做视频网站程序多少钱网站打开空白页面
在autodl上部署大模型
windows运行太麻烦,环境是最大问题。
选择云上服务器【西北B区 / 514机】
cpp (c++ c plus plus)
- 纯 C/C++ 实现,无需外部依赖。
- 针对使用 ARM NEON、Accelerate 和 Metal 框架的 Apple 芯片进行了优化。
- 支持适用于 x86 架构的 AVX、AVX2 和 AVX512。
- 提供 F16/F32 混合精度,并支持 2 位至 8 位整数量化。
参考:GitHub - li-plus/chatglm.cpp: C++ implementation of ChatGLM-6B & ChatGLM2-6B & ChatGLM3 & GLM4 & more LLMs
部署 chatglm3
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp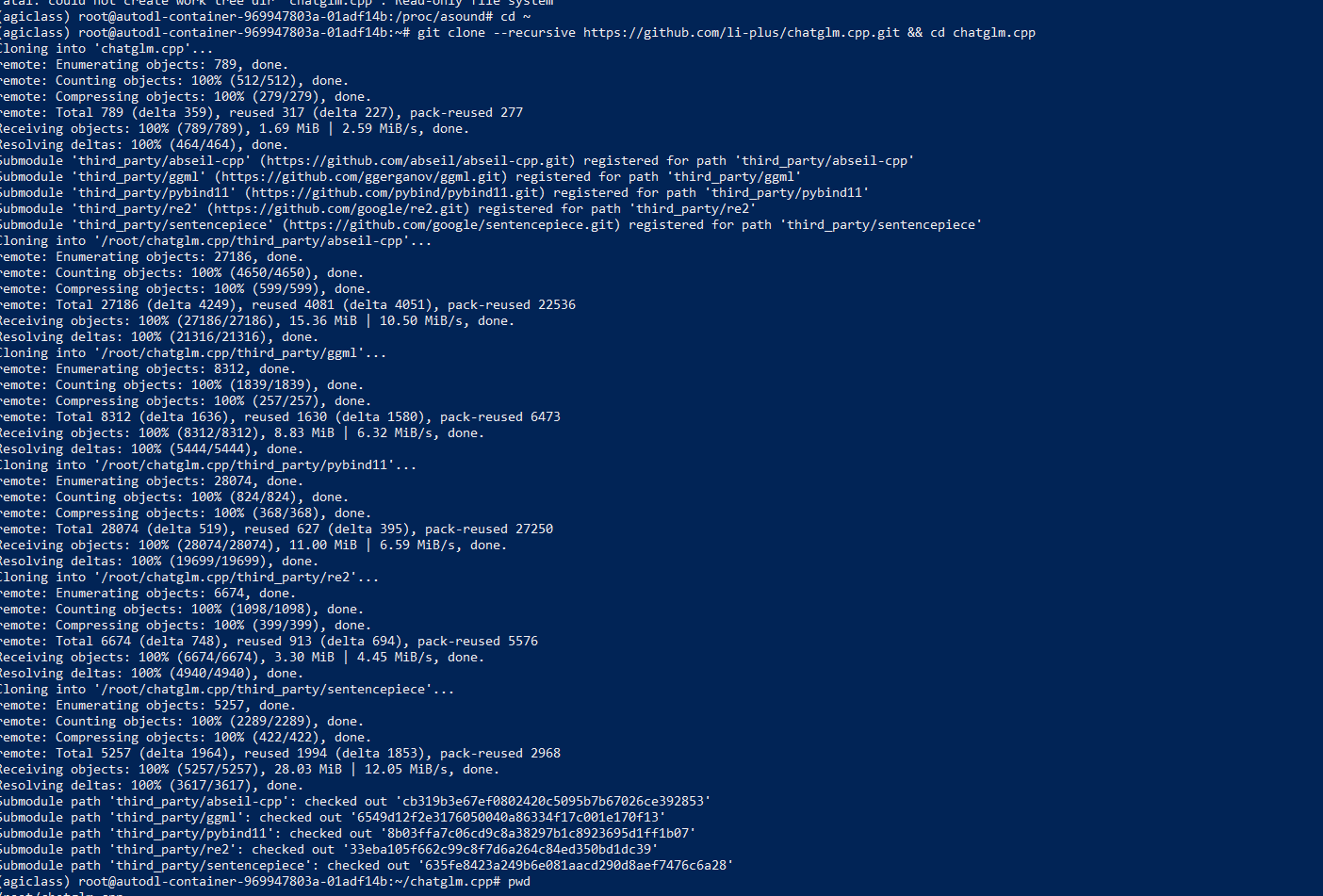
clone 上的app /mnt/workspace/chatglm.cpp
/root/chatglm.cpp
cd /mnt/workspace/chatglm.cpp
git submodule update --init --recursive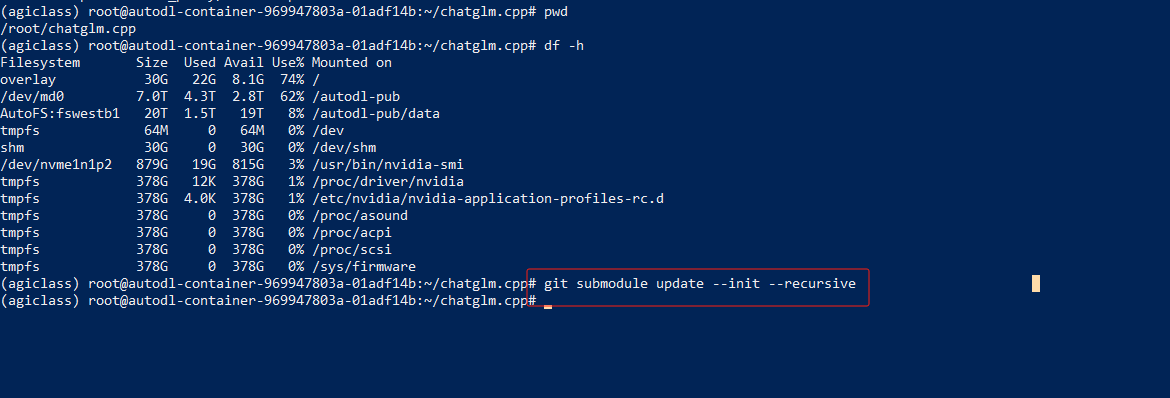
Quantize Model 量化模型
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece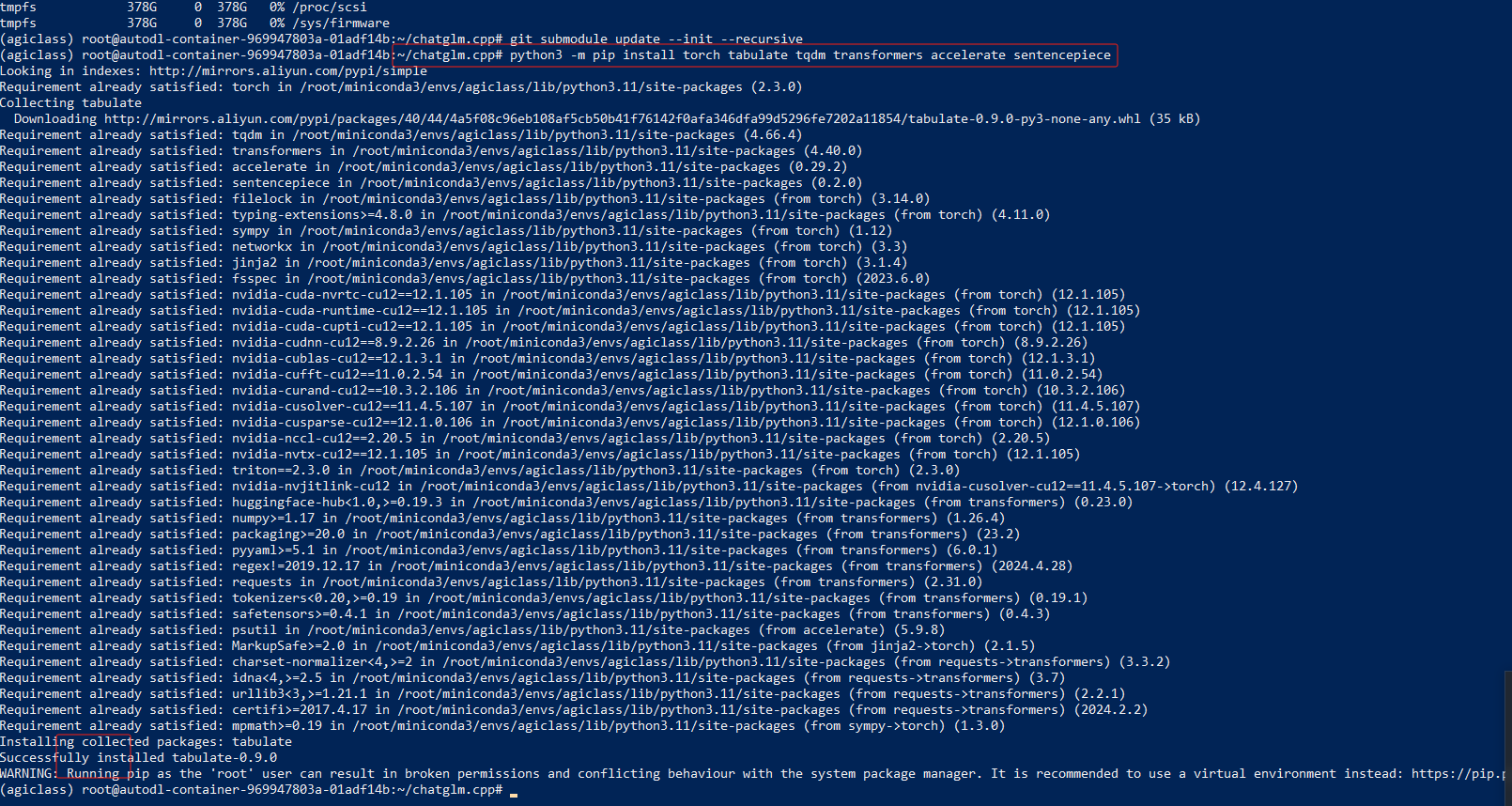

执行上面量化模型语句时:python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
