做网站赚钱 2017110平米三室一厅简装图片
Imgui(1) | 基于imgui-SFML改进自由落体小球
0. 简介
使用 SFML 做2D图形渲染的同时,还想添加一个按钮之类的 GUI Widget, 需要用 Dear Imgui。由于 Imgui 对于2D图形渲染并没有提供类似 SFML 的 API, 结合它们两个使用是一个比较好的方法, 找到了 imgui-SFML 这个开源项目。
本篇在先前的自由落体小球基础上,增加两个按钮来控制启动、 停止。 规划如下:
- imgui-SFML 简介
- 构建:编译和跑通 imgui-SFML 官方例子
- 界面设计和实现
1. imgui-SFML 简介
1.1 区分图形库和 GUI 库
Imgui 是一个 GUI 库, 所谓 GUI 库, 一个直观理解是, 看这个库是否提供了 button 这样的 widget, 以及 layout 的设定。
图形库: 通常是基于 OpenGL 或 Vulkan 的封装,不需要提供 button 和 layout, 可以认为它们就是对于 texture 进行操控和显示。
Qt 比较特殊,既能作为 GUI 库, 又能作为图形库。 不过 Qt 的 license 不友好, 不推荐使用。
1.2 Dear ImGui 简介
Dear ImGui Dear ImGui是一个用于C++的即时模式图形用户界面库,主要用于游戏和实时应用程序的开发。它以代码即UI的方式简化界面创建,广泛用于工具和调试界面的快速开发。
Dear ImGui 是一种 imgui 库,但是大家通常也直接管它叫 imgui。 它只提供源代码不提供库。 官方推荐做法是用户直接用它的源码, 但是我感觉这样非常容易造成符号冲突,也容易存在误修改、 重复编译的问题, 因此我会把它构建为一个静态库使用。
1.3 imgui-SFML 简介
imgui-sfml 官方仓库.
imgui-SFML 是让你同时使用 Dear ImGui 和 SFML 的一个库, 是 SFML 官方维护的。
1.4 一些失败的记录
只用 SFML 确实可以绘制简陋的 button, 但是开发效率太低。
只用 imgui 确实可以绘制2D图形,不过感觉那是和 opengl/vulkan 直接交互, 感觉没必要。
很幸运发现了 imgui-SFML 项目。
2. 构建:编译和跑通 imgui-SFML 官方例子
2.1 准备 imgui
cd ~/work/github
git clone https://github.com/ocornut/imgui
# 注意,如果使用 gitee 镜像, https://gitee.com/mirrors/imgui 这个网址有2个月没更新,在 mac arm64 下vulkan例子跑不起来,要用官方最新代码
imgui 的后端,包括两个类型的: 一个类型是渲染后端,另一个类型是平台后端
- Renderers: DirectX9, DirectX10, DirectX11, DirectX12, Metal, OpenGL/ES/ES2, SDL_Renderer, Vulkan, WebGPU.
- Platforms: GLFW, SDL2/SDL3, Win32, Glut, OSX, Android.
我的选择是: OpenGL 作为渲染后端,GLFW 作为平台后端:
- backends/imgui_impl_glfw.cpp
- backends/imgui_impl_opengl3.cpp
等下 CMakeLists.txt 用到他俩
2.2 准备 sfml-IMGUI
cd ~/work/github
git clone https://github.com/SFML/imgui-sfml
看了下 sfml-IMGUI 的 README.md, 说 conan, vcpkg 和 bazel 提供了预编译包。 不过这三个包管理器, 个人都没怎么用过, 也没空学, 采用源代码的方式配置 imgui-sfml.
