商城网站建设资讯wordpress 微信分享
什么是 Kubernetes ?
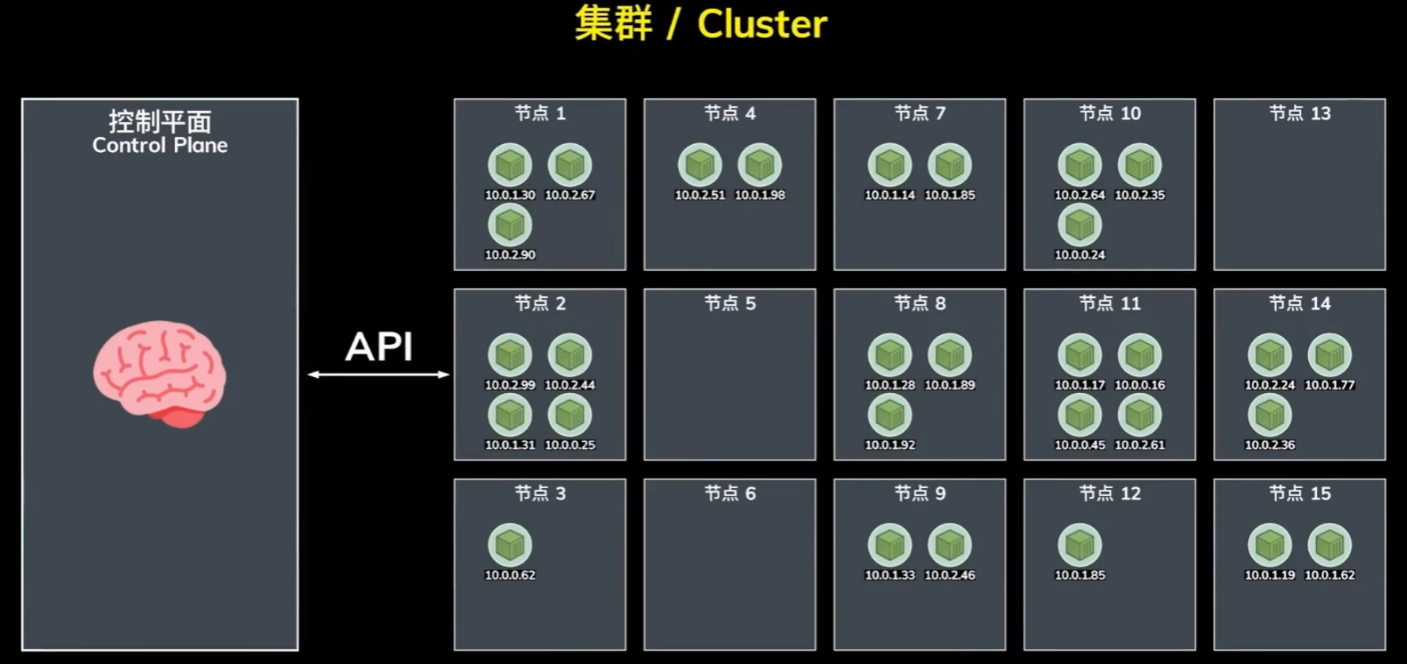
Kubernetes 是一个开源容器编排平台,管理着一系列的 主机 或者 服务器,它们被称作是 节点(Node)。

每一个节点运行了若干个相互独立的 Pod。

Pod 是 Kubernetes 中可以部署的 最小执行单元,说白了它就是 一个或者多个容器的集合。其中运行了我们应用的某一部分核心组件,比如数据库、Web 服务器等等。
但这么多 Pod,它们需要相互协调才能做到负载均衡或者故障的转移。这就需要一台中心计算机来集中管理,这个中心计算机被称作 控制平面(Control Plane)。
控制平面通过专有的 API 与各个节点进行通信,它会实时监测节点的网络状态来平衡服务器的负载,或者临时下发指令来应对突发的状况。

比如 Kubernetes 发现某个容器或者 Pod 挂掉了,它会立刻启用在后台预先准备好的、随时待命的备用容器来替换它。


这些容器被称作 副本集合(Replica Set)。
而以上讲到的所有节点,连同控制平面,一起被称作一个 集群(Cluster)。集群代表了 Kubernetes 所管理的全部主机节点。