报错:/usr/bin/python3: No module named pip
slove: 执行下面命令:
sudo apt update
sudo apt install python3-pip
再次执行上面量化模型命令后,ok.
通过 convert 专为 GGML 格式
- 用于 convert.py 将 ChatGLM-6B 转换为量化的 GGML 格式。要将 fp16 原始模型转换为 q4_0(量化 int4)GGML 模型,请运行:
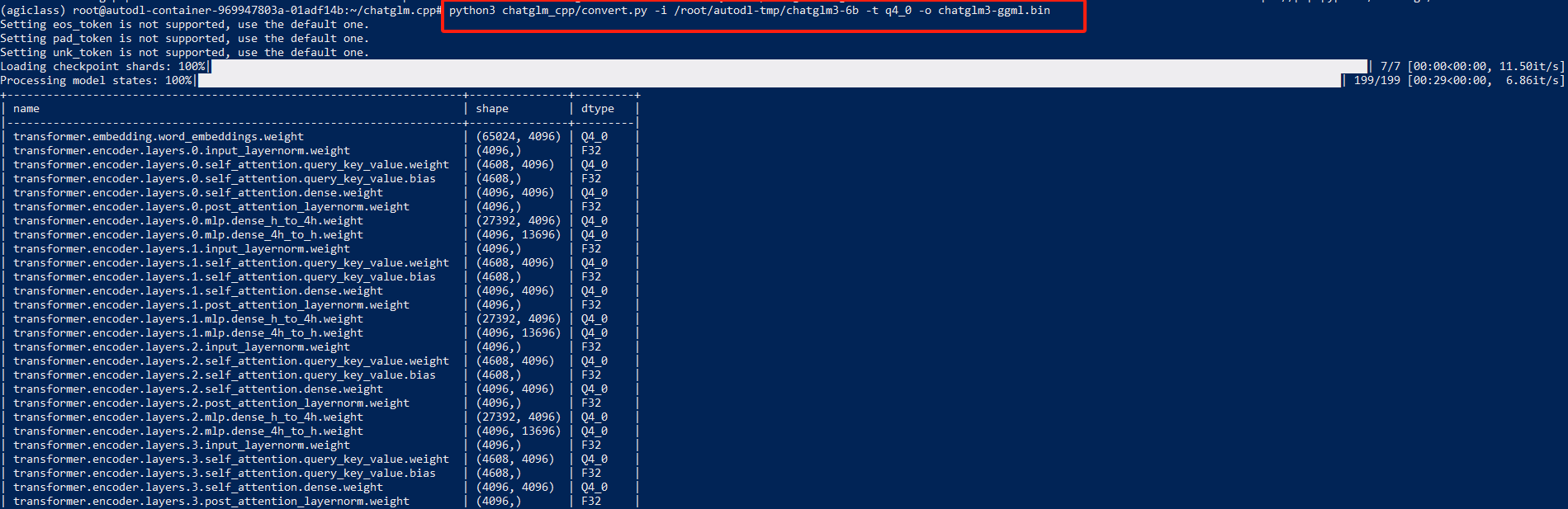
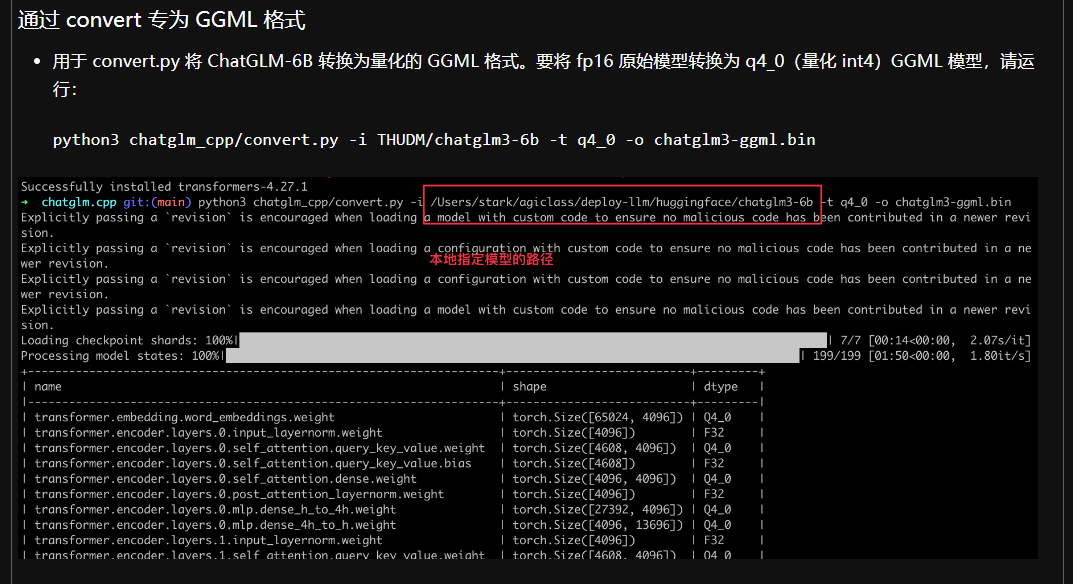
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o chatglm3-ggml.bin在autodll机器:西北B区 / 514机
