做网站申请哪类商标网站开发建设费用包括那些
1、KSS00276 机器人参数不等于机器人类型
①登录专家模式
②示教器操作:【菜单】—【显示】—【变量】—【单个】
③名称输入:$ROBTRAFO[]
新值:TRAFONAME[]
④点击【设定值】。
2、电池报警:
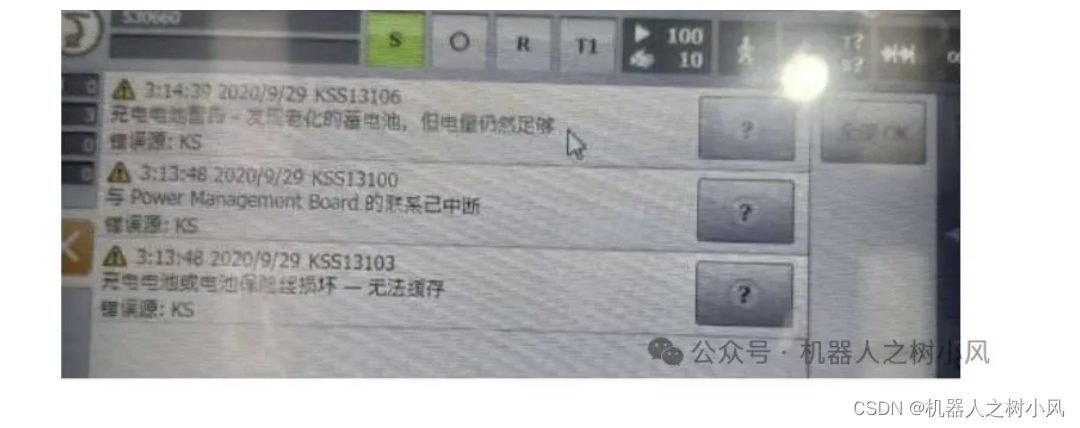 ①“充电电池警告-发现老化的蓄电池,但电量仍然足够”
①“充电电池警告-发现老化的蓄电池,但电量仍然足够”
②“充电电池或电池保险丝损坏-无法缓存”
分析:这种情况一般是机器人首次开机时出现的,机器人出厂时没有将蓄电池的插头插在控制柜内的 CCU 板卡上。
措施:找到控制柜内的蓄电池电源插头,插到对应标签的 CCU板卡插口上。
3、KSS00203-全部运行开通
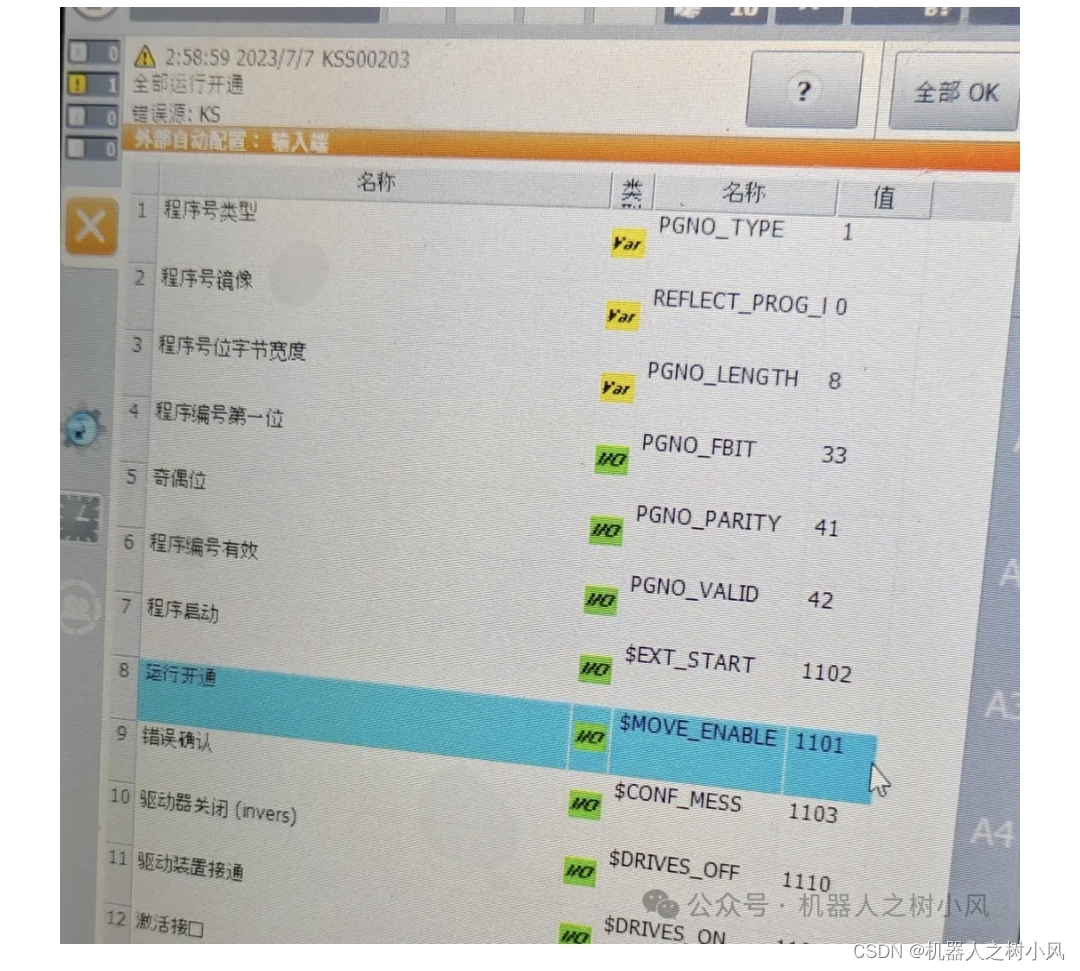
措施:
①【主菜单】—【配置】—【输入/输出端】—【外部自动运行】下;
