如何学习网页设计网页广告优化师招聘
作者:yx
文章目录
- 一、发布服务
- 二、代码加载
- 三、结果展示
一、发布服务
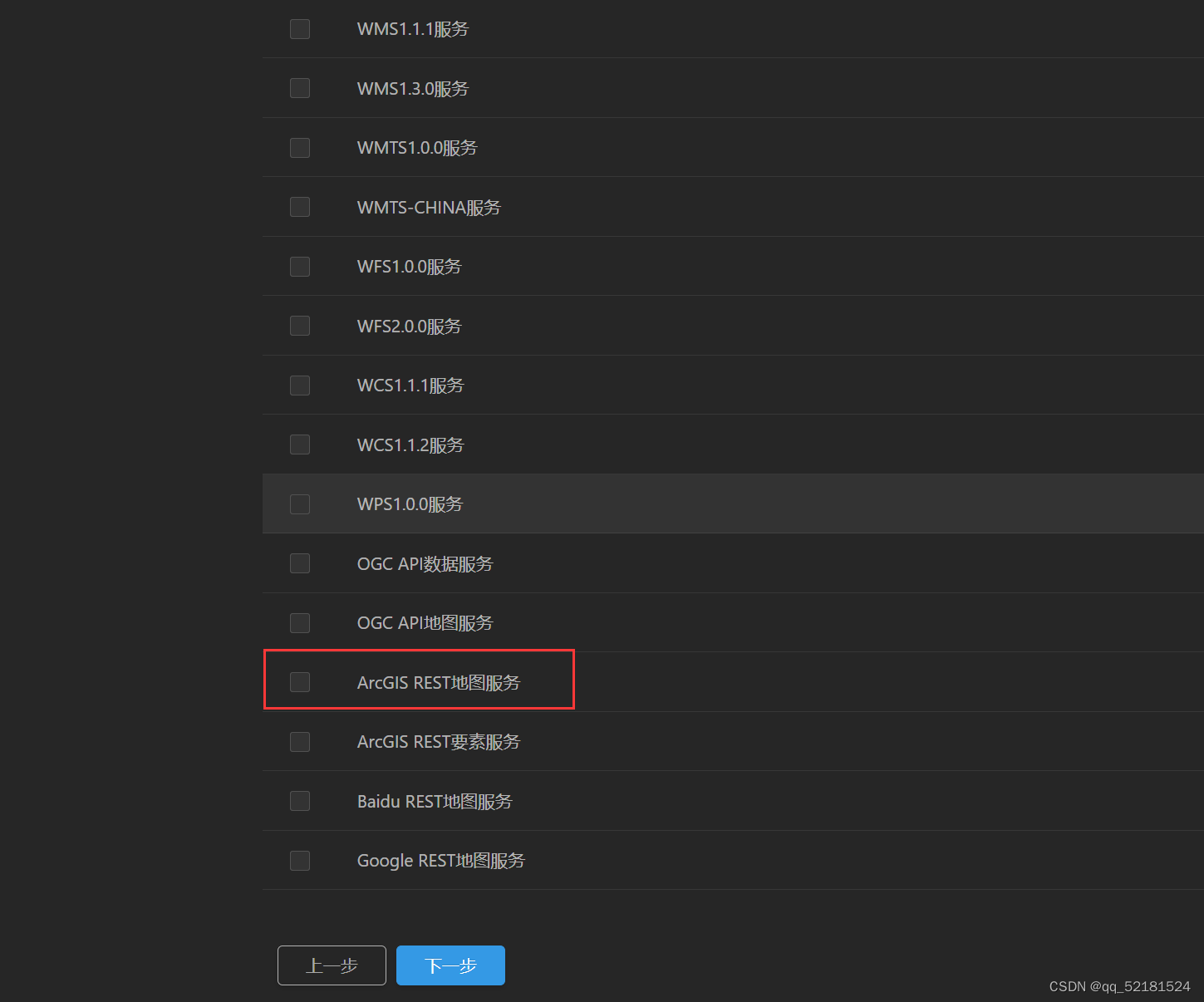
SuperMap iServer支持将地图发布为ArcGIS REST地图服务,您可以在发布服务时直接勾选ArcGIS REST地图服务,如下图所示:
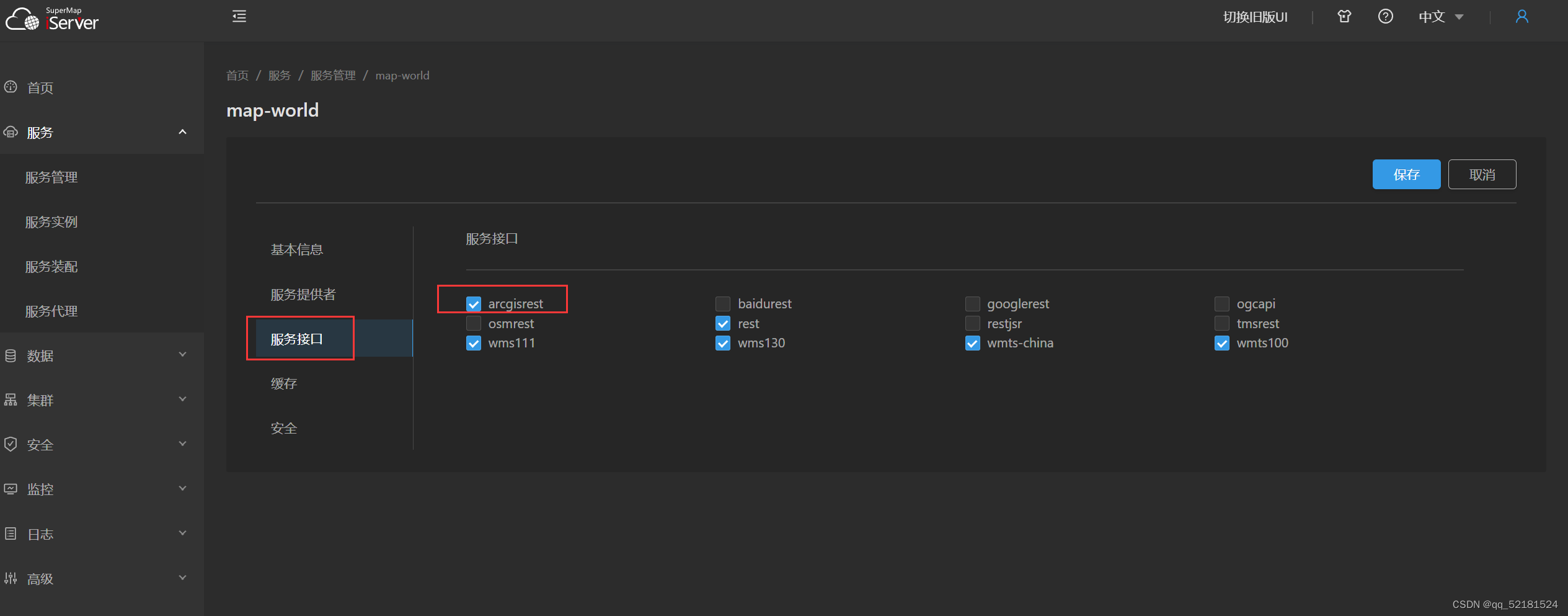
也可以在已发布的地图服务中,找到对应服务的服务接口,勾选上“arcgisrest”即可,如图所示:
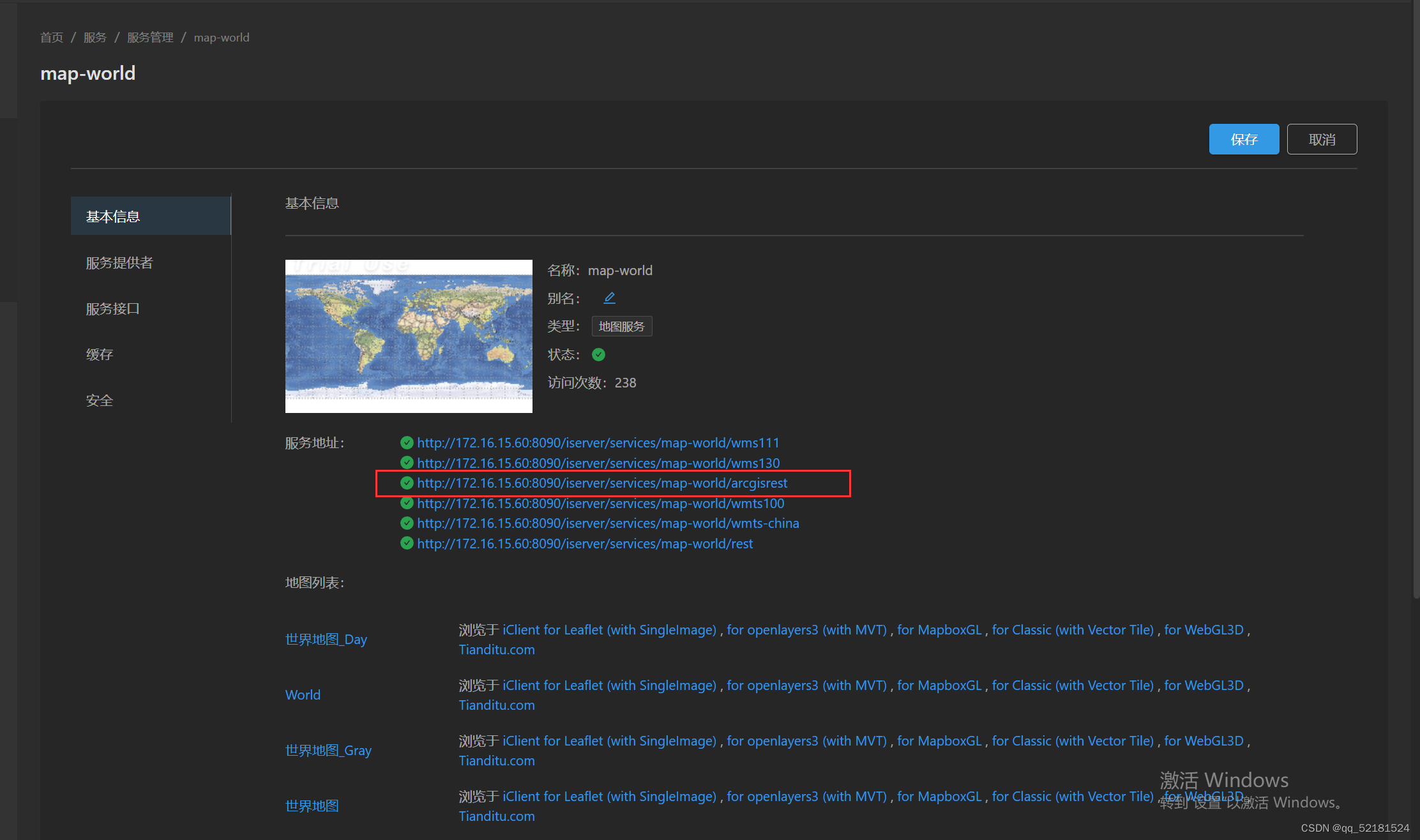
发布后服务地址那里就已经生成ArcGIS REST地图服务对应地址,如图所示:
二、代码加载
利用ArcGIS API for JavaScript加载该服务:
<html>
<head><meta charset="utf-8"/><meta name="viewport" content="initial-scale=1, maximum-scale=1, user-scalable=no"/><title>ArcGIS Maps SDK for JavaScript Tutorials: Display a map</title><style>html,body,#viewDiv {padding: 0;margin: 0;height: 100%;width: 100%;}</style><link rel="stylesheet" href="https://js.arcgis.com/4.15/esri/themes/light/main.css"><script src="https://js.arcgis.com/4.15/"></script>
</head>
<body>
<div id="viewDiv"></div>
<script>require(["esri/Map","esri/views/MapView","esri/layers/TileLayer","esri/layers/MapImageLayer","esri/Basemap","esri/geometry/Extent"], (Map, MapView, TileLayer, MapImageLayer, Basemap, Extent) => {var layer = new MapImageLayer({// 数据用iServer发布ArcGIS地图服务url: "http://localhost:8090/iserver/services/map-world/arcgisrest/World/MapServer",});const basemap = new Basemap({baseLayers: [layer],})//创建一个地图对象var map = new Map({basemap: basemap,// layers: [layer],crs: 'CRS_4326'});//创建一个地图视图var view = new MapView({container: "viewDiv",map: map,center: [120.409438798999, 36.4273578787959], // 经纬坐标zoom: 10,});});
</script>
</body>
</html>
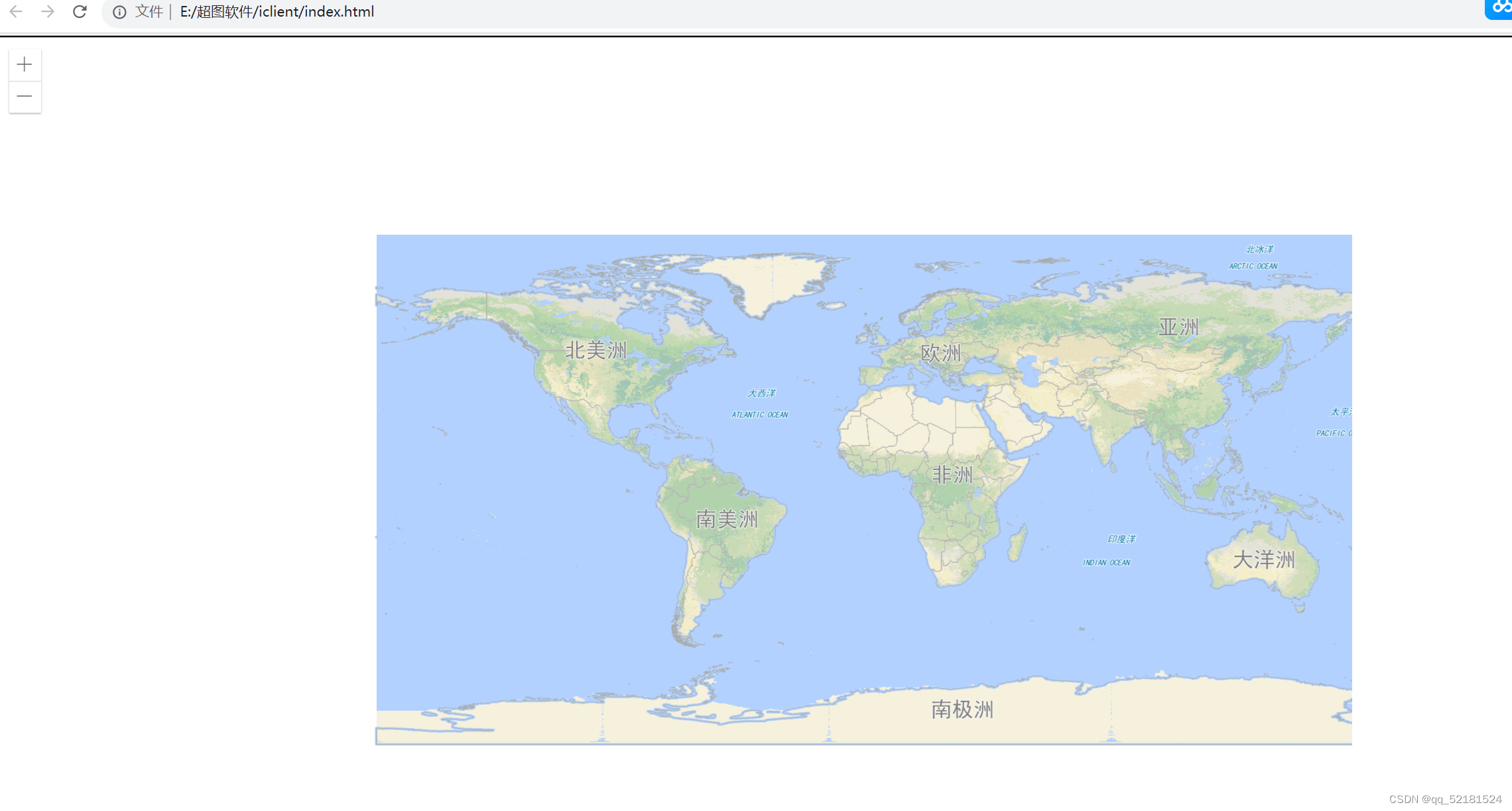
三、结果展示