网站群建设座谈会怎么用织梦修改建设一个新的网站
目录
一、实时嵌入式操作系统
1.1 概述
1.2 什么“实时”
1.3 什么是硬实时和软实时
1.4 什么是嵌入式
1.5 什么操作系统
二、常见重量级操作系统
三、常见轻量级嵌入式操作系统
3.1 概述
3.2 FreeRTOS
3.3 uC/OS-II
3.4 RT-Thread
3.5 RT-Thread、uC/OS-II、FreeRTOS 比较
3.6 RT-Thread、uC/OS-II和FreeRTOS应用场景比较
3.7 RT-Thread与Linux的比较
一、实时嵌入式操作系统
1.1 概述
实时嵌入式操作系统(Real-Time Embedded Operating System)是专门设计用于嵌入式系统的实时操作系统。嵌入式系统是一种特殊的计算机系统,通常是用于控制、监测或执行特定任务的系统。
实时嵌入式操作系统与传统的桌面操作系统相比,更注重对实时任务的响应和精确控制。
它们在资源利用、可靠性、可预测性、任务调度和中断处理等方面提供了更加严格的要求和机制。
实时嵌入式操作系统通常具有以下特点:
- 快速响应:实时嵌入式操作系统能够迅速响应外部事件或任务请求,以满足实时任务的时间要求。
- 稳定性和可靠性:实时嵌入式操作系统要求系统能够在各种环境条件下稳定可靠地运行,并在不可避免的故障情况下提供适当的错误处理机制。
- 硬实时和软实时支持:实时嵌入式操作系统通常提供对硬实时(Hard Real-Time)任务和软实时(Soft Real-Time)任务的支持。硬实时任务必须在严格的时间限制内完成,而软实时任务对时间限制更灵活。
- 任务调度和优先级:实时嵌入式操作系统通过任务调度器来管理和分配任务,通常采用优先级调度算法,确保高优先级的实时任务得到及时处理。
- 中断处理:实时嵌入式操作系统具备高效的中断处理机制,能够快速响应和处理系统的中断事件。
- 资源管理:实时嵌入式操作系统提供有效的资源管理机制,包括内存管理、设备驱动程序、文件系统和网络协议等,以支持嵌入式系统的功能需求。
- 低功耗和小尺寸:实时嵌入式操作系统通常要求运行时的资源占用较少,以适应嵌入式系统对功耗和尺寸的限制。
常见的实时嵌入式操作系统包括 FreeRTOS、ThreadX、Micrium μC/OS-II、VxWorks 和 QNX Neutrino 等,它们被广泛应用于汽车电子、工业自动化、医疗设备、消费电子和物联网等领域的嵌入式系统中。
1.2 什么“实时”
"实时"一词用于描述某种系统或过程具有立即或几乎立即响应的特性。它指的是在要求的时间范围内提供实时性能和反馈的能力。
在不同的领域中,实时可以有不同的定义和要求。
在计算机科学中,实时通常指的是一种计算机系统可以在特定时间范围内保证任务的响应和执行。实时系统将任务分为硬实时和软实时,硬实时任务必须严格按照预定的时间完成,而软实时任务对时间限制更灵活。
在通信领域中,实时通常表示传输和处理数据的实时性能,例如实时视频流的传输和播放。
在工业自动化中,实时可以指一个控制系统能够及时响应外部事件并采取相应的行动,如实时监测和调节温度、压力和速度等参数。
在金融领域中,实时可以指即时处理和更新市场数据、交易和报价。
总的来说,实时指的是在特定的时间要求下,系统能够以及时、准确和可靠的方式进行处理、响应和交互的能力。实时性要求的严格程度取决于具体的应用和领域。
1.3 什么是硬实时和软实时
硬实时(Hard Real-Time)和软实时(Soft Real-Time)是指在实时系统中任务完成时间的不同要求和保证级别。
硬实时是指系统中的任务必须在严格的时间限制内完成,不能有任何延迟。任务的延迟或错失时间限制可能会导致系统故障或严重的后果,如飞行控制系统或核电站控制系统。硬实时系统通常需要精确的任务调度和实时性能保证。