②在【输入端】找到$MOVE_ENBALE 对应的通道改为1025。如果在外部自动运行状态下,就检查 PLC 端对应的这个信号有没有给。
4、KSS00308 卸码垛模式:将轴 A5+移到位
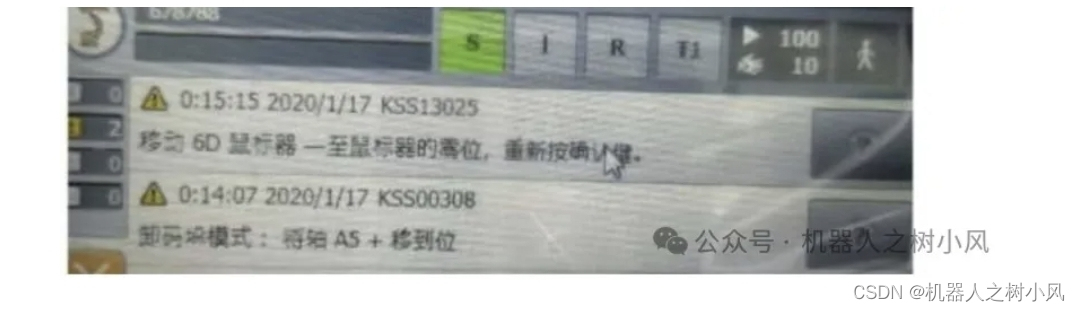
措施:
①登录专家模式
②示教器操作:【菜单】—【显示】—【变量】—【单个】
③名称输入:$pal_mode
新值:true
④点击【设定值】更新
⑤重启控制柜。
5、KSS15012 确认开关损坏
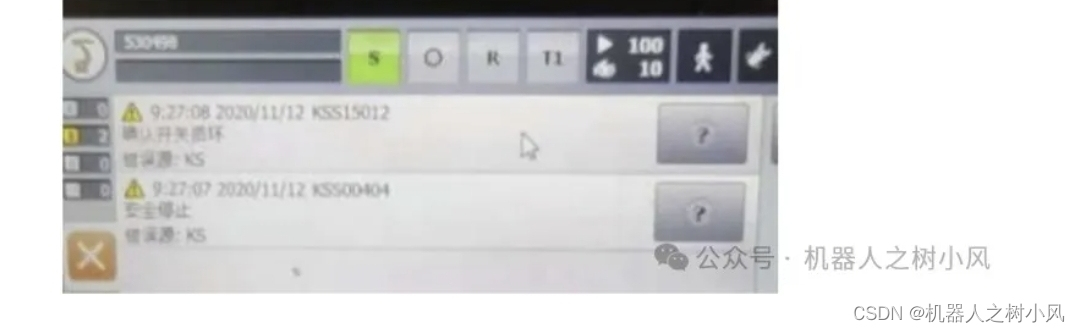 分析:示教器使能键分三个档位:
分析:示教器使能键分三个档位:
①正常不按时为一个档位;
②正常上电移动机器人时,第二个档位;
③按到底时第三个档位,会出现安全停止的报警。
处理:将使能键按到底,会出现“确认开关故障”的确认信息,点击“OK”即可。
温馨提示:在同名公众号上可以查看更多机器人技术内容。