舒城县建设局官方网站河源市建设厅网站
一.Ajax入门
概念:AJAX是浏览器与服务器进行数据通信的技术
axios使用:
- 引入axios.js
- 使用axios函数:传入配置对象,再用.then回调函数接受结果,并做后续处理
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title>01.axios使用</title></head><body><p class="my-p"></p><script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script><script>axios({url:'https://hmajax.itheima.net/api/province'}).then(result=>{console.log(result)console.log(result.data.list)console.log(result.data.list.join('<br>'))//把准备好的省份列表,插入到页面document.querySelector('.my-p').innerHTML = result.data.list.join('<br>')})</script></body>
</html>二.URL
1.概念
概念:统一资源定位符,简称网址,用于访问网络上的资源

- http协议:超文本传输协议,规定浏览器和服务器之间传输数据的格式
- 域名:标记服务器在互联网中方位
- 资源路径:标记资源在服务器下的具体位置

2.URL查询参数
定义:浏览器提供给服务器的额外信息,让服务器返回浏览器想要的数据
![]()
3.axios-查询参数
语法:使用axios提供的params选项
注意:axios在运行时把参数名和值,会拼接到url?参数名=值
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title>03.查询参数</title></head><body><p></p><script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script><script>axios({url: 'https://hmajax.itheima.net/api/city',//查询参数params: {pname: '辽宁省'}}).then(result => {console.log(result.data.list)document.querySelector('p').innerHTML = result.data.list.join('<br>')})</script></body>
</html>三.案例_地区查询
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>04.案例_地区查询</title><link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/css/bootstrap.min.css"><style>:root {font-size: 15px;}body {padding-top: 15px;}</style>
</head><body><div class="container"><form id="editForm" class="row"><!-- 输入省份名字 --><div class="mb-3 col"><label class="form-label">省份名字</label><input type="text" value="北京" name="province" class="form-control province" placeholder="请输入省份名称" /></div><!-- 输入城市名字 --><div class="mb-3 col"><label class="form-label">城市名字</label><input type="text" value="北京市" name="city" class="form-control city" placeholder="请输入城市名称" /></div></form><button type="button" class="btn btn-primary sel-btn">查询</button><br><br><p>地区列表: </p><ul class="list-group"><!-- 示例地区 --><li class="list-group-item">东城区</li></ul></div><script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script><script>/*获取地区列表: http://hmajax.itheima.net/api/area查询参数:pname: 省份或直辖市名字cname: 城市名字*///目标:根据省份和城市名字,查询地区列表//1.查询按钮-点击事件document.querySelector('.sel-btn').addEventListener('click',() =>{//2.获取省份和城市名字let pName = document.querySelector('.province').valuelet cName = document.querySelector('.city').value//3.基于axios请求地区列表数据axios({url:'http://hmajax.itheima.net/api/area',params:{pname: pName,cname: cName}}).then(result =>{//console.log(result)//4.把数据转成li标签插入到页面上let list = result.data.listconsole.log(list)let theLi = list.map(areaName => `<li class="list-group-item">${areaName}</li>`).join('')console.log(theLi)document.querySelector('.list-group').innerHTML = theLi})})</script>
