公司网站包含哪些内容上海微网站公司
一、介绍
在机器学习中,独立和同分布 (IID) 的概念在数据分析、模型训练和评估的各个方面都起着至关重要的作用。IID 假设是确保许多机器学习算法和统计技术的可靠性和有效性的基础。本文探讨了 IID 在机器学习中的重要性、其假设及其对模型开发和性能的影响。
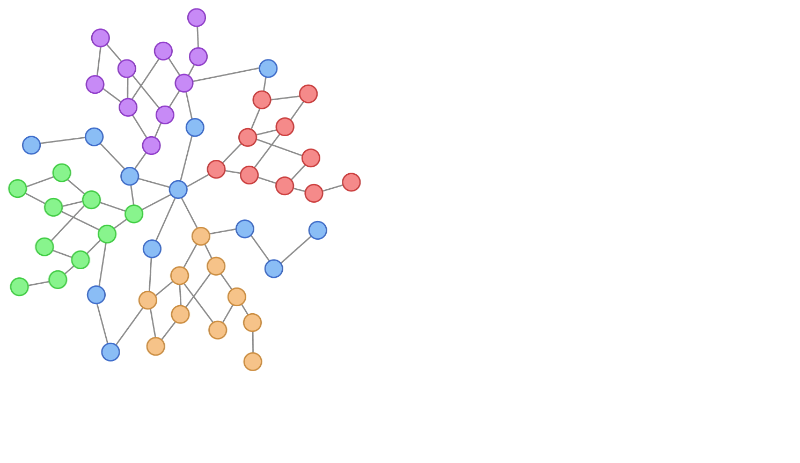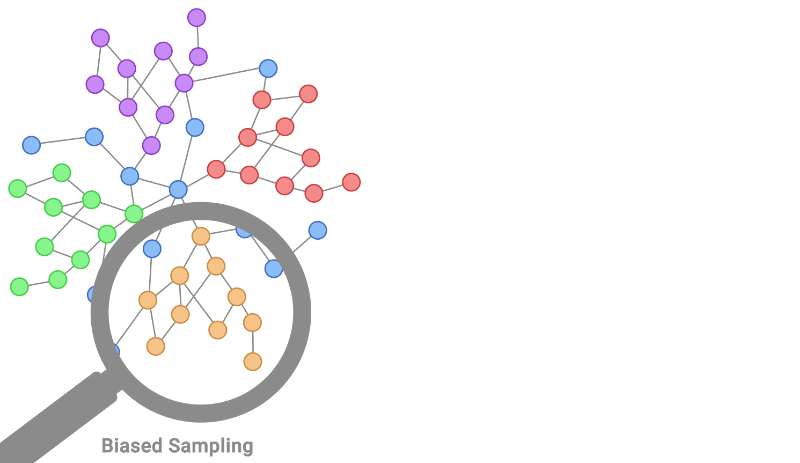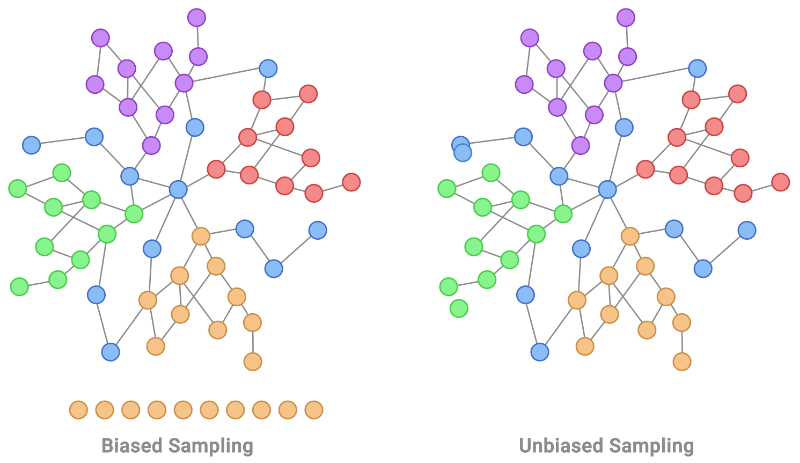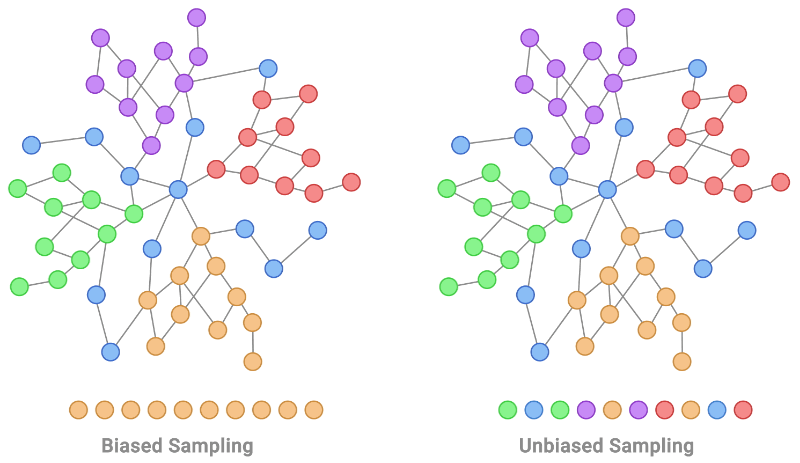
二、了解机器学习中的 IID
在机器学习的上下文中,IID 是指用于构建模型的训练数据是从相同的基础分布中独立随机采样的假设。假定每个数据点都独立于其他数据点,并遵循相同的分布特征。这种假设使得应用强大的统计方法和学习算法成为可能,这些方法和算法依赖于数据中不存在系统依赖性或偏差。
三、IID在机器学习中的假设
- 独立性:独立性假设意味着一个数据点的出现或值不提供有关另一个数据点的出现或值的任何信息。它假设数据点不受彼此影响,并且它们之间没有隐藏的结构或相关性。违反此假设可能会导致模型预测有偏差或不可靠。
- 相同分布:相同分布假设假设数据点来自相同的基础分布。这意味着统计属性(如均值、方差和其他分布特征)在整个数据集中保持一致。偏离此假设可能会引入抽样偏差,导致模型对新的、看不见的数据的泛化能力很差。
四、IID 在机器学习中的影响
- 训练和评估:IID 假设在模型训练和评估过程中至关重要。当训练数据满足IID假设时,机器学习算法可以有效地学习底层模式并做出准确的预测。此外,在模型评估期间,IID 允许使用交叉验证技术和统计测试,确保性能估计值可靠并代表模型的真实性能。
- 特征选择和工程设计:IID 假设会影响特征选择和工程过程。如果违反了独立性假设,则必须正确识别和处理相关或从属特征。特征选择方法可以帮助识别冗余或高度相关的特征,而特征工程技术可以转换或组合特征,以减轻数据中依赖关系的影响。
- 正则化和过拟合:IID 假设与过拟合问题密切相关。当数据违反 IID 假设时,模型可能倾向于记忆或过度拟合训练数据中存在的特定模式,无法很好地泛化到看不见的数据。正则化技术(如 L1 或 L2 正则化)有助于缓解过拟合并提高模型的泛化性能。
- 统计推断和假设检验:IID 假设在机器学习中的统计推断和假设检验中至关重要。统计检验(如 t 检验或卡方检验)假定数据点是独立且相同的分布。违反 IID 假设会导致 p 值不准确,从而影响统计推论和假设检验结果的有效性。
五、挑战和考虑因素
必须认识到,IID 假设可能不适用于所有现实世界场景。真实世界的数据集通常表现出复杂的依赖关系、时间相关性或不平衡的分布。在处理非IID数据时,需要采用专门的技术,如时间序列分析、序列建模或处理不平衡数据的技术,来适当地应对这些挑战。