软实时是指系统中的任务有时间限制,但允许一定的延迟或错失任务时间限制。软实时任务对实时性能的要求相对较灵活,其中任务的延迟可能会降低系统性能但不会导致系统故障,如多媒体应用或实时数据分析。
区分硬实时和软实时的关键在于对任务执行时间的严格度和对时间限制的容忍度。硬实时任务的执行时间限制通常是固定的,任务必须在预定的时间范围内完成。而软实时任务的执行时间限制可能有一定的灵活性,并且容忍一定的延迟。
在实时系统设计中,需要根据具体应用的需求和系统的可靠性要求来确定任务是硬实时还是软实时。对于硬实时任务,需要使用特殊的调度算法和实时性能保证机制,以确保任务的及时响应和完成。而软实时任务可以使用普通的调度算法和时间片轮转等技术来满足大部分时间限制。
需要注意的是,硬实时和软实时是相对的概念,取决于特定的应用和系统要求。有些任务可能在一个系统中被定义为硬实时,而在另一个系统中可能被定义为软实时,取决于对时间限制的严格程度和对系统性能的要求。
1.4 什么是嵌入式
嵌入式系统指的是一种专门设计用于执行特定任务的计算机系统,通常被嵌入到其他设备或系统中的硬件和软件组合中。
嵌入式系统通常具有以下特点:
- 专用性:嵌入式系统是为特定的应用领域或特定任务而设计的,其功能和性能针对特定需求进行优化。
- 实时性:嵌入式系统通常需要及时响应外部事件或数据,以满足特定应用对时间要求的需求。
- 可靠性:嵌入式系统通常被用于在各种极端环境下工作,并要求稳定可靠地运行。
- 资源受限:嵌入式系统通常拥有有限的计算和存储资源,因为其设计需要适应特定的设备和成本预算。
- 实时约束:嵌入式系统通常有一系列的硬件和软件约束,例如功耗限制、尺寸限制和资源限制等。
常见的嵌入式系统包括但不限于以下领域:
- 汽车电子:如发动机控制、车载娱乐系统和驾驶辅助系统。
- 家电和消费电子:如智能手机、电视、家用电器和智能家居设备。
- 工业自动化:如工控系统、机器人和传感器网络。
- 医疗设备:如心脏监测器、血压计和假肢。
- 通信设备:如手机基站、网络路由器和调制解调器。
- 物联网(IoT)设备:如智能传感器、智能穿戴设备和智能城市系统。
嵌入式系统的设计和开发通常需要硬件、软件和固件的嵌入式开发技术,以确保系统的稳定性、可靠性和性能满足特定的应用需求。
1.5 什么操作系统
操作系统是计算机系统中的一种软件,它负责管理和协调计算机系统的各种硬件和软件资源,提供给应用程序和用户一个统一且方便的接口来操作和管理计算机系统。操作系统的主要功能包括:
- 进程管理:管理和调度计算机系统中的进程。它负责分配和回收处理器资源,控制进程的执行顺序和并发性,以及提供进程间通信和同步机制。
- 内存管理:管理计算机系统中的内存资源。它负责分配和回收内存空间,进行地址映射和内存保护,以及提供虚拟内存等功能。
- 文件系统:管理计算机系统中的文件和目录。它负责文件的存储和检索,提供文件的访问权限控制和数据安全等功能。
- 设备管理:管理计算机系统中的输入输出设备。它负责设备的驱动程序管理和输入输出的调度,以及提供设备的访问接口。
- 用户接口:提供给用户与计算机系统进行交互的界面。它可以是命令行界面、图形用户界面或者其他形式的用户界面。
常见的操作系统包括Windows、MacOS、Linux、iOS和Android等,它们适用于不同的硬件平台和应用场景。每个操作系统都有其特定的优点和适用范围,用户可以根据自己的需求选择合适的操作系统使用。
二、常见重量级操作系统
以下是一些常见的操作系统:
-
Windows:由微软公司开发的操作系统,广泛用于个人电脑和服务器环境。目前最新版本是Windows 11。
-
macOS:由苹果公司开发的操作系统,专门用于苹果的Mac电脑系列。它具有优秀的用户界面和稳定性,最新版本是macOS Monterey。
-
