制作类似网站软件怎么提高网站建设水平
文章目录
- ModelScope介绍
- 垂类模型介绍
- 调用方式
- 1 Demo Service
- 2 Notebook
- 3 本地使用
- * 二次开发
- 总结
ModelScope介绍
ModelScope 是阿里达摩院推出的 中文版模型即服务(MaaS, Model as a Service)共享平台。该平台在2022年的云栖大会上发布,之前也有大量的PR文章进行介绍和推广(如:官方介绍,CSDN文章 等),这里就不再赘述。
作为其中的一个贡献者,刚开始接触ModelScope,给我的第一感觉就是,这不就是一个中文版的Hugging Face 嘛,还有必要再搞一个这个东西吗?我从心理是抗拒的。但是后(gong)来(zuo)想(suo)想(po),之前的淘宝,QQ,百度等,也是效仿而来,虽然不像ChatGPT, AlphaGo这样的开创性工作一样令人震撼,但至少也是针对国内使用者做了一些改良。当然,我从心底里佩服能够做出ChatGPT, AlphaGo这样工作的人,也希望国内能有一些这样重量级的工作出现。
话说回来,仔细想想,ModelScope相比Hugging Face做了哪些适合“国情”的改良呢?我能够想到的有下面几点:
- 首先是中文,虽然说对于专业的开发者,查找和阅读英文文档是一个必备的技能,但是有一个中文的平台作为参考和对比,当然也没什么坏处,另外,在AI这个领域,还有还有大量的初级入门者和非专业的开发者,这样的中文平台对他们而言更加友好;
- 其次是模型种类,Hugging Face本身是从NLP的Transformer“发家”,一些做CV的朋友甚至都不知道它的存在。而ModelScope除了在NLP,在CV, Audio, Multimodal等领域也有不少的模型,没有对NLP明显的侧重;
- 再者是机器资源,目前处在推广阶段,每位开发者都可以使用阿里云上免费的CPU/GPU机器进行开发,可以从每个模型主页右上角的Notebook选项中进入,是薅羊毛的不二之选;
- 最后是网络流畅度,相比Hugging Face,ModelScope在网页浏览、模型下载、数据集下载等方面,显然是更加顺畅的。
ModelScope也存在一些明显的不足:
- 贡献者欠缺,作为一个社区,当然需要更多开发者的贡献,虽然目前也有一些生态伙伴在上面进行模型贡献,但是大部分的模型还是达摩院自研/搬运的模型,如何能够使开源者在github开源的同时也上线到ModelScope,是一个值得考虑的问题;