执行命令:python3 chatglm_cpp/convert.py -i /root/autodl-tmp/chatglm3-6b -t q4_0 -o chatglm3-ggml.bin
注:/root/autodl-tmp/chatglm3-6b 是模型路径
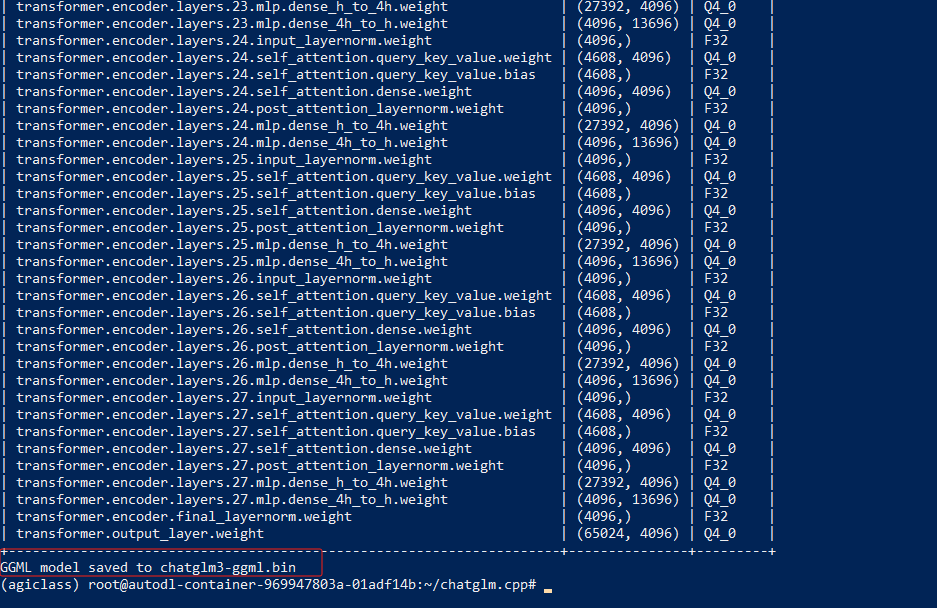
GGML model saved to chatglm3-ggml.bin 代表执行成功。
上面的执行命令解释:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o chatglm3-ggml.bin
这个命令是在使用 Python 脚本将一个模型转换成另一种格式。下面是对命令的详细解释,特别是对 `THUDM/chatglm3-6b` 部分的说明:
- `python3`:这是运行 Python 解释器的命令。它指定脚本应该使用 Python 3 执行。
- `chatglm_cpp/convert.py`:这指定了正在执行的 Python 脚本的路径。脚本位于 `chatglm_cpp` 目录中,文件名为 `convert.py`。这个脚本很可能负责将模型从一种格式转换成另一种格式。
- `-i THUDM/chatglm3-6b`:`-i` 选项指定了脚本将要转换的输入模型。`THUDM/chatglm3-6b` 是要被转换的模型的标识符。在 Hugging Face 模型的上下文中,`THUDM` 很可能是上传模型的组织或用户,而 `chatglm3-6b` 是特定模型的名称。这意味着脚本将在 Hugging Face 模型中心或指定的目录下查找名为 `chatglm3-6b` 的模型。
- `-t q4_0`:`-t` 选项指定了转换的类型或版本。在这个例子中,`q4_0` 很可能代表脚本在转换模型时应该使用的特定转换目标或格式版本。
- `-o chatglm3-ggml.bin`:`-o` 选项指定了转换后模型的输出文件。脚本将把转换后的模型写入一个名为 `chatglm3-ggml.bin` 的文件。这个文件将在转换后包含新格式的模型。
总之,命令中的 `THUDM/chatglm3-6b` 部分指定了 `convert.py` 脚本将要转换的输入模型。它表示名为 `chatglm3-6b` 的模型,与 `THUDM` 组织或用户相关联,应该根据 `-t q4_0` 选项指定的新格式进行转换,并将结果保存到 `chatglm3-ggml.bin` 文件中。
在命令行启动服务
