广州网站建设费四川外国语大学网站建设
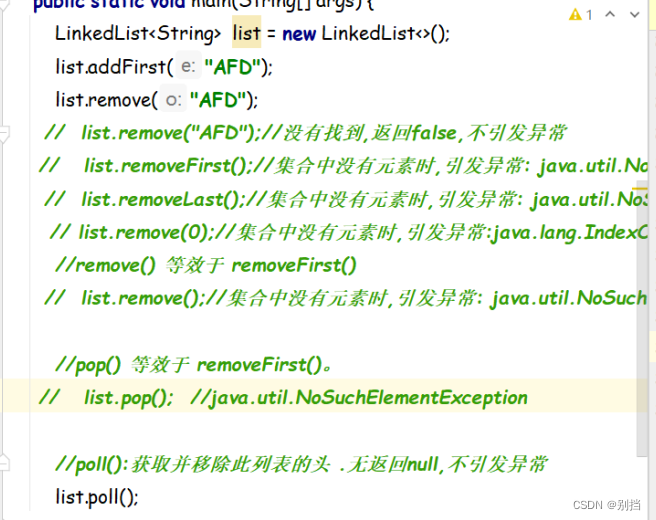
List实现类
List接口特点:元素有序 可重复
Arraylist 可变数组
jdk 8 以前Arraylist容量初始值10
jdk8 之后初始值为0,添加数据时,容量为10;
ArrayList与Vector的区别?

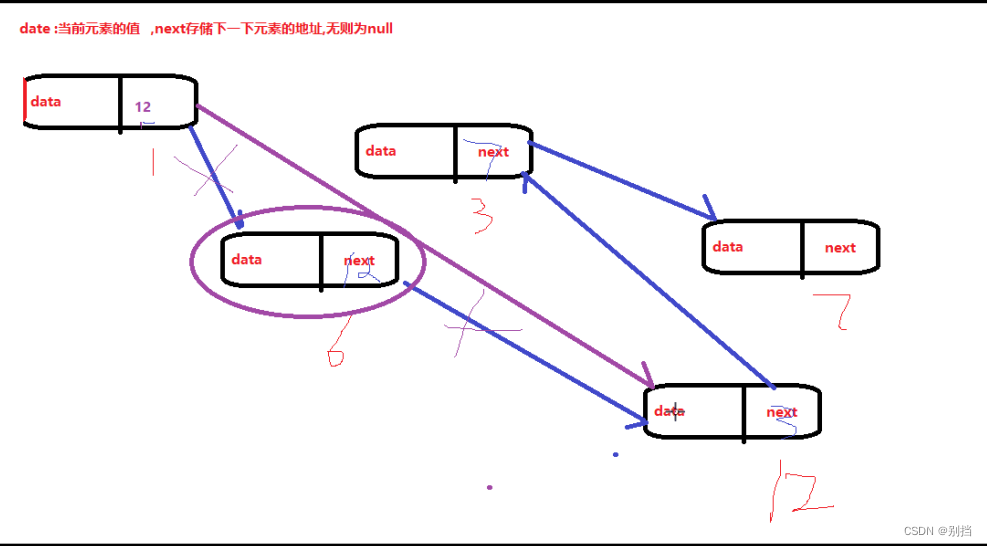
LinkList:双向链表
优点:不连续存储,随机添加和删除操作方法
缺点:不连续存储,遍历速度慢
有链表头和链表尾
新增针对链表头和链表尾的操作方法


Set集合及实现类
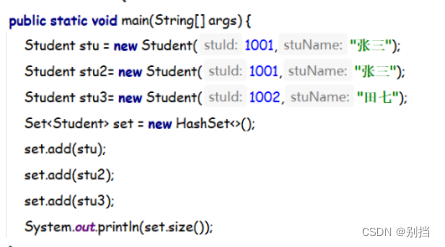
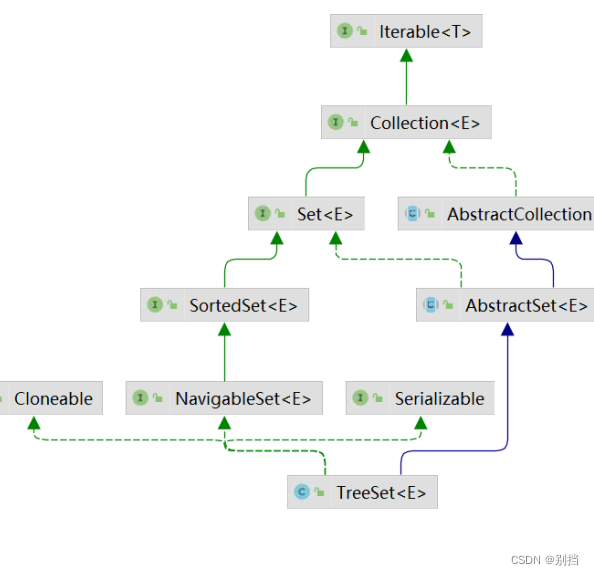
Set接口 extends Collection 特点:无序 唯一
HashSet
TreeSet


Map集合及实现类
Map集合 以key-value存储数据
key:无序唯一
value:无序可重复
key-value 映射关系唯一
1 添加方法
V put(K key, V value) 将指定的值与此映射中的指定键关联(可选操作)。
2 删除
void clear() 从此映射中移除所有映射关系(可选操作)。