- 模型影响力欠缺,作为一个中文的模型即服务平台,ModelScope上还欠缺有影响力的模型,很多国内的优秀工作也没有上线到这里;
- 代码一致性保障困难,ModelScope是一个“all in one”的仓库,内部和外部的人均能贡献,同一领域的代码风格统一以及模型结构复用等都是很有挑战的。
垂类模型介绍
我们在ModelScope上贡献的垂类模型(垂直领域的热门检测模型)包括:人体部位(人体、人手、人头)和垂类物体(口罩、安全帽、香烟、手机、交通标识等)检测模型,从某种程度上来说,也算是和Hugging Face的一个差异点(Hugging Face 物体检测相关的模型更多是通用的物体检测模型,没有垂类模型)。垂类模型的入口如下图所示:
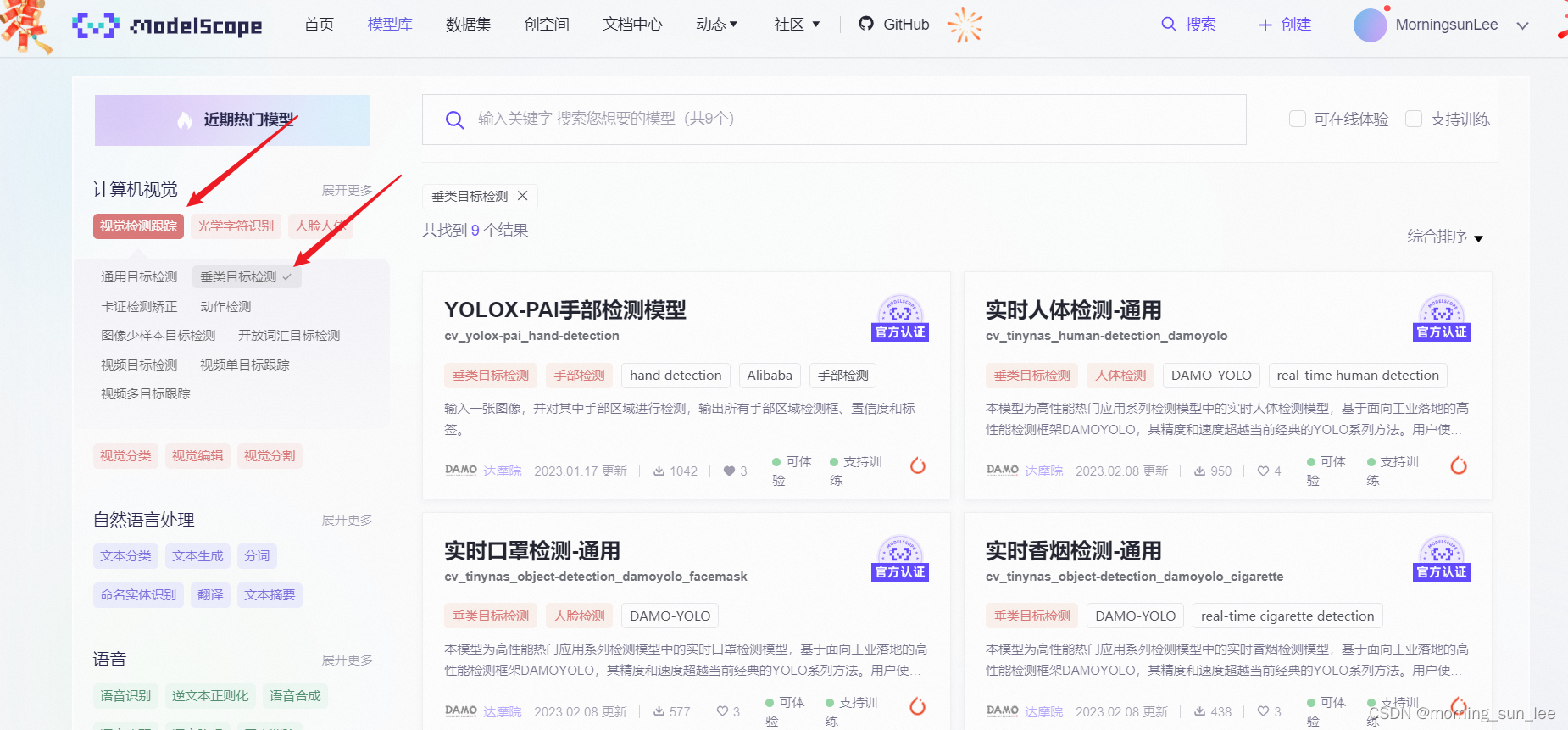
目前,ModelScope上已经有的垂类模型如下表所示,我们也还在逐渐丰富模型中。
| 序号 | 模型名称 | 序号 | 模型名称 |
|---|---|---|---|
| 1 | 实时人体检测模型 | 6 | 实时香烟检测模型 |
| 2 | 实时人头检测模型 | 7 | 实时手机检测模型 |
| 3 | 实时手部检测模型 | 8 | 实时交通标识检测模型 |
| 4 | 实时口罩检测模型 | 9 | Coming soon |
| 5 | 实时安全帽检测模型 |
调用方式
1 Demo Service
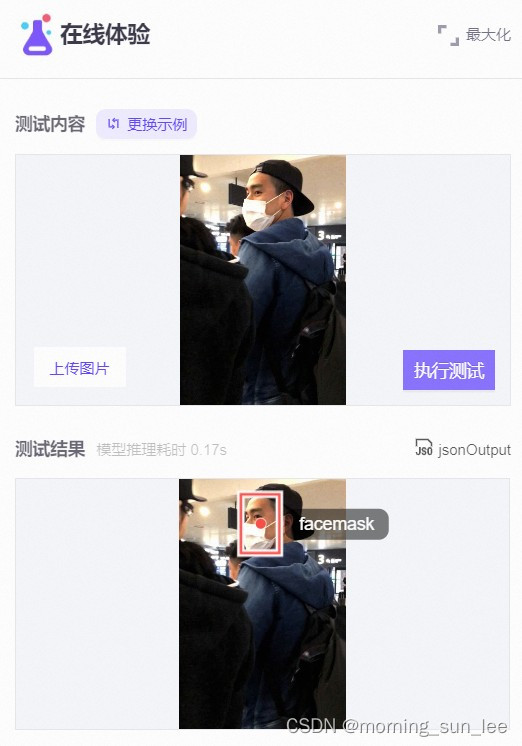
在每个模型主页的右侧,有demo service的区域,可以上传本地的图片,对模型进行测试,如下图所示:
2 Notebook
使用免费的线上机器资源,开启薅羊毛模式,如下图所示。启动对应的实例之后,可以在机器实例中,进行范例代码的运行,也可以搭建自己的服务。

3 本地使用
如果有本地的机器资源的话,也可以直接pip安装modelscope库,就能够在本地进行使用了。具体可以参考安装教程。
* 二次开发
如果需要对现有的模型进行微调(finetune),可以参考每个模型的<微调代码范例>部分,准备好用于微调的数据之后即可对模型进行微调。
总结
垂类检测系列模型是我们在ModelScope上一个初步的尝试,也是针对与Hugging Face差异化做出的一点探索,欢迎大家适用并提出一些建议。我们会继续丰富和完善上面的模型。