第一步:使用 CMake 配置项目并在当前目录下创建一个名为 "build" 的构建目录
cmake -B build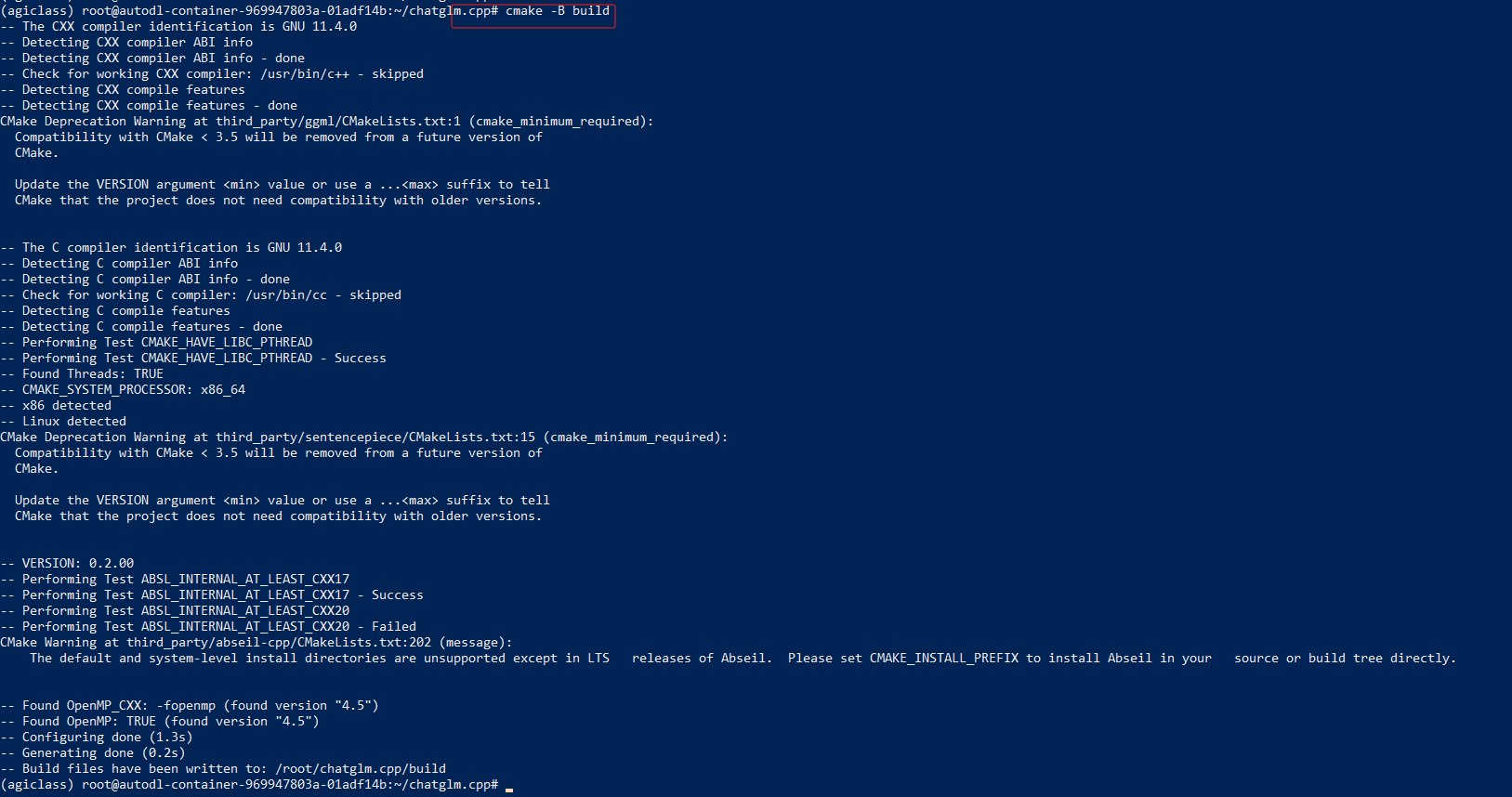
第二步:使用先前生成的构建系统文件在构建目录 "build" 中构建项目,采用并行构建和 Release 配置
cmake --build build -j --config Release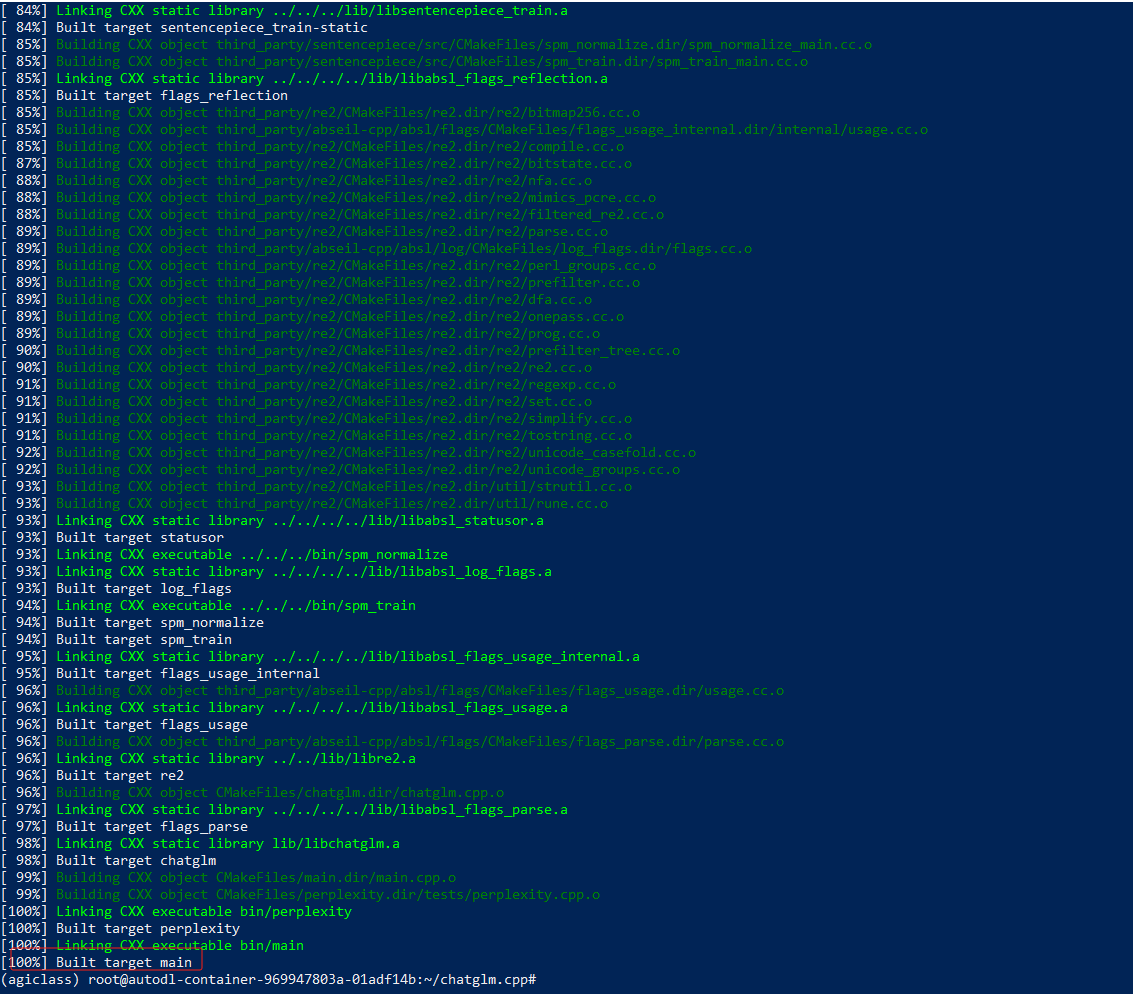
第三步:运行
./build/bin/main -m chatglm3-ggml.bin -p 你好
启动 web 服务
python3 ./examples/web_demo.py -m chatglm3-ggml.bin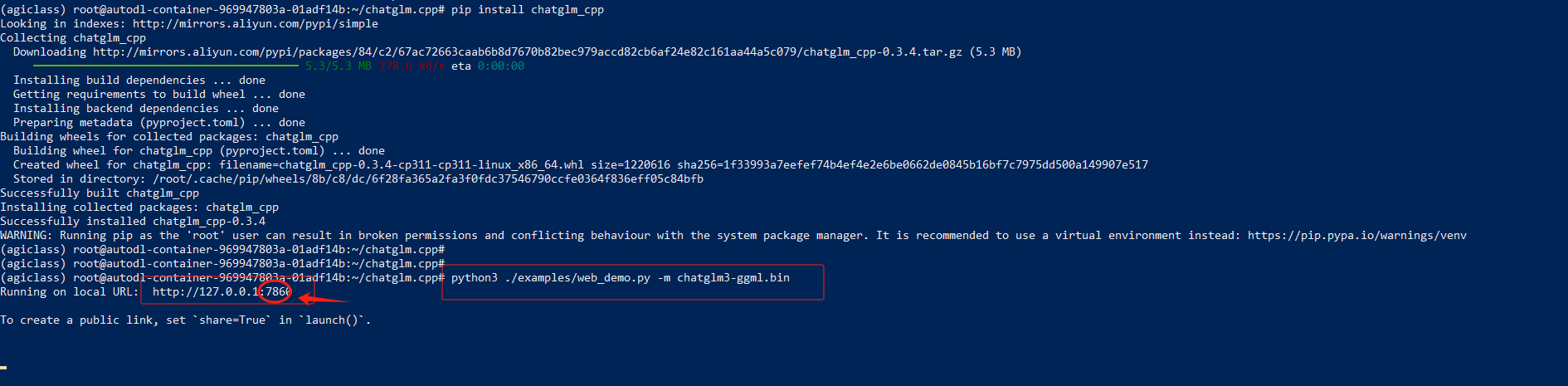

上面的ssh命令复制到记事本中.
