关于排版的网站厦门公司注册代理
个人主页 : zxctscl
如有转载请先通知
文章目录
- 1. 前言
- 2. ASCII编码
- 3. unicode
- 4. GBK
- 5. 类型转换
1. 前言
看到string里面还有Template instantiations:

string其实是basic_string<char>,它还是一个模板。
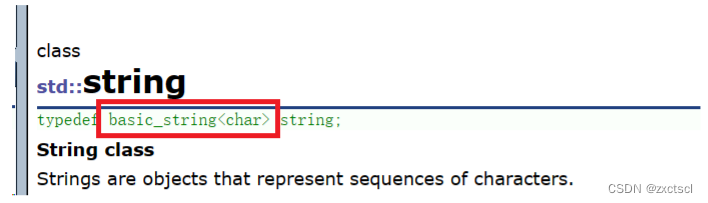
再看看wstring:
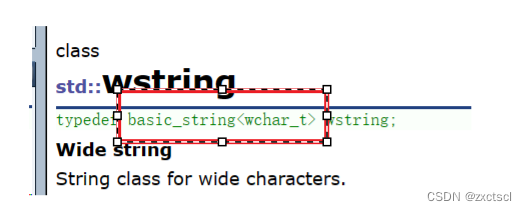
来看看什么是wchar_t?

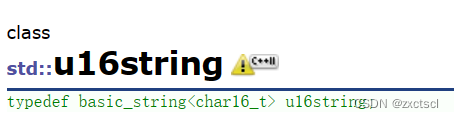
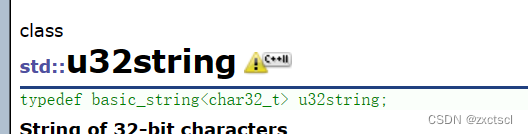
来看看一个字符在不同编码下的大小:
char ch1;wchar_t ch2;char16_t ch3;char32_t ch4;cout << sizeof(ch1) << endl;cout << sizeof(ch2) << endl;cout << sizeof(ch3) << endl;cout << sizeof(ch4) << endl;
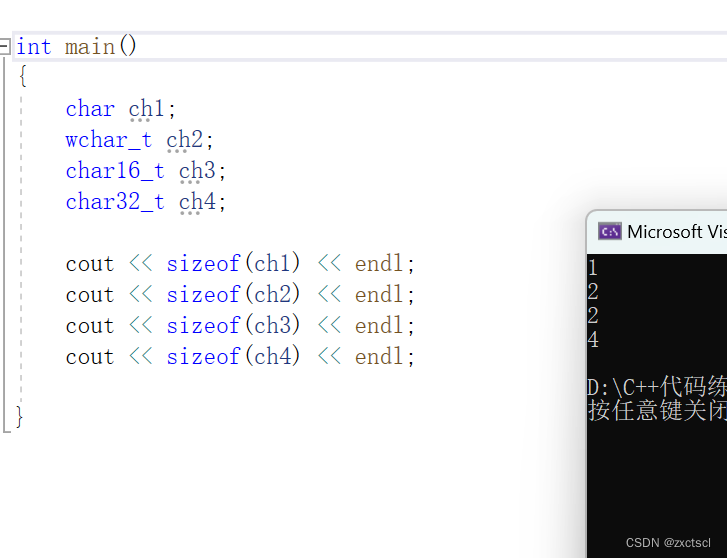
编码就是文字在计算机的存储和表示。
2. ASCII编码
在之前C语言就经常用到ASCII编码:
ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符
在计算机的内存和硬盘里面不可能存字母,它存的只有0和1。
那么一段英文文字,那么怎么存储到计算机中呢?
交换映射,看看ASCII表
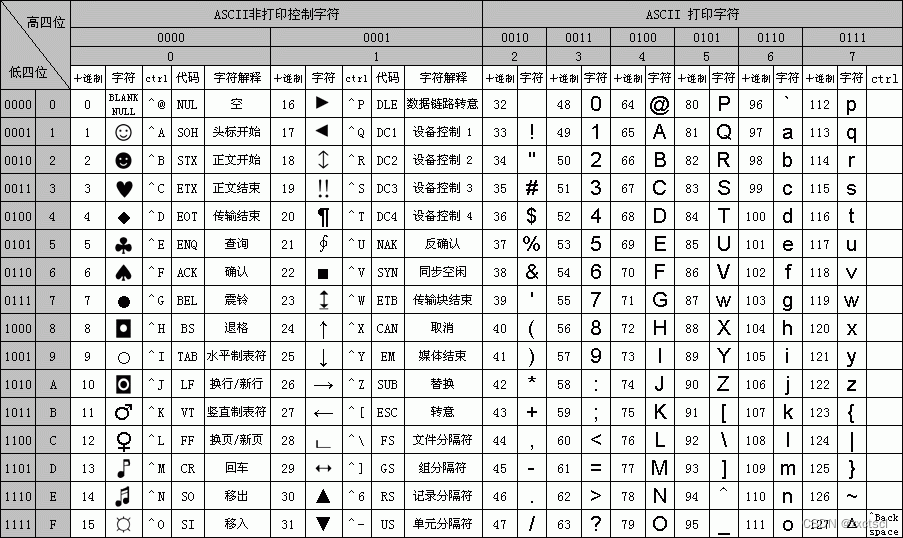
用8个bit就可以表达2^8个值,无符号就是0-255,有符号就是-128-127。
举个例子:
a在内存中存的是ASCII码值是97,也就是16*6+1