V remove(Object key) 如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
boolean remove(Object key, Object value) : 仅当指定的密钥当前映射到指定的值时删除该条目。
3 改
V put(K key, V value) 将指定的值与此映射中的指定键关联(可选操作)。
V replace(K key, V value) 只有当目标映射到某个值时,才能替换指定键的条目。
boolean replace(K key, V oldValue, V newValue) 仅当当前映射到指定的值时,才能替换指定键的条目。
4 查:
boolean containsKey(Object key) 如果此映射包含指定键的映射关系,则返回 true。
boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。
V get(Object key) 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
V getOrDefault(Object key, V defaultValue) : 返回到指定键所映射的值,或 defaultValue如果此映射包含该键的映射。
5 遍历方法
Set<Map.Entry<K,V>> entrySet() 返回此映射中包含的映射关系的 Set 视图。
Set<K> keySet() : 返回此映射中包含的键的 Set 视图。
Collection<V> values() 回此映射中包含的值的 Collection 视图。
forEach()
6 其他方法
boolean isEmpty() : 如果此映射未包含键-值映射关系,则返回 true。
int size() 返回此映射中的键-值映射关系数。
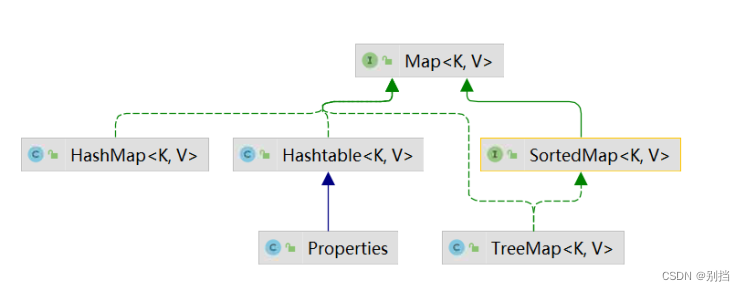
HashMap
HashMap的初始容量16 加载因子0.75扩容为2为2倍
Hashtable初始容量11 加载因子0.75
扩容为2倍+1
HashMap key,value可以为null
HashTable key,value都不可以为null

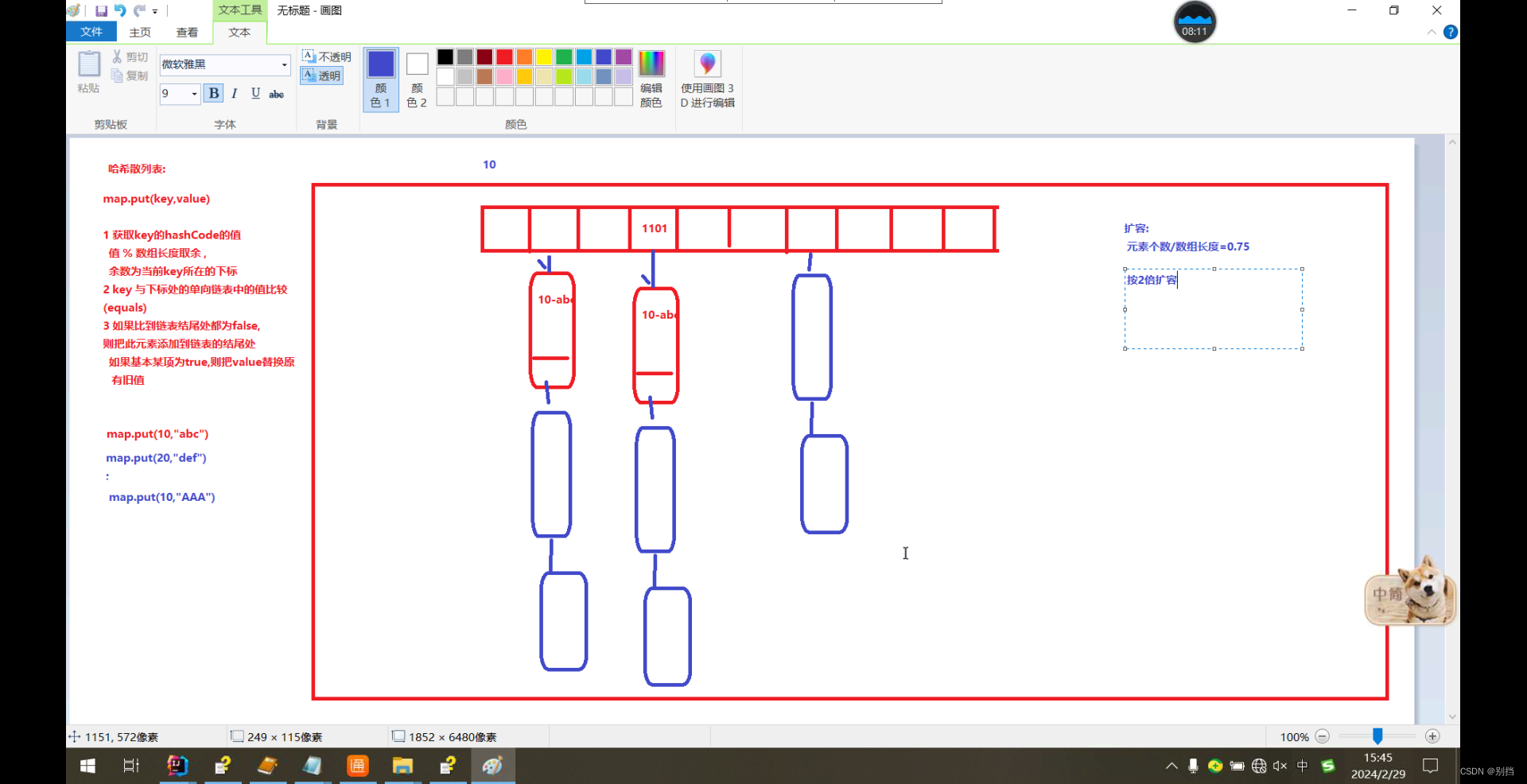
HashMap中的key如何去除重复项?
调用key的hashCode与equals方法
TreeMap:二叉树
左小,右大的方式存储
读取:按中序(左-中-右)
key:通过比较规则,排序并去除重复
注意:key 必须为同一种数据类型的值。不能出现null值