网上请人做软件的网站ctoc网站有哪些
elasticsearch-head 是一款专门针对于 elasticsearch 的客户端工具,用来展示数据。
elasticsearch-head 是基于 JavaScript 语言编写的,可以使用 Nodejs 下的包管理器 npm 部署。
1 安装Nodejs
nodejs下载地址: https://nodejs.org/en/download/
下载后上传到服务器,并解压。
进入解压的文件夹,可以查看版本:
./bin/node -v
建立 node 软连接,变为全局变量:
ln -s /home/myroot/Desktop/Vue/node-v16.16.0-linux-x64/bin/node /usr/local/bin/
如出现报错:
ln: failed to create symbolic link ‘/usr/local/bin/node’: Permission denied
则需要修改 /usr/local/bin/node 的权限:
sudo chmod 777 /usr/local/bin/node
Linux权限相关的知识参见:https://mp.weixin.qq.com/s/r4H_d4Skm1Ni5sfKoQcp2A
修改权限后,再一次运行建立软连接的命令。
然后查看 node 是否成功设为全局变量:
node -v
若输出为版本号,表示成功。
同样的,建立 npm 软连接,设为全局变量:
ln -s /home/myroot/Desktop/Vue/node-v16.16.0-linux-x64/bin/npm /usr/local/bin/
查看是否成功:
npm -v
2 安装elasticsearch-head
2.1 安装
下载地址:https://github.com/mobz/elasticsearch-head/releases
下载后上传到服务器并解压。
进入安装目录:
cd elasticsearch-head-5.0.0
执行命令安装:
npm install
启动服务:
npm run start
或者后台启动:
nohup npm run-script start &
出现以下输出,说明启动成功:
elasticsearch-head@0.0.0 start
grunt serverRunning “connect:server” (connect) task
Waiting forever…
Started connect web server on http://localhost:9100
2.2 访问Head服务
然后在本机访问: http://localhost:9100/
或者其他机器访问:http://192.168.191.129:9100/(192.168.191.129为该服务器的地址)
elasticsearch-head服务访问成功:
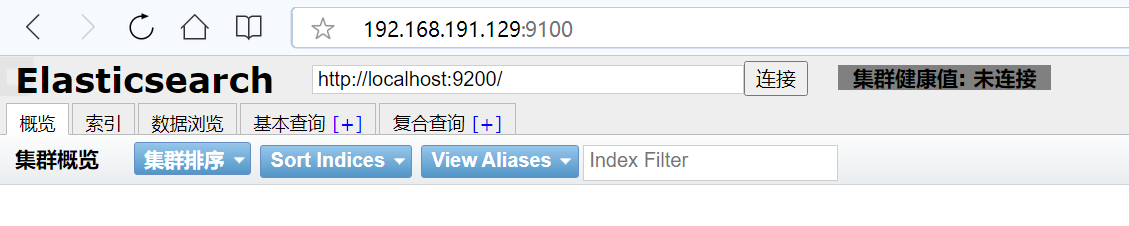
img src=“./0img/ElasticSearch1.png” width=“700px” />
2.3 使用Head插件访问ES
要允许跨域,需要修改elasticsearch-8.0.0/config/elasticsearch.yml文件,添加如下内容:
http.cors.enabled: true
http.cors.allow-origin: "*"
然后点击Head服务网页中的“链接”按钮:
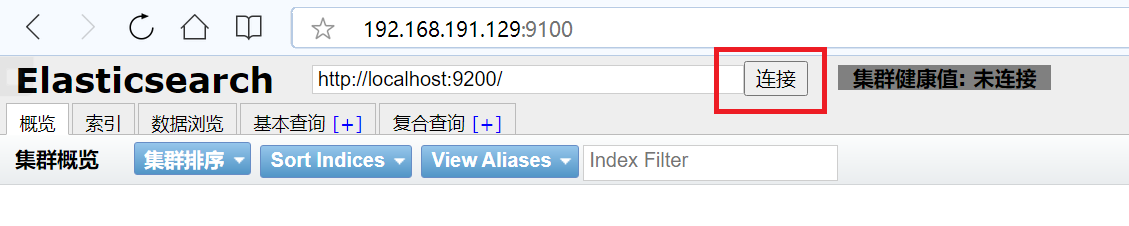
img src=“./0img/ElasticSearch2.png” width=“700px” />
连接成功:
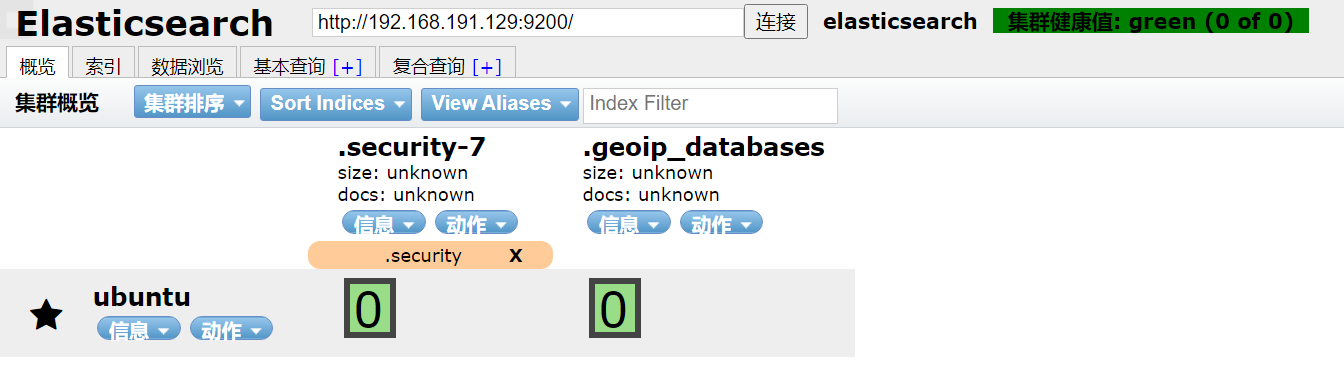
img src=“./0img/ElasticSearch3.png” width=“700px” />
学习更多编程知识,请关注我的公众号:
代码的路