Linux:一种开源的操作系统内核,有许多不同的发行版,如Ubuntu、Debian、Fedora等。Linux广泛应用于服务器、嵌入式设备和个人电脑等各个领域。
-
Android:由Google开发的操作系统,主要应用于智能手机、平板电脑和其他移动设备。它是基于Linux内核的,目前占据着移动设备市场的主导地位。
-
iOS:由苹果公司开发的移动操作系统,运行在iPhone、iPad和iPod Touch等设备上。它具有良好的性能和安全性,以及与其他苹果设备的无缝集成。
-
Chrome OS:由Google开发的操作系统,主要用于Chromebook这类基于网页浏览器和云存储的设备。
-
鸿蒙 OS: 鸿蒙操作系统(HarmonyOS),又称鸿蒙OS,是华为公司自主研发的分布式操作系统。它是为应对物联网和多设备时代的挑战而设计的操作系统。
鸿蒙OS旨在实现全场景智慧互联,打破设备之间的界限,构建无缝协同的生态系统
这些操作系统在不同的设备和应用场景下发挥着重要的作用,并且各有特点和优势。用户可以根据自己的需求和偏好选择适合的操作系统。
三、常见轻量级嵌入式操作系统
3.1 概述
以下是一些常见的轻量级嵌入式操作系统:
-
FreeRTOS:一种开源的实时操作系统,特别适用于低功耗、资源有限的嵌入式系统。它提供了一套简单的任务管理、时间管理和通信机制。
-
ucOS:一种可裁剪的、可移植的实时操作系统。它支持多任务处理、互斥和信号量等特性,适用于各种嵌入式系统。
-
Zephyr:一种开源的实时操作系统,专为低功耗、支持多种处理器架构的嵌入式设备设计。它具有灵活的内核配置和易用的开发框架。
-
RT-Thread:一款开源的实时嵌入式操作系统,适用于资源有限的系统。它具有小巧、灵活的特点,支持多任务处理、时间管理和设备驱动。
-
NuttX:一种基于POSIX标准的开源实时操作系统,适用于嵌入式系统和各种控制器硬件平台。
这些轻量级嵌入式操作系统具有小巧、快速、高效和可裁剪的特点,适合在资源受限的嵌入式系统中使用。根据具体的应用场景和需求,可以选择适合的嵌入式操作系统进行开发和部署。
3.2 FreeRTOS
FreeRTOS(Free Real-Time Operating System)是一款流行的开源实时操作系统,旨在为嵌入式系统提供实时性能和可靠性。下面是一些关于FreeRTOS的重要特点:
-
实时性能:FreeRTOS支持实时任务调度,可以满足对实时性要求较高的应用场景。它使用轻量级的抢占式调度算法,并提供多种调度策略供选择。
-
多任务处理:FreeRTOS支持多任务处理,可以在单个设备上同时运行多个任务。它通过任务管理器和任务优先级来安排任务的执行。
-
内存管理:FreeRTOS提供灵活的内存管理功能,可以依据具体需求配置内存分配算法,包括固定大小的内存块分配和动态内存分配。
-
任务通信与同步:FreeRTOS提供了多种机制来实现任务之间的通信与同步,包括消息队列、信号量、互斥锁和事件标志等。这些机制使得不同任务能够安全地共享资源和进行协作。
-
硬件支持:FreeRTOS可在多种处理器架构和嵌入式设备上运行,包括ARM、MIPS、RISC-V和X86等,并提供了针对不同处理器的硬件抽象层。
-
可扩展性:FreeRTOS具有模块化的设计,可以根据需求选择不同的内核组件和功能模块,从而灵活构建适合特定应用的嵌入式系统。
FreeRTOS作为一款轻量级的嵌入式实时操作系统,已经广泛应用于各种领域,包括物联网、工业自动化、消费电子和汽车电子等。它具有易用性、可移植性和可裁剪性等优势,为嵌入式系统开发者提供了强大的工具和框架。
3.3 uC/OS-II
uC/OS-II是一款开源的实时操作系统,为嵌入式系统提供了可靠且可裁剪的操作系统解决方案。以下是关于uC/OS-II的一些重要特点:
-