2.3 组织 CMakeLists.txt
相比于官方的 cmake 使用方式, 我的方式有一些不一样的地方:我是从 imgui 和 imgui-SFML 的源代码创建了两个库 (target), 并且这两个 target 之间有依赖关系。 然后在创建的可执行目标上, 直接依赖 sfml-IMGUI 这个 target:
cmake_minimum_required(VERSION 3.25)
project(imgui_demos)
set(CMAKE_CXX_STANDARD 17)find_package(OpenGL REQUIRED)
find_package(glfw3 REQUIRED)
find_package(Vulkan REQUIRED)
find_package(SFML COMPONENTS audio graphics window system)#--- imgui
set(IMGUI_DIR "/Users/zz/work/github/imgui")
add_library(imgui STATIC${IMGUI_DIR}/backends/imgui_impl_glfw.cpp${IMGUI_DIR}/backends/imgui_impl_opengl3.cpp${IMGUI_DIR}/imgui.cpp${IMGUI_DIR}/imgui_demo.cpp${IMGUI_DIR}/imgui_draw.cpp${IMGUI_DIR}/imgui_tables.cpp${IMGUI_DIR}/imgui_widgets.cpp
)
target_include_directories(imgui PUBLIC${IMGUI_DIR}${IMGUI_DIR}/backends
