做鞋子的网站东莞公众号开发公司
JAVA项目中如何实现接口调用?
Httpclient
Httpclient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持Http协议的客户端编程工具包,并且它支持HTTP协议最新版本和建议。HttpClient相比传统JDK自带的URL Connection,提升了易用性和灵活性,是客户端发送HTTP请求变得容易,提高了开发的效率。
Okhttp
一个处理网络请求的开源项目,是安卓端最火的轻量级框架,由Square公司贡献,用于代替HttpUrlConnection和Apache HttpClient。OkHttp拥有简洁的API、高校的性能,并支持多种协议(HTTP/2和SPDY)
HttpURLConnection
HttpURLConnection是Java的标准类,它继承自URLConnection,可用于向指定网站发送GET请求、POST请求。HttpURLConection使用比较复杂,不想HttpClient那样容易使用。
RestTemplate WbClient
RestTemplate是Spring提供的用于访问Rest服务的客户端,RestTemplate提供了多种便捷访问远程HTTP服务的方法,能够大大提高客户端的编写效率。
上面介绍的是最常见的几种调用接口的方法,我们下面介绍的方法比上面的更简单、方便,它就是Feign。
什么是Feign
Feign是Nexflix开发的声明式、模板化的HTTP客户端,其灵感来自Retrofit、JAXRS-2.0以及WebSocket。Feign可帮助我们更加便捷、优雅地调用HTTP API。
优势
Feign可以做到

开发者完全感知不到这是远程方法,更感知不到这是个HTTP请求。它像Dubbo一样,consumer直接调用接口方法调用provider,而不是要通过常规的HttpClient构造请求解析返回数据。它解决了让开发者调用远程接口就跟调用本地方法一样,无需关注与远程的交互细节,更无需关注分布式环境开发。(简单地说就是A服务的Service接口去调用别的B服务的Controller接口)
Spring Cloud Alibaba快速整合Opne Feign
复制order-nacos项目,修改项目名为order-openfeign,修改其它配置。引入依赖

新建Feign接口
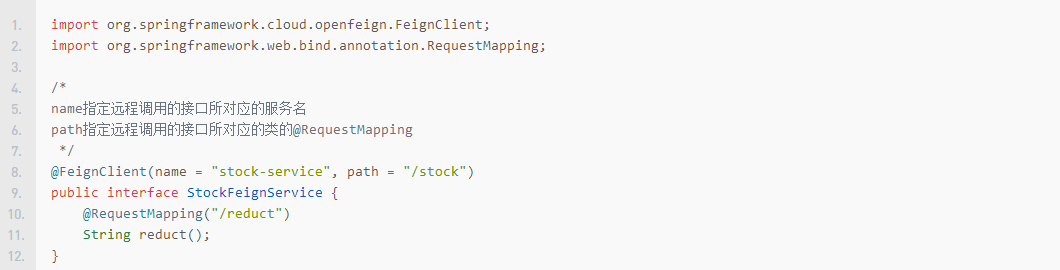
编写订单Controller
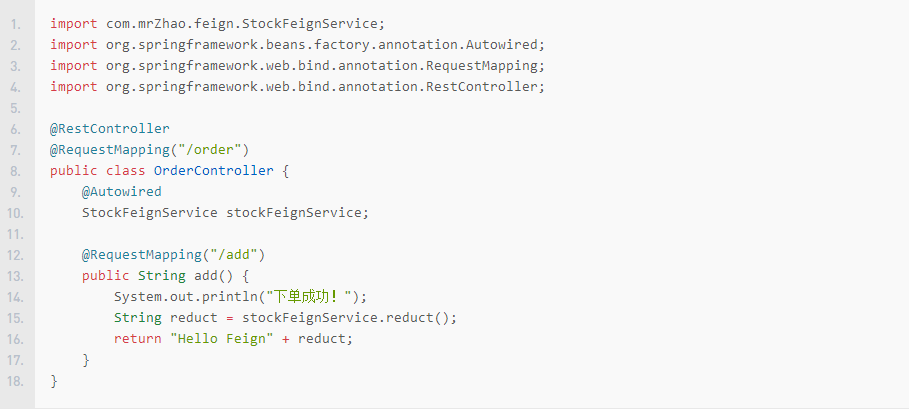
此时stockFeignService下面有一条红色的波浪线,需要在启动类中配置上开启Feign的注解

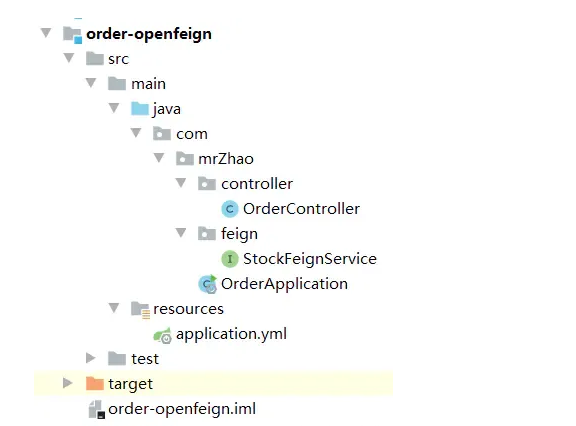
最终项目结构
访问订单接口

日志配置
1.新建product-nacos子项目,controller

application.yml

最终长这样
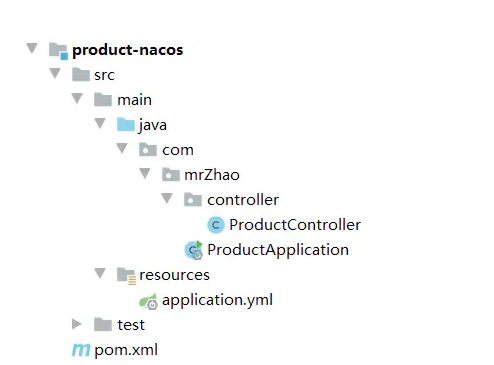
在上文中创建的order-openfeign项目中新建配置类

新建feign接口

更新Controller

application.yml添加配置

启动订单服务、库存服务和商品服务,访问订单接口
日志信息也打印到了控制台

契约配置
Spring Cloud在Feign的基础上做了扩展,使用Spring MVC的疏解来完成Feign的功能。原生的Feign是不支持Spring MVC注解的,如果你想在Spring Cloud中使用原生的注解方式来定义客户端也是可以的,通过配置契约来改变这个配置,Spring Cloud中默认的是SpringMvcContract。
Spring Cloud 1早期版本就是用的原生Feign,随着netflix的停更替换成了Open feign。
修改契约配置,支持Feign原生的注解

$\color{#FF0000}{注意:修改契约配置后,stock-service不再支持springmvc的注解,需要使用Feign原生的注解}
OrderFeignService中配置使用Feign原生的注解

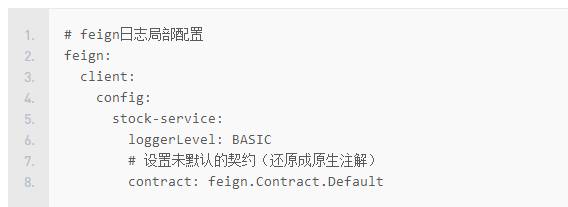
补充:也可以通过yml方式配置契约
超时时间设置
通过 Options 可以配置连接超时时间和读取超时时间,Options 得第一个参数是连接的超时时间(ms),默认值是2s;第二个是请求处理的超时时间(ms),默认是5s。
全局配置

yml中配置