实时性能:uC/OS-II的设计目标是提供可预测的实时性能。它使用优先级和时间片轮转的调度算法,能够满足实时系统对任务响应时间的要求。
-
多任务处理:uC/OS-II支持多任务处理,可以在单个设备上同时运行多个任务。任务间的切换和调度是基于优先级的,具备抢占式和非抢占式两种任务调度模式。
-
任务通信与同步:uC/OS-II提供多种机制来实现任务之间的通信与同步,包括信号量、互斥锁、消息邮箱和消息队列等。这些机制使得任务能够合作共享资源,并进行可靠的同步操作。
-
内存管理:uC/OS-II具备灵活的内存管理功能,支持两种内存分配策略:固定大小的内存块分配和动态内存分配。可以根据实际需求配置和优化内存使用。
-
中断处理:uC/OS-II提供可靠的中断处理机制,具备中断屏蔽和中断优先级处理的功能。可通过中断处理机制实现与外部设备的高效交互。
-
可移植性:uC/OS-II是可移植的操作系统,可以适配不同的微处理器架构和开发环境。已经在多种处理器架构和嵌入式平台上成功应用。
-
低开销:uC/OS-II具有相对较低的内核开销,适用于资源有限的嵌入式系统。它的内核代码非常精简,运行效率高。
由于其可靠性、实时性和可裁剪性等特点,uC/OS-II已经广泛应用于嵌入式系统领域,包括工控系统、通信设备、医疗设备等。开发者可以根据具体需求和系统资源配置uC/OS-II,实现高效可靠的嵌入式应用程序。
3.4 RT-Thread
RT-Thread 是一款主要由中国开源社区主导开发的开源实时操作系统(v3.1.0以及以前版本遵循GPLv2+许可协议,v3.1.0以后版本遵循 Apache License 2.0 开源许可协议)。实时线程操作系统不仅仅是一个单一的实时操作系统内核,它也是一个完整的应用系统,包含了实时、嵌入式系统相关的各个组件:TCP/IP协议栈,libc接口,图形用户界面等。
RT-Thread(Real-Time Thread)是一款开源的实时操作系统,专为嵌入式系统和物联网设备设计。以下是关于RT-Thread的一些重要特点:
-
实时性能:RT-Thread具有快速的上下文切换和低延迟的特性,以满足实时系统对任务响应时间的要求。它采用抢占式调度算法,支持多优先级任务调度。
-
多任务处理:RT-Thread支持多任务处理,可以在单个设备上同时运行多个任务。它提供了灵活的任务管理机制,包括任务创建、删除、挂起和恢复等。
-
组件化设计:RT-Thread采用组件化的设计理念,可以选择性地加载和配置各种功能组件,以满足特定应用的需求。它提供了丰富的组件库,包括文件系统、网络协议栈、设备驱动、通信协议等。
-
轻量级和高效性能:RT-Thread的内核代码非常精简,运行效率高。它采用了很多优化措施,包括内存池管理、对象池管理和线程本地存储等,以提高系统的效率和资源利用率。
-
设备驱动支持:RT-Thread提供了支持多种设备驱动的机制,包括GPIO、UART、SPI、I2C、USB等。它具有简单易用的驱动层和设备模型,能够方便地与各种硬件进行交互。
-
开放源代码和丰富的社区支持:RT-Thread是一款开源的操作系统,具有活跃的开发社区和丰富的开发资源。用户可以获取开源代码、参与社区讨论、分享经验和获取技术支持。
由于其灵活性、高效性和可裁剪性等特点,RT-Thread已经广泛应用于物联网、智能家居、工业自动化和消费电子等领域。开发者可以通过配置和定制RT-Thread,实现高度定制化和可靠性的嵌入式应用程序。
3.5 RT-Thread、uC/OS-II、FreeRTOS 比较
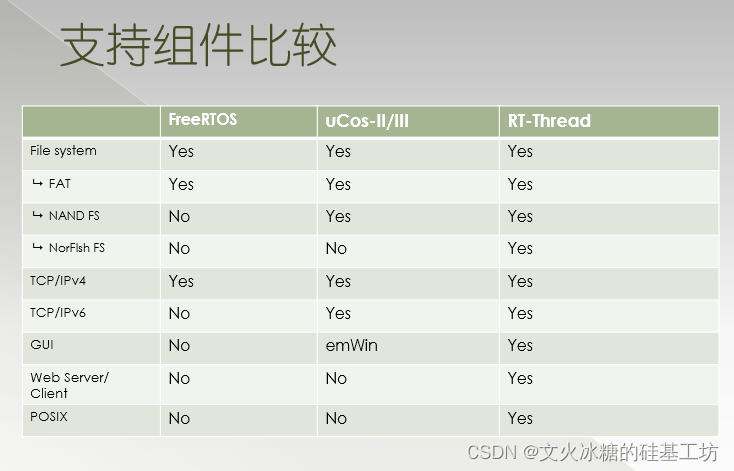
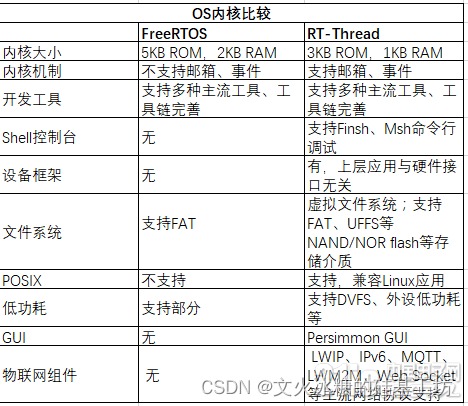
T-Thread、uC/OS-II和FreeRTOS都是流行的实时操作系统,适用于嵌入式系统开发。