)
target_link_libraries(imgui PUBLIC glfw OpenGL::GL)#--- imgui-SFML
set(IMGUI_SFML_DIR "/Users/zz/work/github/imgui-sfml")
add_library(ImGui-SFML STATIC${IMGUI_SFML_DIR}/imgui-SFML.cpp${IMGUI_SFML_DIR}/imconfig-SFML.h
)
target_include_directories(ImGui-SFML PUBLIC ${IMGUI_SFML_DIR})
target_link_libraries(ImGui-SFML PUBLIC sfml-graphics sfml-window sfml-system imgui)#--- imgui-sfml-demo
add_executable(imgui-sfml-demo imgui-sfml-demo.cpp)
target_link_libraries(imgui-sfml-demo PUBLIC ImGui-SFML)
2.4 imgui-SFML 官方demo代码
代码来自 README.md,在先前熟悉了 SFML 的前提下,这里列出 demo 代码里增加的 imgui 和 imgui-SFML 的内容.
头文件:
#include "imgui.h" // [imgui]
#include "imgui-SFML.h" // [imgui-SFML]
初始化:
ImGui::SFML::Init(window); // [imgui-SFML]
事件处理:
while (window.isOpen()){sf::Event event;while (window.pollEvent(event)){ImGui::SFML::ProcessEvent(window, event); // [imgui-SFML]if (event.type == sf::Event::Closed){window.close();}}...}
窗口的清屏、 渲染、 显示: 增加了好几个 imgui 和 imgui-SFML 的调用:
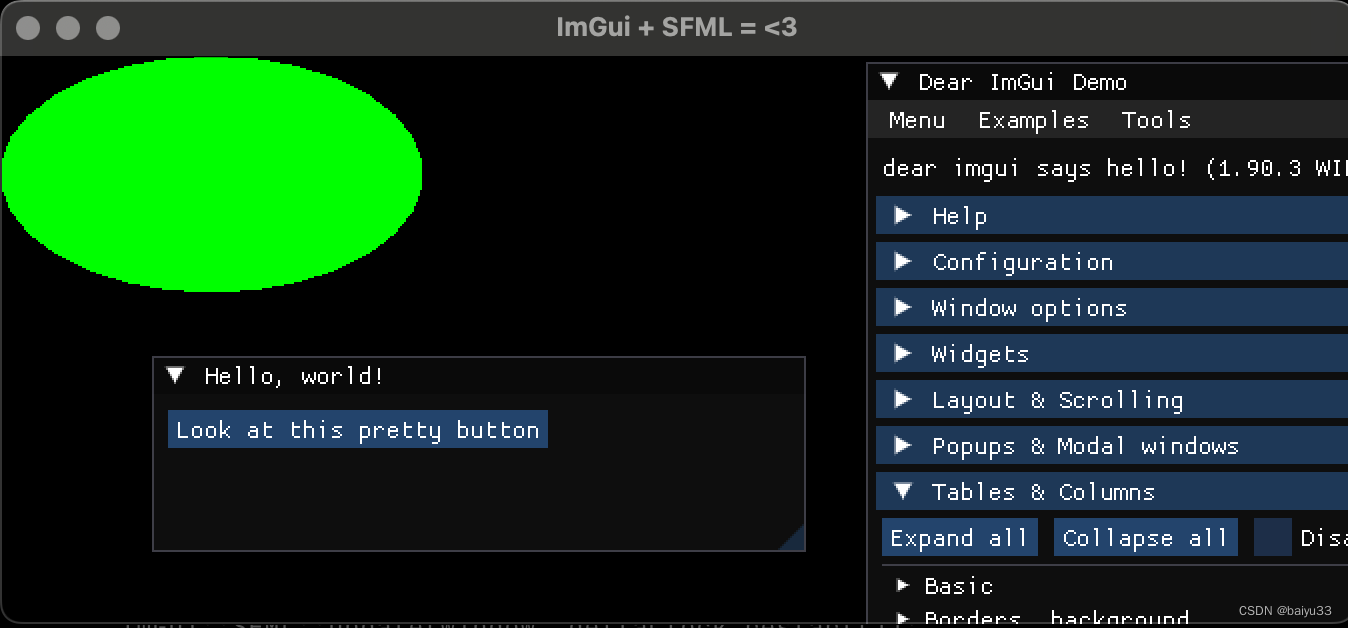
ImGui::SFML::Update(window, deltaClock.restart()); // [imgui-SFML]ImGui::ShowDemoWindow(); // [imgui]ImGui::Begin("Hello, world!"); // [imgui]ImGui::Button("Look at this pretty button"); // [imgui]ImGui::End(); // [imgui]window.clear();window.draw(shape);ImGui::SFML::Render(window); // [imgui-SFML]window.display();
资源释放:
ImGui::SFML::Shutdown(); // [imgui-SFML]
完整的代码如下:
#include "imgui.h"
#include "imgui-SFML.h"#include <SFML/Graphics/CircleShape.hpp>