</body></html>注意:let theLi = list.map(areaName => `<li class="list-group-item">${areaName}</li>`).join('')
这段代码中用的是反引号
反引号(`)是用于创建模板字符串的特殊字符
四.常用请求方法和数据提交
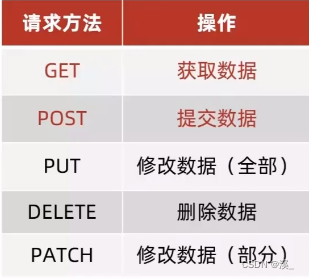
1.请求方法
请求方法:对服务器资源,要执行的操作
2. axios请求配置
- url:请求的URL网址
- method:请求的方法,GET可以省略(不区分大小写)
- data:提交数据
3.数据提交-注册账号
需求:通过axios提交用户名和密码,完成注册功能
请求方法:POST
参数名:
username用户名(中英文和数字组成,最少8位)
password密码(最少6位)
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>05.常用请求方法和数据提交</title>
</head><body><button class="btn">注册用户</button><script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script><script>/*注册用户: http://hmajax.itheima.net/api/register请求方法: POST参数名:username: 用户名 (中英文和数字组成, 最少8位)password: 密码 (最少6位)目标: 点击按钮, 通过axios提交用户和密码, 完成注册*/document.querySelector('.btn').addEventListener('click',() => {axios({url: 'http://hmajax.itheima.net/api/register',//指定请求方法method:'post',//提交数据data:{username:'itheima777',password:'123456'}}).then(result =>{console.log(result)})})</script>
</body></html>注意:数据提交之后服务器上就已经存在了,再次运行会报错
五.axios错误处理
场景:在上面的案例中再次注册相同的账号,会遇到报错信息
处理:用更直观的方式,给普通用户展示错误信息
注册案例,重复注册时通过弹框提示用户错误原因
语法:在then方法的后面,通过点语法调用catch方法,传入回调函数并定义形参
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>05.常用请求方法和数据提交</title>
</head><body><button class="btn">注册用户</button><script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script><script>/*注册用户: http://hmajax.itheima.net/api/register请求方法: POST参数名:username: 用户名 (中英文和数字组成, 最少8位)password: 密码 (最少6位)目标: 点击按钮, 通过axios提交用户和密码, 完成注册需求:使用axios错误处理语法,拿到报错信息,弹框反馈给用户*/document.querySelector('.btn').addEventListener('click',() => {axios({url: 'http://hmajax.itheima.net/api/register',//指定请求方法method:'post',//提交数据data:{username:'itheima777',password:'123456'}}).then(result =>{//成功console.log(result)}).catch(error =>{//失败//处理错误信息console.log(error)console.log(error.response.data.messag)alert(error.response.data.message)})})</script>
</body></html>六.HTTP协议-请求报文
HTTP协议:规定了浏览器发送及服务器返回内容的格式
请求报文:浏览器按照HTTP协议要求的格式,发送给服务器的内容
1.请求报文的格式
请求报文的组成部分有:
- 请求行:请求方法,URL,协议
- 请求头:以键值对的格式携带的附加信息,比如:Content-Type
- 空行:分隔请求头,空行之后的是发送服务器的资源
- 请求体:发送的资源
2.请求报文-错误排查
七.HTTP协议-响应报文
响应报文:服务器按照HTTP协议要求的格式,返回给浏览器的内容
- 响应行(状态行):协议,HTTP响应状态码,状态信息
- 响应头:以键值对的格式携带的附加信息,比如: Content-Type
- 空行:分隔响应头,空行之后是服务器返回的资源
- 响应体:返回的资源
HTTP响应状态码:用来表明请求是否成功完成
比如:404(服务器找不到资源)
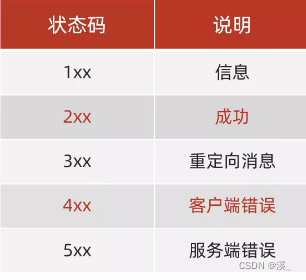
八.接口文档
接口文档:由后端提供的描述接口的文章
接口:使用AJAX和服务器通讯时,使用的URL,请求方法,以及参数
九.form-serialize插件
作用:快速收集表单元素的值
语法:

使用serialize函数,快速收集表单元素的值
参数1:要获取哪个表单的数据
- 表单元素设置name属性,值会作为对象的属性名
- 建议name属性的值,最好和接口文档参数名一致
参数2:配置对象
hash 设置获取数据结构
- - true:JS对象(推荐)一般请求体里提交给服务器
- - false: 查询字符串
empty 设置是否获取空值
- - true: 获取空值(推荐)数据结构和标签结构一致
- - false:不获取空值