网站html动态效果代码百度网页版在线使用
目录
1 娇滴滴的她
2 Python代码实现
1 娇滴滴的她

娇滴滴。双眉敛破春山色。春山色。为君含笑,为君愁蹙。多情别後无消息。
此时更有谁知得。谁知得。夜深无寐,度江横笛。
2 Python代码实现
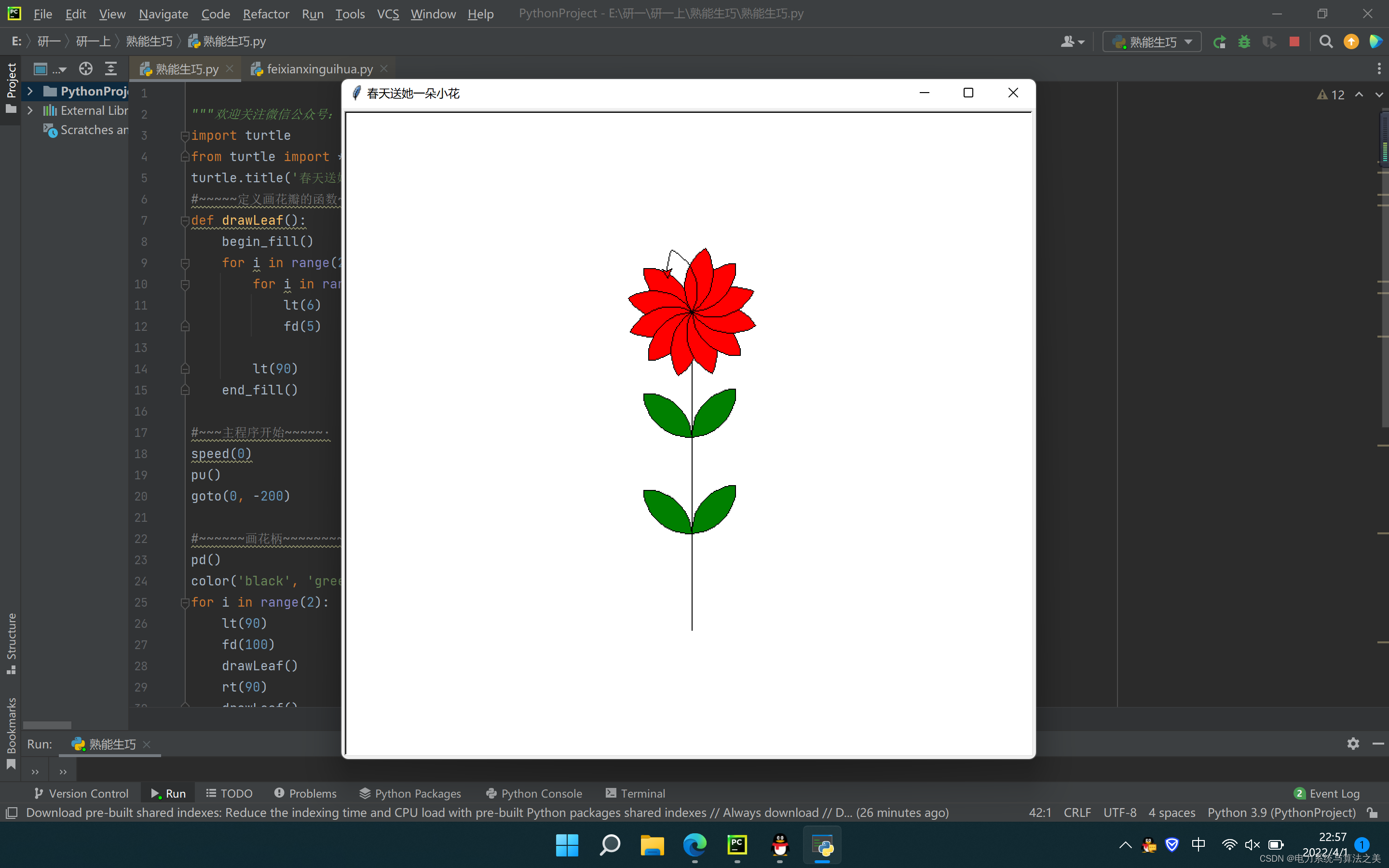
import turtle
from turtle import *
turtle.title('春天送她一朵小花')
#~~~~~定义画花瓣的函数~~~~~~~·
def drawLeaf():begin_fill()for i in range(2):for i in range(15):lt(6)fd(5)lt(90)end_fill()#~~~主程序开始~~~~~·
speed(0)
pu()
goto(0, -200)#~~~~~~画花柄~~~~~~~~~~~·
pd()
color('black', 'green')
for i in range(2):lt(90)fd(100)drawLeaf()rt(90)drawLeaf()#~~~画花朵~~~~~
lt(90)
fd(130)
color('black', 'red')
for i in range(12):drawLeaf()lt(360 / 12)#~~~画花心的圆圈~~~~
pu()
ls(90)
fd(-10)
rt(90)
pd()
color('black', 'yellow')
begin_fill()
circle(10)
end_fill()
hideturtle()import turtle
from turtle import *
turtle.title('春天送她一朵小花')
#~~~~~定义画花瓣的函数~~~~~~~·
def drawLeaf():
begin_fill()
for i in range(2):
for i in range(15):
lt(6)
fd(5)
lt(90)
end_fill()
#~~~主程序开始~~~~~·
speed(0)
pu()
goto(0, -200)
#~~~~~~画花柄~~~~~~~~~~~·
pd()
color('black', 'green')
for i in range(2):
lt(90)
fd(100)
drawLeaf()
rt(90)
drawLeaf()
#~~~画花朵~~~~~
lt(90)
fd(130)
color('black', 'red')
for i in range(12):
drawLeaf()
lt(360 / 12)
#~~~画花心的圆圈~~~~
pu()
ls(90)
fd(-10)
rt(90)
pd()
color('black', 'yellow')
begin_fill()
circle(10)
end_fill()
hideturtle()