以下是它们之间的一些比较:
-
开源性:RT-Thread、FreeRTOS和uC/OS-II都是开源的操作系统。开源性意味着开发者可以自由查看、修改和分发源代码,因此具有更大的灵活性和可定制性。
-
架构和内核:RT-Thread和FreeRTOS都是单内核的操作系统,而uC/OS-II使用的是可抢占式内核。单内核意味着任务之间的切换速度更快,但可能会牺牲一些实时性;可抢占式内核提供更高的实时性能。
-
社区支持和生态系统:FreeRTOS拥有非常活跃和庞大的社区支持,具有丰富的开发文档、示例代码和第三方扩展。RT-Thread也具有活跃的社区,但相对较小。在生态系统的丰富程度上,FreeRTOS略胜一筹。
-
功能和扩展性:三个操作系统都提供了基本的实时任务调度、任务通信与同步机制。然而,FreeRTOS和RT-Thread更加注重扩展性,提供了丰富的组件库和功能扩展选项,如文件系统、网络协议栈和设备驱动等,可以根据应用需求进行定制。
-
内存和性能:RT-Thread在内存使用方面相对较高,因为它提供了更多的功能和扩展性。FreeRTOS和uC/OS-II的内存占用相对较低,适用于资源有限的嵌入式系统。在性能方面,三者的具体表现可能因应用场景和配置不同而有所差异。
最终选择哪个实时操作系统应基于具体应用需求、开发经验和资源限制进行评估。可以根据实时性能需求、功能要求、可移植性、社区支持和可扩展性等因素进行权衡和选择。
下面是关于RT-Thread、uC/OS-II和FreeRTOS的全方位比较:
-
开源性和授权:RT-Thread、uC/OS-II和FreeRTOS都是开源操作系统,可以自由访问、使用和修改源代码。然而,它们的授权策略略有不同,RT-Thread采用Apache License 2.0许可证,uC/OS-II采用Proprietary许可证,而FreeRTOS则使用MIT许可证。
-
架构和内核:RT-Thread、uC/OS-II和FreeRTOS在架构和内核设计上存在差异。RT-Thread是一个多线程操作系统,支持多任务并发执行,具有轻量级的内核设计。uC/OS-II是一个可抢占式的实时内核操作系统,支持任务优先级和时钟节拍,具有相对较低的内存和运行开销。FreeRTOS也是一个可抢占的实时内核操作系统,具有低延迟和高可靠性。
-
功能和可扩展性:RT-Thread、uC/OS-II和FreeRTOS都提供了基本的实时任务调度和同步机制,如任务管理、消息队列、信号量和互斥锁等。但在功能丰富性和可扩展性上略有差异。RT-Thread具有灵活的组件化设计,可以选择性地加载和配置功能模块,提供了丰富的组件库和可选的文件系统、网络协议栈等扩展。uC/OS-II提供了较为简化的功能集,适用于资源受限的系统。FreeRTOS也具备一定的可扩展性,提供了一些额外的可选组件和特性。
-
资源占用和性能:RT-Thread、uC/OS-II和FreeRTOS在资源占用和性能方面也有所不同。RT-Thread的内存占用相对较高,适合中等到高端的嵌入式系统;uC/OS-II具有较低的内存和运行开销,适合资源有限的系统;FreeRTOS有较低的内存占用,并提供了针对不同处理器架构的优化版本。
-
社区支持和文档资源:FreeRTOS拥有庞大的活跃社区,提供了大量的开发文档、示例代码和第三方扩展,易于获取帮助和资源。RT-Thread也有活跃的社区,但规模相对较小。uC/OS-II的社区支持相对较少,文档和示例资源相对较少。
-
移植性和支持平台:RT-Thread、uC/OS-II和FreeRTOS都具有高度的移植性,可支持多种处理器架构和开发平台。它们提供了硬件抽象层和移植层,可以在不同平台上进行移植和适配。
