贵州企业网站建设案例忘记wordpress
在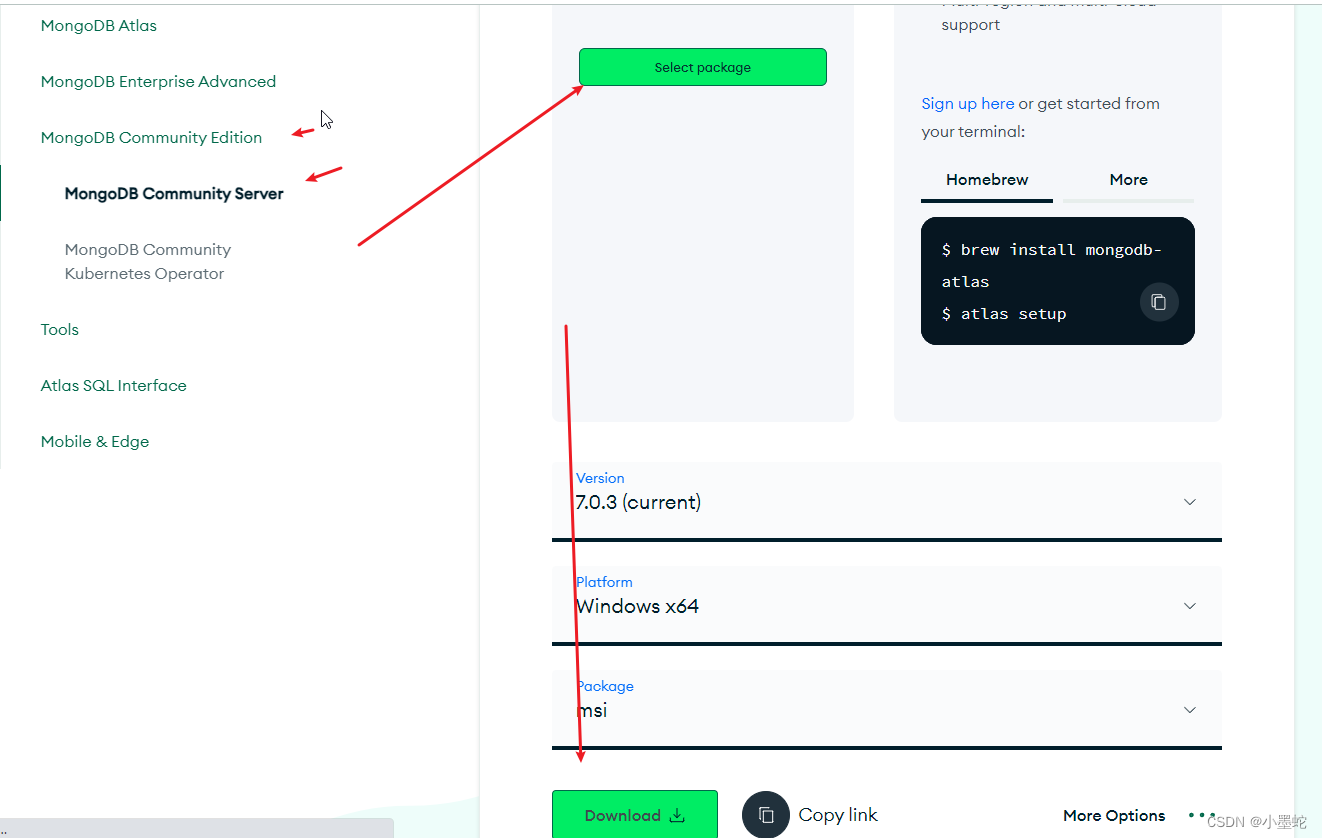
是一个必要的过程,因为MongoDB是一种流行的NoSQL数据库,它可以在大多数操作系统上使用。在本文中,我们将介绍如何在CentOS 8上部署MongoDB。
- MongoDB的下载
您可以从MongoDB官网上下载最新的MongoDB版本。使用以下命令下载MongoDB:
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-4.4.6.tgz
- MongoDB的安装和部署
下载完成后,您需要解压MongoDB文件:
tar -zxvf mongodb-linux-x86_64-4.4.6.tgz
然后,将解压后的文件夹移动到/usr/local目录下:
mv mongodb-linux-x86_64-4.4.6 /usr/local/mongodb
接下来,您需要创建MongoDB的数据目录和日志目录:
mkdir -p /data/db
mkdir -p /var/log/mongodb
现在,您需要将MongoDB的二进制文件添加到系统路径中:
echo 'export PATH=/usr/local/mongodb/bin:$PATH' >> /etc/profile