而要在显示器上面显示a时,又会去查97对应的是哪个字符,找到后显示出来:

ASCII码值就是那些符号对应的二进制和十进制的值。
所以编码表是符号和这些值映射的表。
像下面给的是整形98,但类型是char,它要查ASCII码,对应的就是b:

3. unicode
但ASCII不能表示中文,想要把中文存在计算机上面,一个字节不够表达中文,那么要怎么表达呢?
统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
在这种语言环境下,不会再有语言的编码冲突,在同屏下,可以显示任何语言的内容,这就是统一码的最大好处。就是将世界上所有的文字用2个字节统一进行编码。那样,像这样统一编码,2个字节就已经足够容纳世界上所有语言的大部分文字了。

在统一码中,汉字“字”对应的数字是23383。在统一码中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的缩写,可以翻译成统一码字符集转换格式,即怎样将统一码定义的数字转换成程序数据。
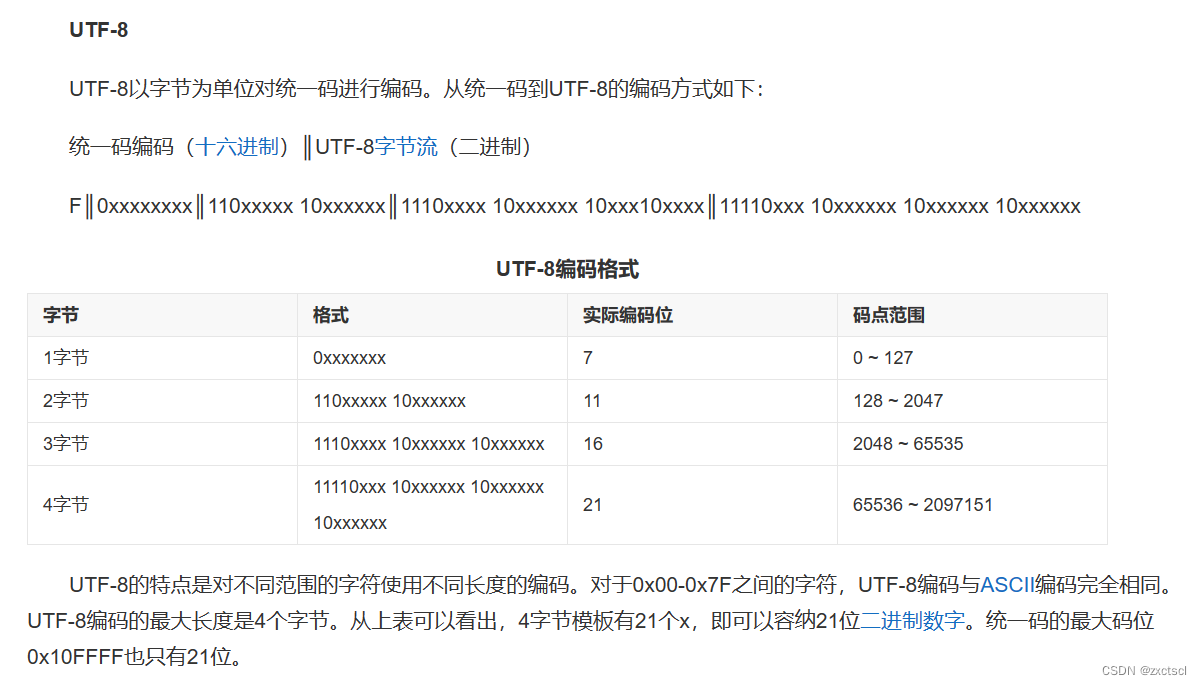
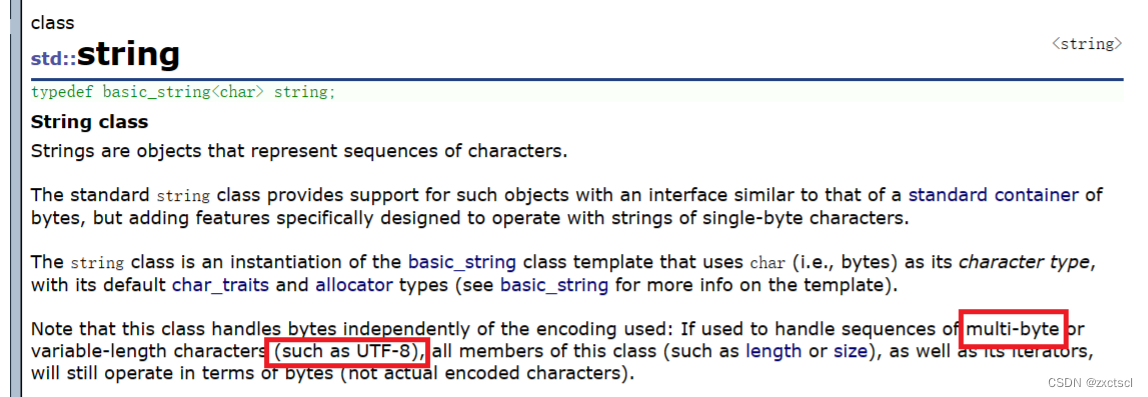
像string就适合UTF-8。