最终选择合适的实时操作系统应该基于应用需求、开发经验、资源限制和个人偏好进行评估。建议在项目前仔细研究和比较这些操作系统的功能、性能、支持和文档资源,以选择最符合项目需求的操作系统。
3.6 RT-Thread、uC/OS-II和FreeRTOS应用场景比较
RT-Thread、uC/OS-II和FreeRTOS都可以用于嵌入式系统开发,但它们在应用场景上存在一些差异。以下是它们的应用场景比较:
-
RT-Thread:
- RT-Thread适用于中等到高端的嵌入式系统,特别是那些需要丰富功能和可扩展性的应用。
- RT-Thread提供了灵活的组件化设计,可以根据具体需求自由加载和配置功能模块。
- 它支持动态组件加载和热插拔,以及多线程并发执行。
- RT-Thread具有较高的实时性能和响应性,适用于对实时性要求较高的应用。
-
uC/OS-II:
- uC/OS-II适用于资源有限的嵌入式系统,特别是那些对实时性要求较高且轻量级的应用。
- uC/OS-II具有较低的内存和运行开销,适合小型的嵌入式系统。
- 它提供了可抢占式内核,支持任务优先级和时钟节拍。
- uC/OS-II在实时性能和响应性方面表现良好,适用于时间敏感的应用。
-
FreeRTOS:
- FreeRTOS适用于广泛的嵌入式应用,从低端、资源受限的系统到高端、功能丰富的系统。
- 它具有较低的内存占用和高度可移植性,可适配多种处理器架构和开发平台。
- FreeRTOS提供了丰富的组件库和可选功能模块,如文件系统、网络协议栈和设备驱动等。
- 它有一个庞大的社区支持,提供了丰富的文档、示例代码和第三方扩展。
综上所述,选择适合的操作系统应基于应用需求、资源限制和个人偏好进行评估。对于需要丰富功能和可扩展性的中等到高端系统,可以考虑使用RT-Thread;对于资源有限且对实时性要求较高的系统,可以选择uC/OS-II;而对于广泛的应用场景以及较高的可移植性需求,FreeRTOS是一个不错的选择。
3.7 RT-Thread与Linux的比较
RT-Thread与Linux是两个不同类型的操作系统,它们在设计和应用上有一些显著的差异。以下是RT-Thread与Linux的比较:

-
设计理念和内核结构:
- RT-Thread是一个实时多任务操作系统,专注于实时性和响应性能,针对嵌入式系统设计,具有轻量级内核。
- Linux是一个通用性的操作系统,注重功能丰富性和可扩展性,采用复杂的内核机制,较为庞大。
-
实时性和响应性:
- RT-Thread专注于实时性,具有较快的任务切换和响应时间,适用于对实时性要求较高的应用场景。
- Linux并非严格实时操作系统,它的实时性和响应性相对较低,适用于一般的桌面和服务器环境。
-
内存占用和系统开销:
- RT-Thread相比Linux具有较小的内存占用和系统开销,适合资源有限的嵌入式系统。
- Linux则需要较大的内存以及更高的处理器性能,适用于资源充足的系统。
-
功能和生态系统支持:
- Linux在功能和扩展性方面具有强大的优势,拥有广泛的应用和丰富的开发工具、库和驱动支持。
- RT-Thread也提供了一些基本的功能模块,同时支持组件化设计,但相对于Linux来说,其功能和生态系统支持较为有限。
-
开发成本和学习曲线:
- 由于RT-Thread的轻量级设计和简单性,相对较易于学习和上手,并且能够更好地满足小型嵌入式应用的需求。
- Linux则具有更大的学习曲线和开发成本,并且需要更多的硬件资源和处理能力。
最终选择RT-Thread还是Linux应该根据具体的应用需求、资源限制和开发经验来评估。如果应用对实时性要求较高、资源有限,而且在功能和生态系统支持方面要求相对简单,那么RT-Thread可能是一个更适合的选择。如果应用需要丰富的功能和扩展性,并且对实时性要求不是很高,同时有较高的硬件资源和处理能力,那么Linux可能是更合适的选择。