#include <SFML/Graphics/RenderWindow.hpp>
#include <SFML/System/Clock.hpp>
#include <SFML/Window/Event.hpp>int main() {sf::RenderWindow window(sf::VideoMode(640, 480), "ImGui + SFML = <3");window.setFramerateLimit(60);ImGui::SFML::Init(window);sf::CircleShape shape(100.f);shape.setFillColor(sf::Color::Green);sf::Clock deltaClock;while (window.isOpen()) {imgui-sfml-demo.cppsf::Event event;imgui-sfml-demo.cppint main()
{sf::RenderWindow window(sf::VideoMode(640, 480), "ImGui + SFML = <3");window.setFramerateLimit(60);ImGui::SFML::Init(window); // [imgui-SFML]sf::CircleShape shape(100.f);shape.setFillColor(sf::Color::Green);sf::Clock deltaClock;while (window.isOpen()){sf::Event event;while (window.pollEvent(event)){ImGui::SFML::ProcessEvent(window, event); // [imgui-SFML]if (event.type == sf::Event::Closed){window.close();}}ImGui::SFML::Update(window, deltaClock.restart()); // [imgui-SFML]ImGui::ShowDemoWindow(); // [imgui]ImGui::Begin("Hello, world!"); // [imgui]ImGui::Button("Look at this pretty button"); // [imgui]ImGui::End(); // [imgui]window.clear();window.draw(shape);ImGui::SFML::Render(window); // [imgui-SFML]window.display();}ImGui::SFML::Shutdown(); // [imgui-SFML]
}
2.5 编译运行
cmake -S . -B build
cmake --build build
./build/imgui-sfml-demo.cpp
3. 界面设计和实现
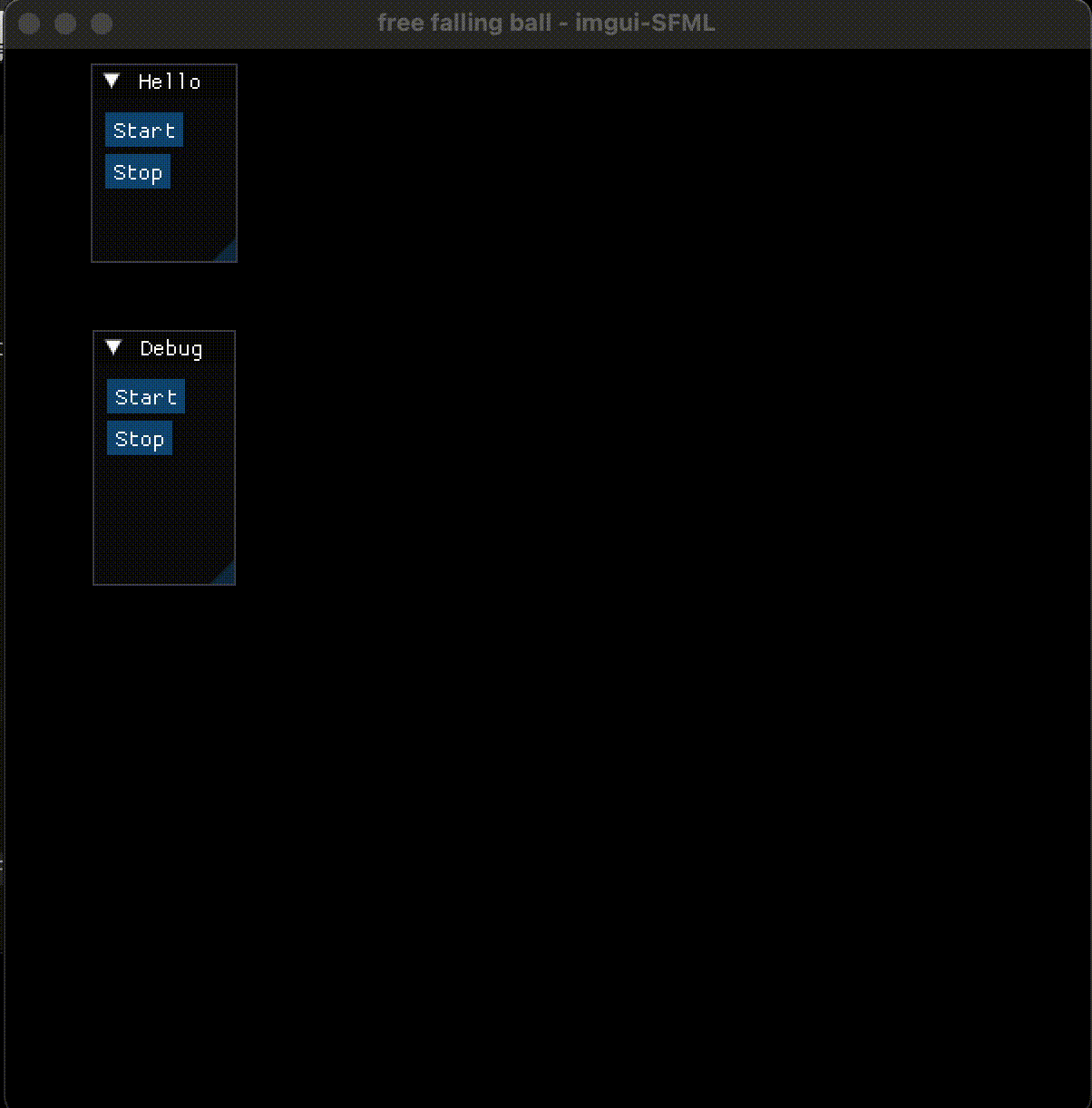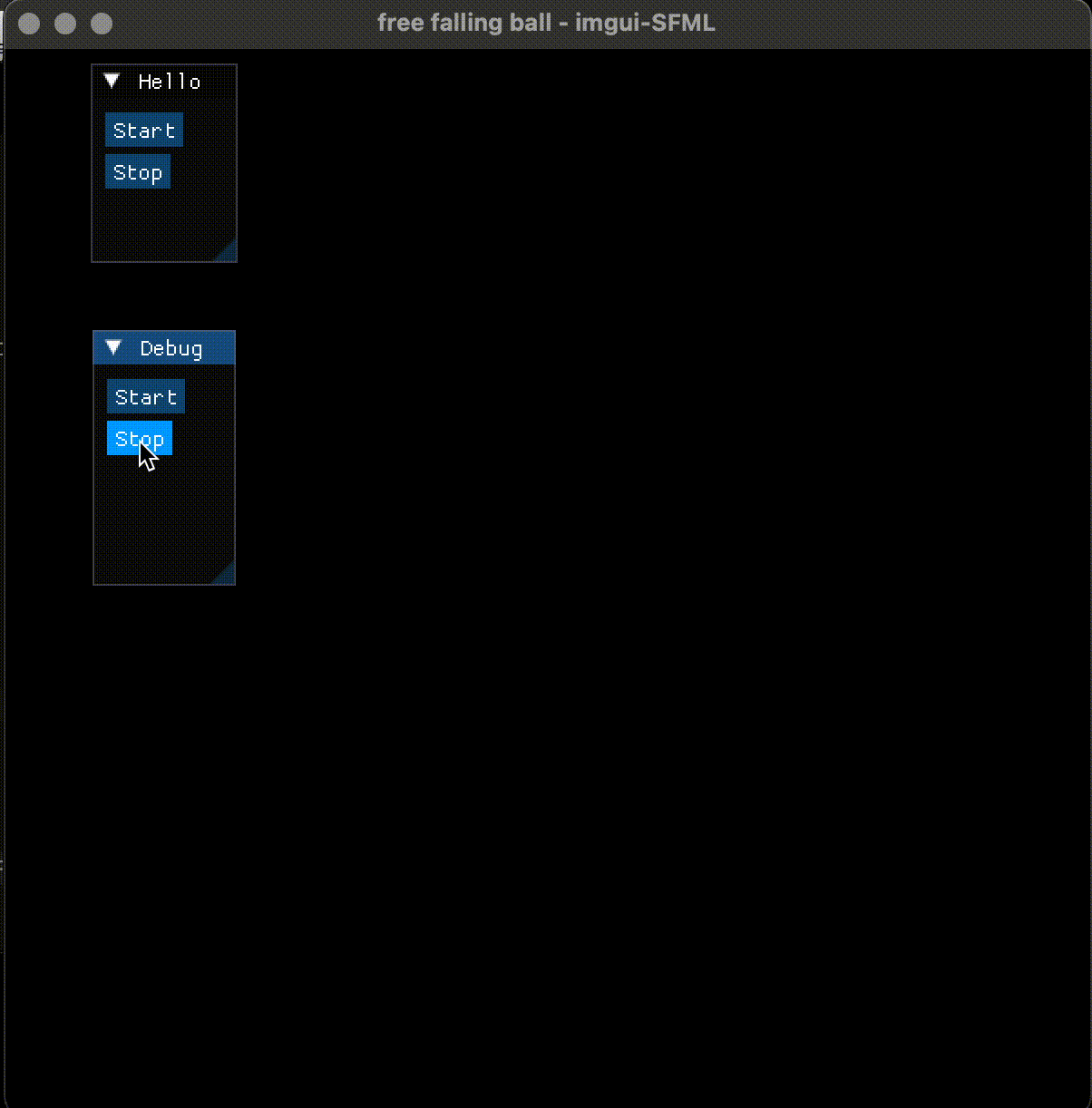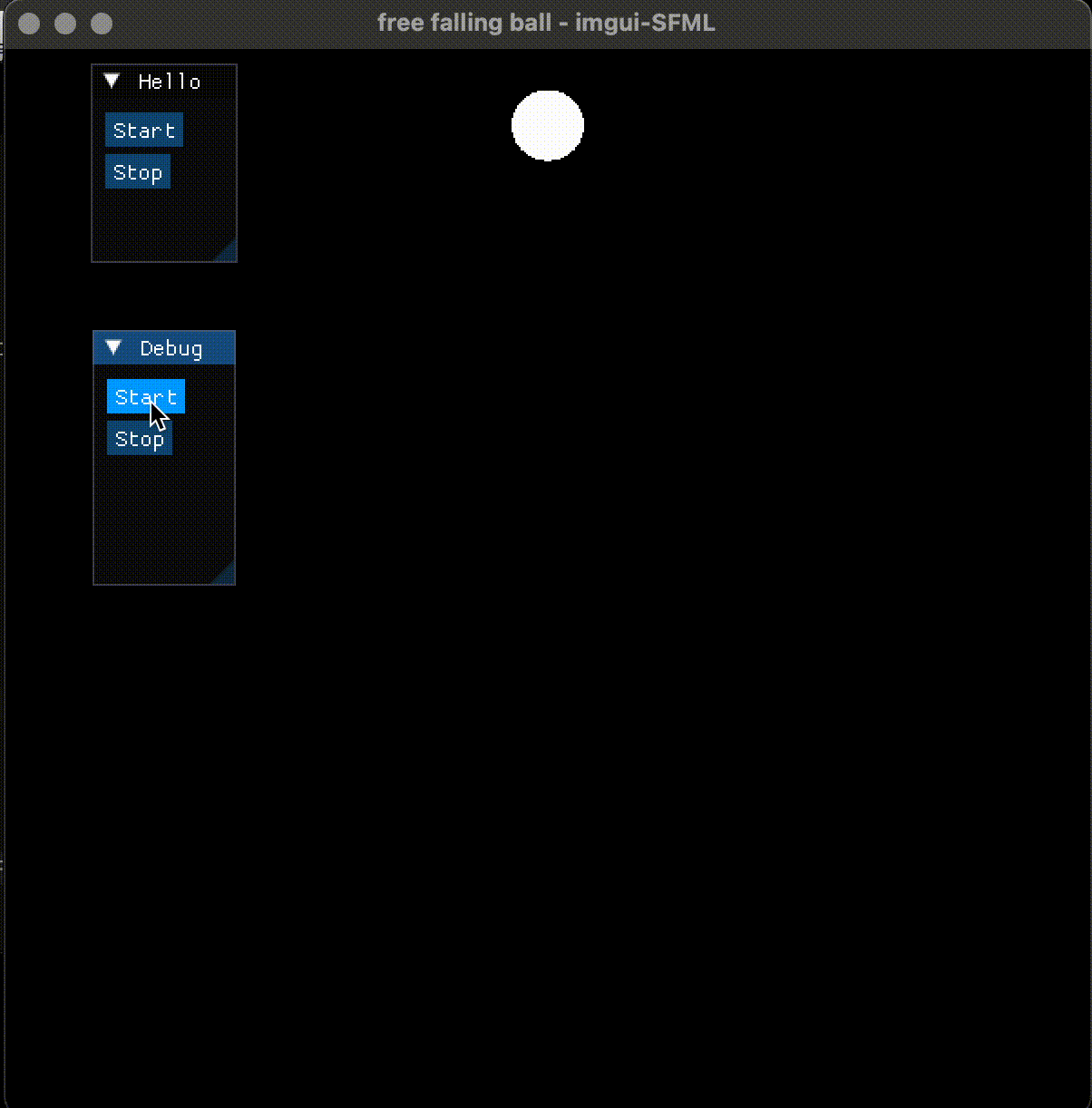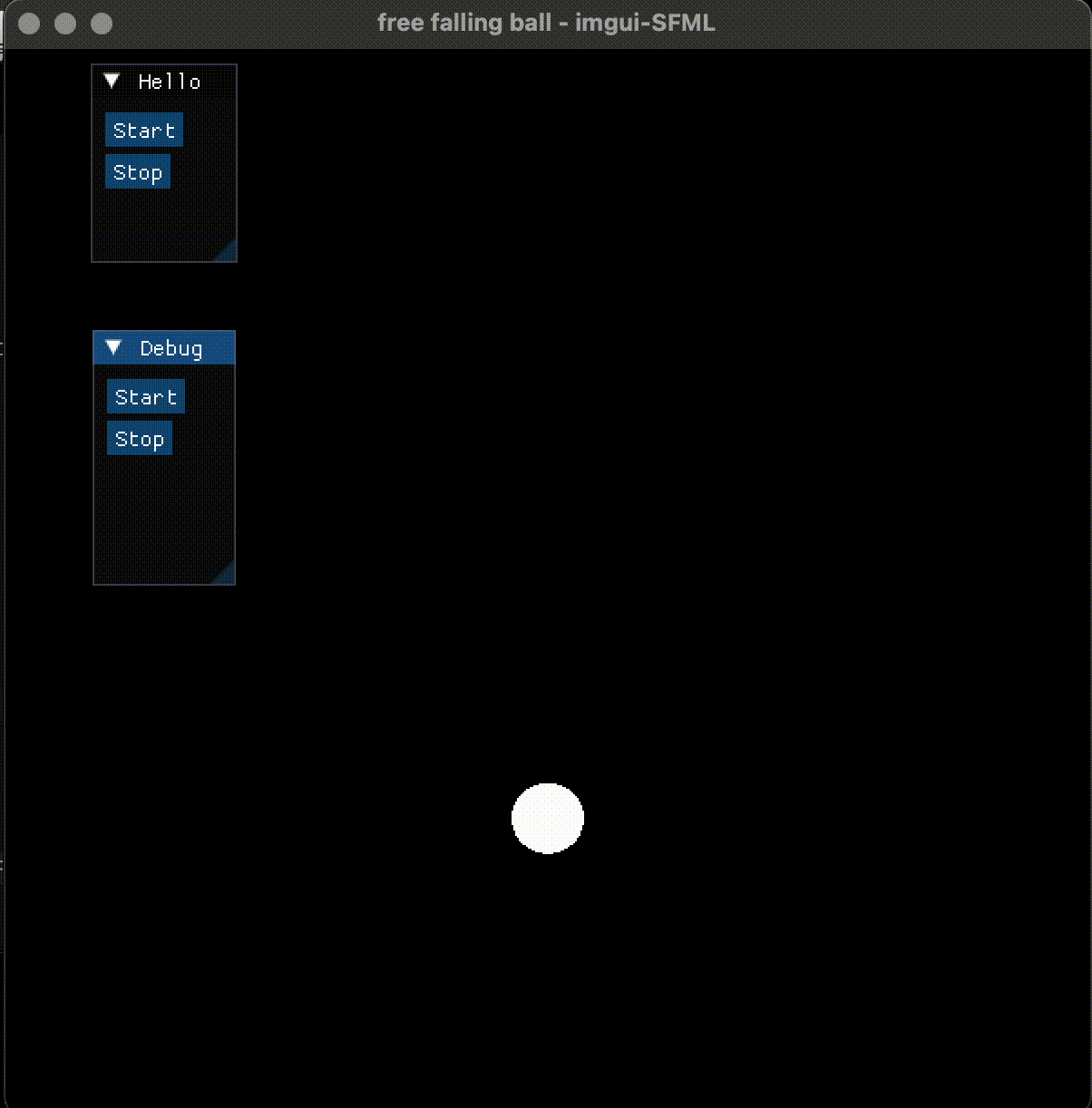
imgui 的 button 默认是悬浮的, 这是和以往的 GUI (如 java swing, Qt, Tkinter) 不同的地方, 习惯就好。
增加了两个按钮,并定义了点击它们后的函数, 分别让全局变量 running 为1或0:
constexpr float radius = 20.0f;
int running = 0;
float vy = 0;
float y = radius;void start()
{running = 1;vy = 0;y = radius;
}void stop()
{running = 0;
}int main()
{...ImGui::Begin("Hello"); // [imgui]ImGui::Button("Start"); // [imgui]ImGui::Button("Stop"); // [imgui]ImGui::End(); // [imgui]if (ImGui::Button("Start")){start();}if (ImGui::Button("Stop")){stop();}
}
而更新小球位置的代码, 和以前一样的:
int main()
{...if (running){sf::CircleShape circle(radius);circle.setFillColor(sf::Color::White);vy = vy + g;y = y + vy;if (y >= win_height - radius){vy = -0.95 * vy;}if (y > win_height - radius){y = win_height - radius;}circle.setPosition(win_width/2-radius, y);window.draw(circle);}...