UTF-16
UTF-16编码以16位无符号整数为单位。我们把统一码编码记作U。编码规则如下:
如果U<0x10000,U的UTF-16编码就是U对应的16位无符号整数
为了将一个WORD的UTF-16编码与两个WORD的UTF-16编码区分开来,统一码编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):
D800-DB7F ║ High Surrogates ║ 高位替代
DB80-DBFF ║ High Private Use Surrogates ║ 高位专用替代
DC00-DFFF ║ Low Surrogates ║ 低位替代
这个适合UTF-16:
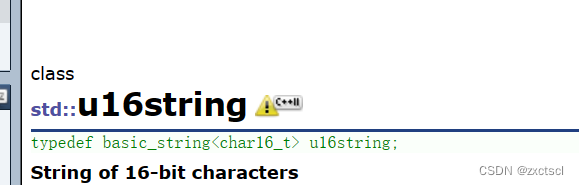

这个适合UTF-32:
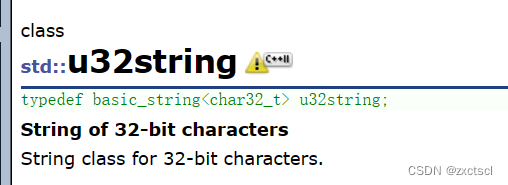
常用的是UTF-8,它能兼容ASCII。
有时候没有初始化时候就会出现这样:

4. GBK
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司、电子工业部科技与质量监督司1995年12月15日联合以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。2000年已被GB18030-2000《信息交换用 汉字编码字符集 基本集的扩充》国家强制标准替代。 2005年GB18030-2005发布,替代了GB18030-2000。

5. 类型转换
把其他类型转换成string类型就用to_string
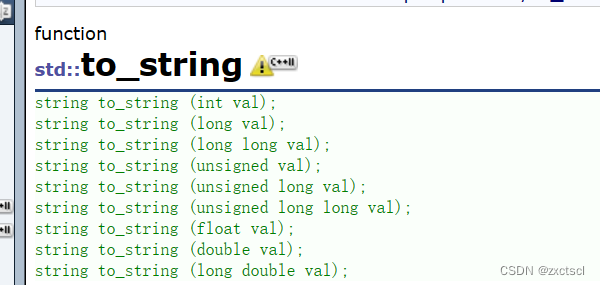
举个例子:
int i = 1234;double d = 11.22;string s1 = to_string(i);string s2 = to_string(d);


stoi把字符串转其他类型。

举个例子:
string s3("45.55");
double d3 = stod(s3);

有问题请指出,大家一起进步!!!