app网站建设展厅布置摆放设计公司
文章预览:
- 题目
- 翻译
- 算法
- python代码
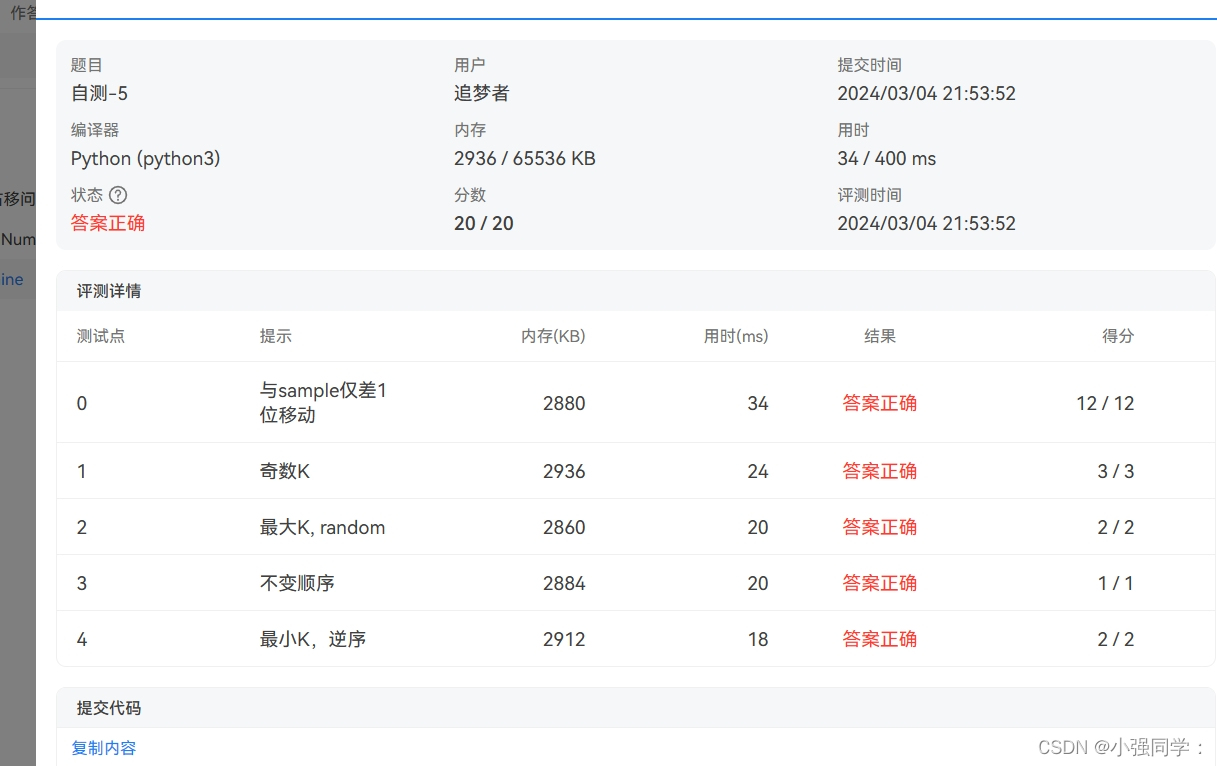
- oj反馈结果
题目

翻译
shuffle是用于随机化一副扑克牌的过程。由于标准的洗牌技术被认为是薄弱的,并且为了避免员工通过不适当的洗牌与赌徒合作的“内部工作”,许多赌场使用了自动洗牌机。你的任务是模拟一台洗牌机。
机器根据给定的随机顺序洗一副54张牌,并重复给定的次数。假设一副牌的初始状态顺序如下:
S1, s2,…向,
H1, h2,…H13,
C1, c2,…、C13、
D1, d2,…D13,
j - 1, J2
其中“S”代表“黑桃”,“H”代表“红心”,“C”代表“梅花”,“D”代表“方块”,“J”代表“小丑”。给定的顺序是[1,54]中不同整数的排列。如果第i个位置的数字是j,这意味着将牌从位置i移动到位置j。例如,假设我们只有5张牌:S3, H5, C1, D13和J2。给定一个洗牌顺序{4,2,5,3,1},结果将是:J2, H5, D13, S3, C1。如果我们再次重复洗牌,结果将是:C1, H5, S3, J2, D13。
输入规格:
每个输入文件包含一个测试用例。对于每种情况,第一行包含一个正整数K(≤20),即重复次数。然后下一行包含给定的顺序。一行中的所有数字用一个空格隔开。
输出规范:
对于每个测试用例,在一行中打印变换结果。所有的牌都用一个空格隔开,并且行尾不能有额外的空格。
算法
解题思路很简单,利用里一个列表将当前需要移动的元素直接存入,最后将列表返回,重复这个操作就可以了
python代码
def shuttle(a,pos):b=len(a)*[None]for i in range(1,55):b[pos[i]]=a[i]return bdef setf(a,fuhao):for i in range(1,14):a.append(fuhao+str(i))
def start(a):setf(a,'S')setf(a,'H')setf(a,'C')setf(a,'D')a.append('J1')a.append('J2')
def shuru():b=input().split()b.insert(0,'0')for i in range(len(b)):b[i]=int(b[i])return b;a=[0]
start(a)
repeat=int(input())
b=shuru()
for i in range(repeat):a=shuttle(a,b)
a.pop(0)
print(' '.join(a))oj反馈结果