在机器学习中,模型的训练和评估通常采用独立和同分布 (IID) 的概念。虽然数据可能并不总是严格遵守 IID 假设,但它是许多算法的常见起点。下面是如何使用 Python 创建 IID 数据集并训练简单机器学习模型的示例:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# Generate IID dataset
np.random.seed(0)
num_samples = 1000
num_features = 5# Generate independent random features
X = np.random.rand(num_samples, num_features)# Generate independent and identically distributed labels
y = np.random.randint(0, 2, num_samples)# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)# Make predictions on the test set
y_pred = model.predict(X_test)# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)在上面的代码中,我们首先生成一个 IID 数据集。我们使用 np.random.rand 创建独立的随机特征 (X),其中每行代表一个样本,每列代表一个特征。我们还使用 np.random.randint 生成独立且同分布的标签 (y),其中每个标签对应一个样本。 接下来,我们使用 scikit-learn 库中的 train_test_split 将数据分成训练集和测试集。
训练集(X_train和y_train)将用于训练模型,而测试集(X_test和y_test)将用于评估模型的性能。然后,我们使用 scikit-learn 中的 LogisticRegression 初始化逻辑回归模型,并使用 fit 将其拟合到训练数据。训练结束后,我们使用predict对测试集进行预测。最后,我们使用 scikit-learn 中的 precision_score 计算模型预测的准确性并打印结果。
请记住,此示例假定数据为 IID 的简化方案。在实践中,真实世界的数据集通常表现出更复杂的模式、依赖关系或不平衡,需要额外的预处理步骤和专门的技术来处理这种情况。
六、结论
独立和同分布式 (IID) 的概念在机器学习中起着至关重要的作用,它能够开发鲁棒模型和准确预测。独立性和相同分布的假设为统计方法、正则化技术和模型评估程序提供了基础。了解 IID 假设的含义有助于机器学习从业者在数据预处理、算法选择和模型评估方面做出明智的决策,以确保其模型的可靠性和泛化能力。5-28-2