优购物官方网站 商城直播代运营公司
问题描述
今天要运行一个程序,需要CUDA版本高于10.0,我的电脑无法运行,于是开始检查
首先使用nvidia-smi与nvcc -V指令
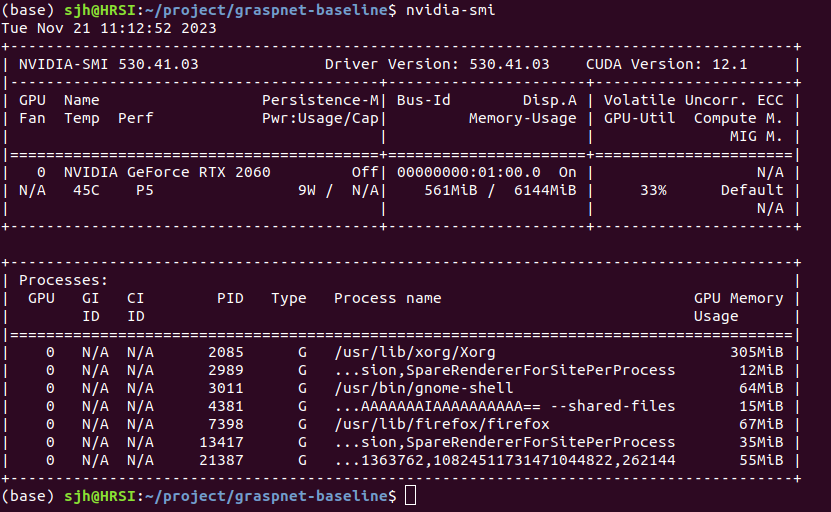

能够看出来,当前显卡驱动适合的CUDA版本为12.1,而本机安装的版本是9.1.85,那么就需要卸载旧版本重新安装新版本的CUDA
这会儿就去找教程,但是大部分教程写的都是如下的方法
cd /usr/local/cuda-xx.x/bin/
sudo ./uninstall_cuda_xx.x.pl
sudo rm -rf /usr/local/cuda-xx.x
然而我去到/usr/local/下却没有cuda文件夹,这就有点慌了
问题分析
然后冷静思考一下,先找一下CUDA安装在哪里再说吧
whereis cuda
得到返回为
cuda: /usr/lib/cuda /usr/include/cuda.h
问题原因
CUDA可能是之前用是通过sudo apt install nvidia-cuda-toolkit安装的
这种安装方法在/usr/include和/usr/lib/cuda/lib64中安装cuda
问题解决
既然是apt install安装的,那就用同样的方式卸载吧
sudo apt-get autoremove nvidia-cuda-toolkit
再做检查,电脑里已经没有CUDA了