source /etc/profile
- MongoDB的测试
在安装和部署MongoDB之后,您需要测试MongoDB是否可以正常运行。您可以使用以下命令启动MongoDB:
mongod --dbpath /data/db --logpath /var/log/mongodb/mongod.log --fork
这将启动MongoDB,并将日志输出到/var/log/mongodb/mongod.log文件中。您可以使用以下命令检查MongoDB是否正在运行:
ps aux | grep mongod
如果MongoDB正在运行,您应该看到类似于以下内容的输出:
mongodb 1234 0.0 0.5 12345 6789 ? Ssl 12:34 0:00 mongod --dbpath /data/db --logpath /var/log/mongodb/mongod.log --fork
- 基础的使用
MongoDB的基本使用方法如下:
- 启动MongoDB客户端:
mongo
- 创建数据库:
use mydb
- 创建集合:
db.createCollection("mycollection")
- 插入文档:
db.mycollection.insert({"name": "John"})
- 查找文档:
db.mycollection.find()
- 更新文档:
db.mycollection.update({"name": "John"}, {"name": "Jane"})
- 删除文档:
db.mycollection.remove({"name": "Jane"})
总结:
以上是在CentOS 8上部署MongoDB的过程,MongoDB是一个非常流行的NoSQL数据库,它可以在大多数操作系统上使用。在本文中,我们介绍了如何在CentOS 8上下载、安装和部署MongoDB,并介绍了MongoDB的基本使用方法。
**
注意
**
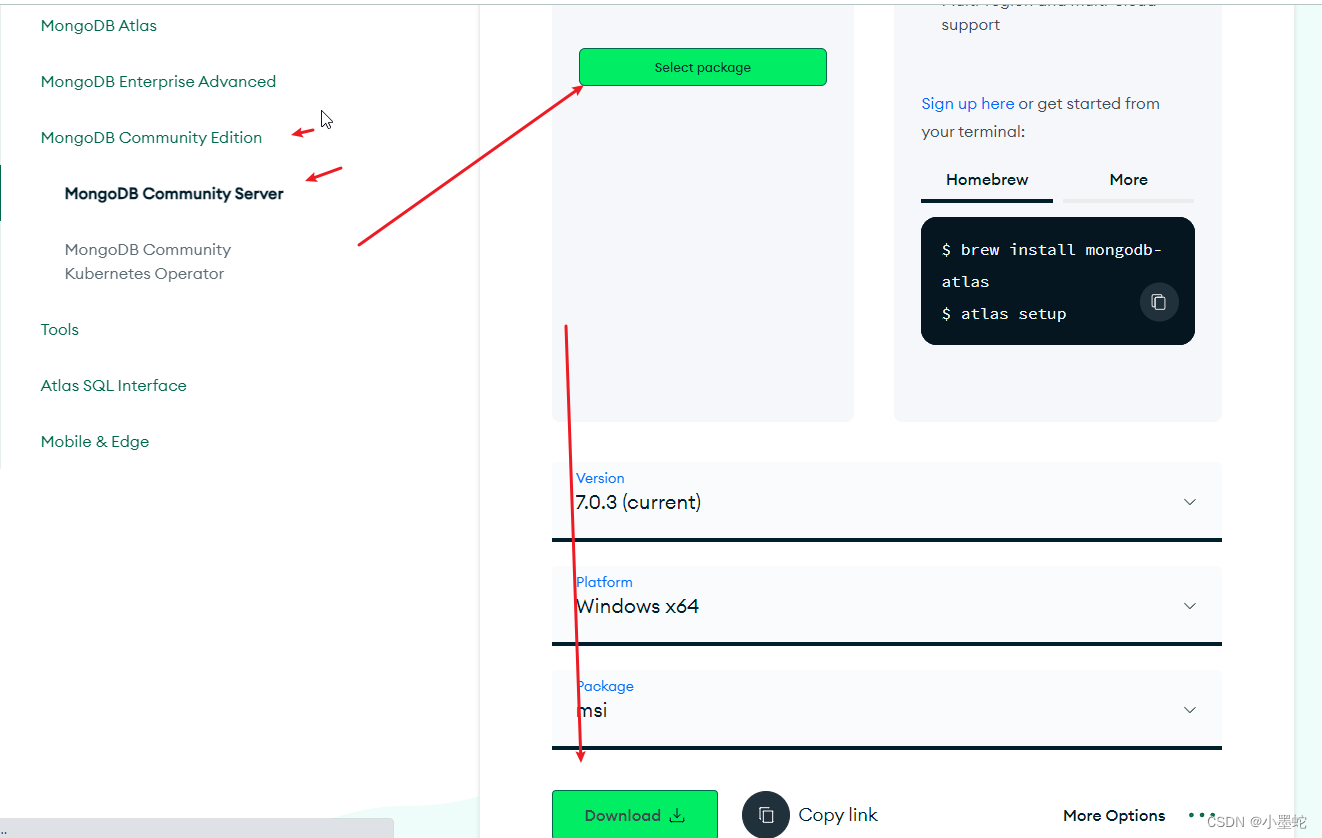
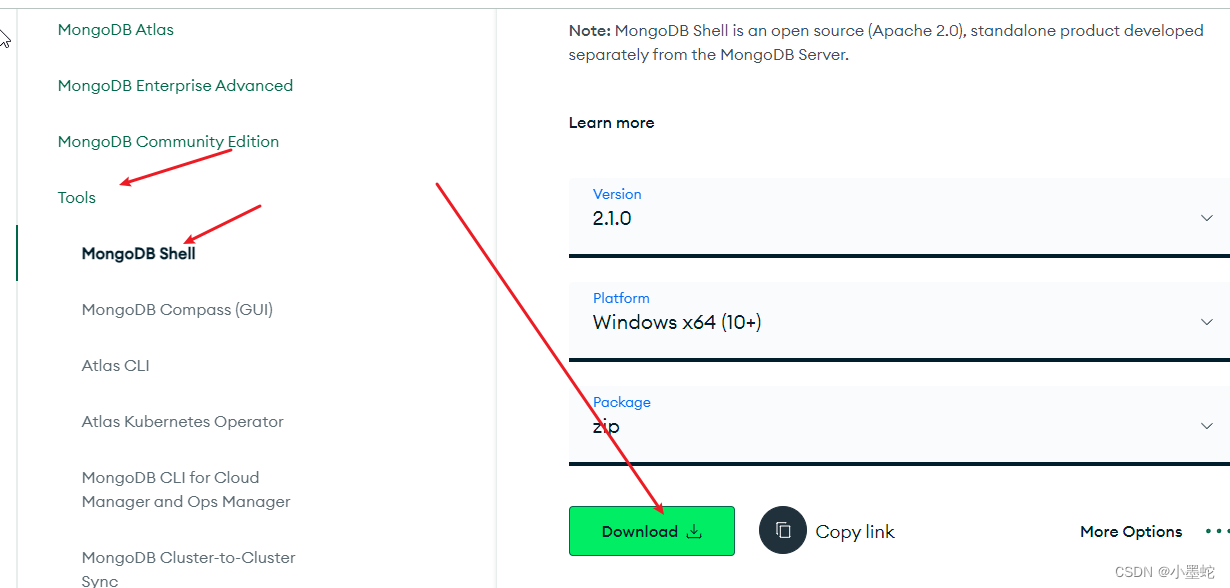
目前mongodb的最新版中可能需要分别安装
一个是mongodb的server
一个是mongodb的shell
下载地址
https://www.mongodb.com/try/download/community
https://www.mongodb.com/try/download/community
mongodb shell
mongodb server