做个个人网站多少钱怎样更新目录wordpress

解决办法:
1.修改注册表。WIN+R呼出开始菜单,在搜索栏中输入 regedit,点击确定。
2.删除项目:\HKEY_CURRENT_USER\Software\ScooterSoftware\Beyond Compare 4\CacheId 根据这个路径找到cacheid 右击删除掉就可以
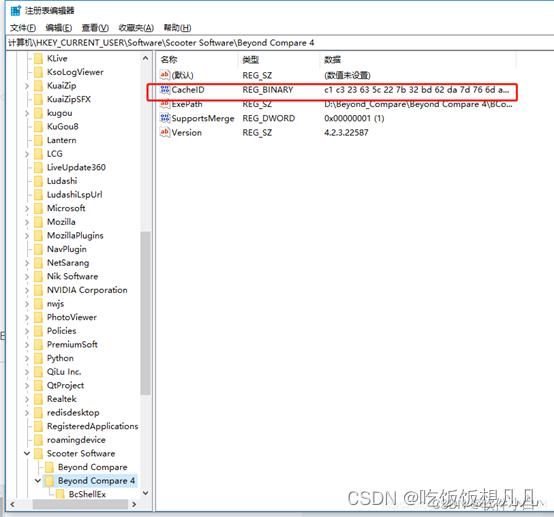
解决办法:
1.修改注册表。WIN+R呼出开始菜单,在搜索栏中输入 regedit,点击确定。
2.删除项目:\HKEY_CURRENT_USER\Software\ScooterSoftware\Beyond Compare 4\CacheId 根据这个路径找到cacheid 右击删除掉就可以