}
完整代码:
#include "imgui.h" // [imgui]
#include "imgui-SFML.h" // [imgui-SFML]#include <SFML/Graphics/CircleShape.hpp>
#include <SFML/Graphics/RenderWindow.hpp>
#include <SFML/System/Clock.hpp>
#include <SFML/Window/Event.hpp>
#include <SFML/Graphics.hpp>constexpr float radius = 20.0f;
int running = 0;
float vy = 0;
float y = radius;void start()
{running = 1;vy = 0;y = radius;
}void stop()
{running = 0;
}int main()
{constexpr int win_width = 600;constexpr int win_height = 600;sf::RenderWindow window(sf::VideoMode(win_width, win_height), "free falling ball - imgui-SFML");window.setFramerateLimit(60);bool success = ImGui::SFML::Init(window); // [imgui-SFML]if (!success)return -1;constexpr float g = 0.5;sf::Clock deltaClock;while (window.isOpen()){sf::Event event;while (window.pollEvent(event)){ImGui::SFML::ProcessEvent(window, event); // [imgui-SFML]if (event.type == sf::Event::Closed){window.close();}}ImGui::SFML::Update(window, deltaClock.restart()); // [imgui-SFML]// ImGui::ShowDemoWindow(); // [imgui]ImGui::Begin("Hello"); // [imgui]ImGui::Button("Start"); // [imgui]ImGui::Button("Stop"); // [imgui]ImGui::End(); // [imgui]if (ImGui::Button("Start")){start();}if (ImGui::Button("Stop")){stop();}window.clear();if (running){sf::CircleShape circle(radius);circle.setFillColor(sf::Color::White);vy = vy + g;y = y + vy;if (y >= win_height - radius){vy = -0.95 * vy;}if (y > win_height - radius){y = win_height - radius;}circle.setPosition(win_width/2-radius, y);window.draw(circle);}ImGui::SFML::Render(window); // [imgui-SFML]window.display();}ImGui::SFML::Shutdown(); // [imgui-SFML]return 0;
}
4. 总结
经过尝试和查找, 发现了 imgui-SFML 这个仓库, 使用它时要求用户同时会 imgui, imgui-SFML, SFML 三个库, 不过 imgui-SFML 代码很少,SFML 文档齐全. 对于 Imgui 的使用, 官方没有文档, 以例子代码为参考即可。
在使用 imgui-SFML 时, 首先在 CMakeLists.txt 里以 imgui 和 imgui-SFML 源码方式构建了静态库, 然后在可执行目标上依赖它们, 相比于折腾 conan, vcpkg, bazel 这些包管理器, 更加简单方便。
在改进小球自由下落界面时,通过增加了 start、stop 按钮, 在按下 start 后开启下落, 在按下 stop 后停止下落, 实现了交互式的界面控制, 使得 GUI 交互 和 2D 渲染在同一个程序中得意表达。 这个例子没有直接的食用价值, 不过稍加改造,可以用于算法或复杂过程的模拟和调试。
References
- Dear Imgui 官方仓库
- imgui-SFML 官方仓库
- ImGui给按钮添加点击事件