争力。
人工智能(AI)的汹涌而来,得益于高质量数据的发展。据 OpenAI 披露,此前 GPT-3 使用了1750亿个参数,进行训练的文本数据多达45TB,相当于472万套中国四大名著,而 GPT-4 更是高达1.8万亿参数。其数据量在之前训练数据集的基础上又增加了多模态数据,数据量更是达到前所未有的 PB 级别。
数据是新的石油,为大模型发展提供足够的能量。正是有了大量高质量的训练数据,大模型才能不断刷新自己的能力极限。互联网每时每刻都会产生海量数据,然后如此庞大的数据,需要进行数据的 ETL 清洗、数据建模、数据加工存储才能用于 AI 模型训练,而大数据计算引擎则是高效提炼这种数据石油的核心工厂。
EasyMR:AI的助推器
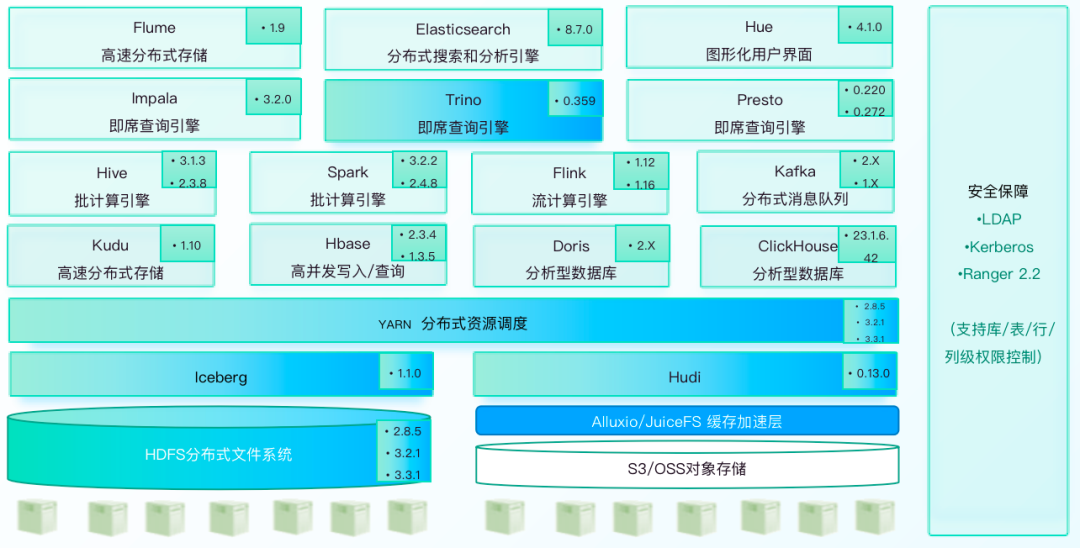
「EasyMR大数据计算引擎」正是这样一款产品,它不仅仅是数据处理的利器,更是 AI 应用的强大助推器。随着 AI 技术的不断进步,对数据建模、数据处理的要求也日益增长,EasyMR 以其卓越的性能和灵活性,正在成为 AI 应用不可或缺的一部分。
弹性与可扩展性——AI应用的基石
在 AI 项目中,数据量的不断膨胀要求计算资源能够随需求弹性伸缩。EasyMR 基于先进的开源组件,如 Hadoop、Hive、Spark 等,为用户提供了一个能够自如应对数据规模变化的弹性计算平台。无论是实时数据处理的需求,还是海量数据存储的挑战,EasyMR 都能够提供稳定可靠的服务,保证 AI 应用的数据处理不受限制,让算法的潜能得到充分发挥。
安全与可靠——AI应用的保障
数据的安全性和可靠性是 AI 应用的另一大关注点。EasyMR 采取了多层次的安全措施集成 LDAP+Ranger+Kerberos,打通全域用户体系,确保数据在存储、传输和处理的每一个环节的数据安全。这种安全性的保障使得企业可以放心地将关键数据交给 EasyMR,专注于 AI 算法和应用的开发,而无需担心数据泄露或丢失的风险。
低成本——AI应用的加速器
成本控制是每一个 AI 项目都必须考虑的因素。EasyMR 的低成本优势意味着企业可以用更少的投资获得更强的数据计算能力。EasyMR 计算引擎支持 GPU 调度和执行,可以实现 AI 算法的高效调度和执行,提升计算速度和性能,从而更好地满足大规模数据处理和分析的需求。这让原本资源有限的小型企业和初创公司也能够利用先进的 AI 技术,将创新的想法迅速转化为现实,加速AI应用的商业化进程。
一站式服务——AI应用的便捷之选
从创建到部署,再到运维与监控,EasyMR 提供了一站式的大数据解决方案。开发者不需要在不同的平台间跳转,即可高效地完成整个 Hadoop 集群的生命周期管理。这种便捷性大幅降低了应用开发的门槛,使得更多的企业和开发者能够投入到 AI 的创新和实践中去。
总结
随着人工智能技术的不断成熟,对于背后的数据处理能力提出了更高的要求。EasyMR 作为一款弹性计算引擎,不仅满足了当前 AI 应用对大数据处理的需求,还为企业的未来的发展提供了稳固的基础。
无论是在弹性伸缩、安全可靠、低成本还是一站式服务上,EasyMR 都展现出了对 AI 未来的深刻理解和强大支持。选择 EasyMR,就是为你的 AI 应用插上翅膀,一飞冲天。
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn