静态网站有后台吗太原市住房和城乡建设局的网站首页
| 彭姝麟 Acrelpsl |
概述: 随着工业自动化程度的不断提高,变频器也得到了非常广泛的应用。作为电力电子器件,变频器中要进行大功率二极管整流,大功率晶体管变压,在输入输出回路产生电流高次谐波,干扰供电系统、负载以及附近其它电气设备。在实际使用过程中,经常遇到变频器谐波干扰问题。
工业现场PLC/DCS控制系统中,常常会出现测量信号不稳定现象,一种是由电磁干扰导致,另一种是高频信号渗入,如电流信号输出控制变频器,变频器高频干扰渗入信号中,这样的干扰信号使得变频器和阀门工作不稳定,在两个设备信号连接之间加装信号隔离器,是有效解决电磁干扰及高频信号渗入影响的方法之一。
1:PLC/DCS控制系统中的干扰
PLC/DCS控制系统中主要干扰源有:空间的辐射干扰、信号线引入的干扰、接地系统混乱时的干扰、PLC/DCS系统内部的干扰,其中电源的干扰和信号线引入的干扰,通常称为传导干扰,这种传导干扰在工业现场较常见也较严重。
1.1 PLC/DCS控制系统干扰类型及现象
PLC/DCS控制系统中干扰的类型通常按干扰模式不同划分,分为共模干扰和差模干扰。共模干扰是信号对地的电位差,主要由电网串入、地电位差及空间电磁辐射在信号线上感应的共态(同方向)电压叠加所形成。差模干扰是指作用于信号两极间的干扰电压,主要是由空间电磁场在信号间耦合感应及由不平衡电路转换共模干扰所形成的电压,这种电压叠加在信号上,会直接影响测量和控制精度。
1.2 PLC/DCS控制系统干扰问题解决方向
1)切断或衰减电磁干扰的传播途径
2)提高装置和系统的抗干扰能力
2: 信号隔离器在PLC/DCS控制系统中的作用
实际应用中,控制系统中的信号干扰问题有时会非常严重,有些时候即使信号电缆采用屏蔽线也不能完全消除这些干扰,例如由于接地点不同引起的接地环流干扰。而采用信号隔离器的接线方式切断了传导干扰的传播途径,减小设备直接连接的接地环路带来的信号失真,可以有效地提高在PLC/DCS控制系统中模拟量控制模块每一路信号供电电源安全性、稳定性和相对独立性,这样便可以降低因为雷击过电压等原因可能会造成的模板击穿或烧毁概率,提高了控制模块的测量精度和4-20MA 模拟量信号抗工频电磁干扰的能力,保证了控制系统的安全稳定运行。
3: BM100信号隔离器
BM100系列信号隔离器在工业生产中为增加仪表负载能力并保证连接同一信号的仪表之间互不干扰,提高电气安全性能。BM100信号隔离器将输入的电压、电流、电阻或温度等信号进行采集、放大、运算、并进行抗干扰处理后,再输出隔离的电流和电压信号,安全的输送给二次仪表或PLC/DCS使用。


图1 BM100系列信号隔离器外观图
3.1 技术参数
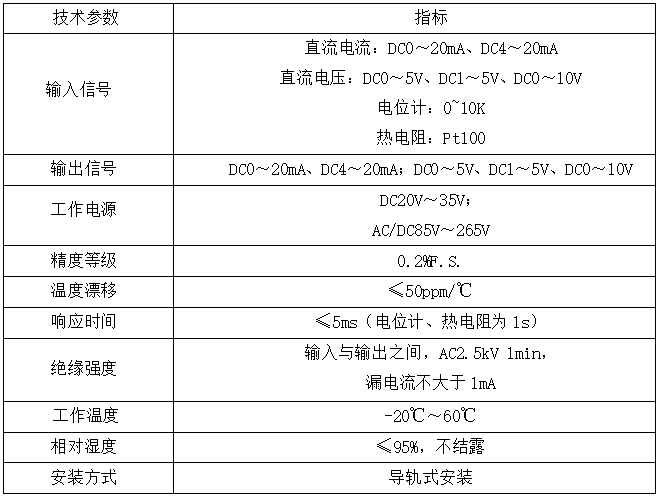
3.2 应用实例
某铜镍矿万吨镍冶炼技改扩建工程中,软化循环水泵房,变频器控制水泵用的是一台变频器控制两台水泵的控制原理,该变频器控制设置为三地控制,分别为:就地现场控制箱控制、集中变频器柜控制及远程中控室DCS控制。三地都能实现两台水泵的启停控制,但是变频器的电流显示及频率显示都无法工作正常,远程中控室的水泵电流与频率反馈也就无法工作。远程中控DCS控制水泵的频率给定与实际值也存在偏差,有时工作不能正常给定。起初怀疑电流表、频率表、信号线及流体介质有问题,更换了所有这些仪表、信号电缆,并把动力线与信号控制电缆分开走电缆桥架,故障依然存在。原因是变频器的高次谐波电流通过输出电缆向外辐射,传递到信号电缆,引起干扰。如图2所示。
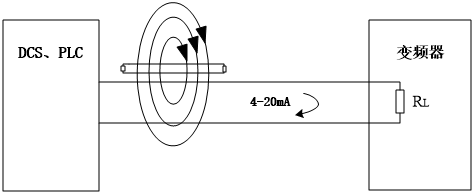
图2
解决办法:将变频器中电流反馈信号及频率反馈信号分别输入给信号隔离器,再把隔离输出信号分别输送给电流表、频率表及远程DCS控制室电流与频率反馈。远程中控室频率,给定信号也进入信号隔离器然后接至变频器。远程中控DCS控制频率输入信号、电流反馈、频率反馈、电流表及频率表显示正常,故障排除。如图3所示
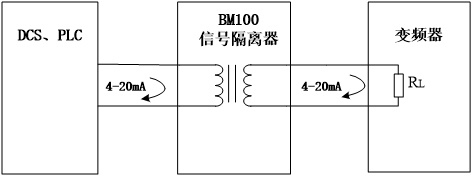
图3 信号隔离器应用示意图
4:结束语
在PLC/DCS控制系统中加入信号隔离器的连接方式,有效解决了控制系统中的干扰问题,目前在冶炼、水处理、化工、火电、工业自动化等多个行业已经批量应用 ,对提高PLC/DCS控制系统测量信号的精度和系统的安全稳定、可靠运行提供了保障。
参考文献
[1] 企业微电网设计与应用手册.2020.6.
[2] 张腾.变频器对PLC干扰常见故障的分析与处理[J].电子测试,2019(13):120-121.
[3] 张梦.基于系统干扰谈信号隔离器在工业现场的应用[J].世界仪表与自动化,2008,12(11):60-62.