ssh -p 53421 root@connect.westc1.gpuhub.com
ssh -CNg -L 7860:127.0.0.1:7860 root@connect.westc1.gpuhub.com -p 53421
密码:t1sftwFjHSxKr123

在powershell中执行命令:ssh -CNg -L 7860:127.0.0.1:7860 root@connect.westc.gpuhub.com -p 53421
注:没有任何提示,表示成功。
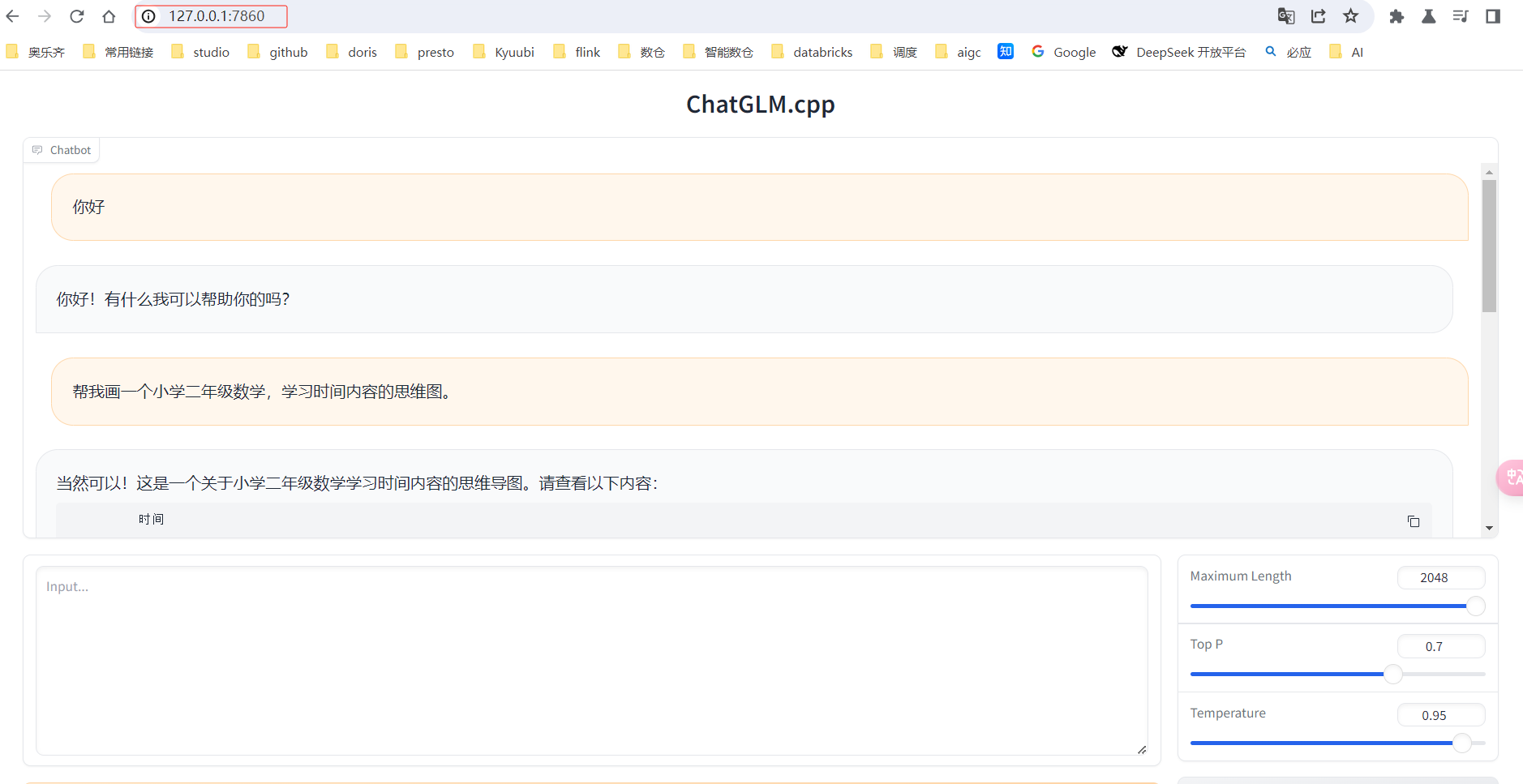
访问web页面,chatGLM部署成功。