手机网站创建shopify是什么平台
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、下载CIC Flowmeter
- 二、安装java、maven、gradle和IDEA
- 1.java 1.8
- 2.maven
- 3.gradle
- 4.IDEA
- 三、CICFlowMeter-master使用
- 四、流量特征
- 1.含义
- 2.获取
前言
配了一整天环境终于配好了
2023.3.27亲测有效
如果有什么地方写的不清楚可以礼貌提问
知无不言 但我不一定知道 😃
(ps 在上班回消息慢请见谅
一、下载CIC Flowmeter
https://github.com/ahlashkari/CICFlowMeter

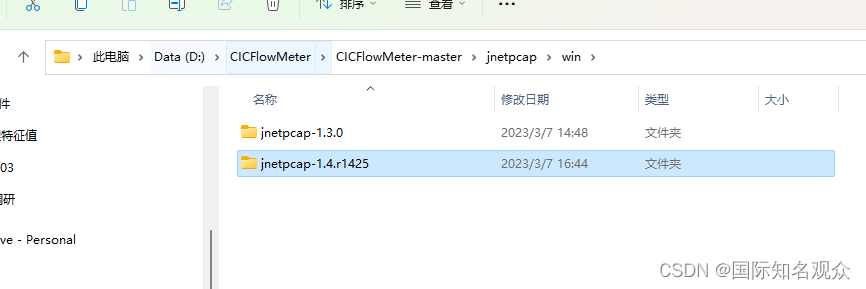
下载完后去https://sourceforge.net/projects/jnetpcap/下载最新的jNetPcap,解压后把原文件中的CICFlowMeter\CICFlowMeter-master\jnetpcap\win\jnetpcap-1.4.r1425替换掉
二、安装java、maven、gradle和IDEA
1.java 1.8
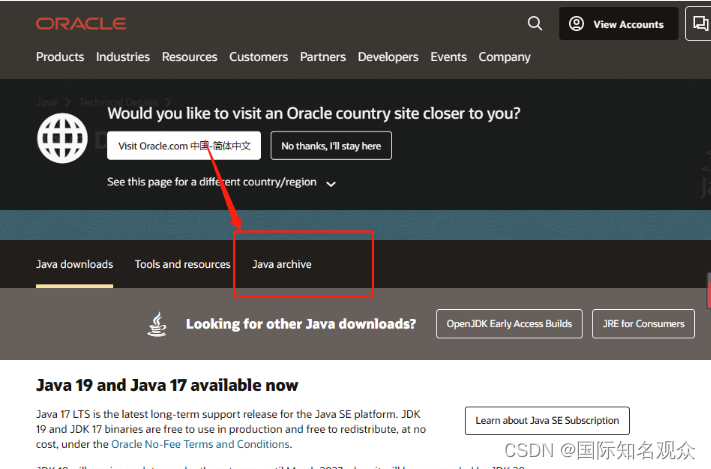
①打开官网:https://www.oracle.com/java/technologies/downloads/ ,选择 java archive:
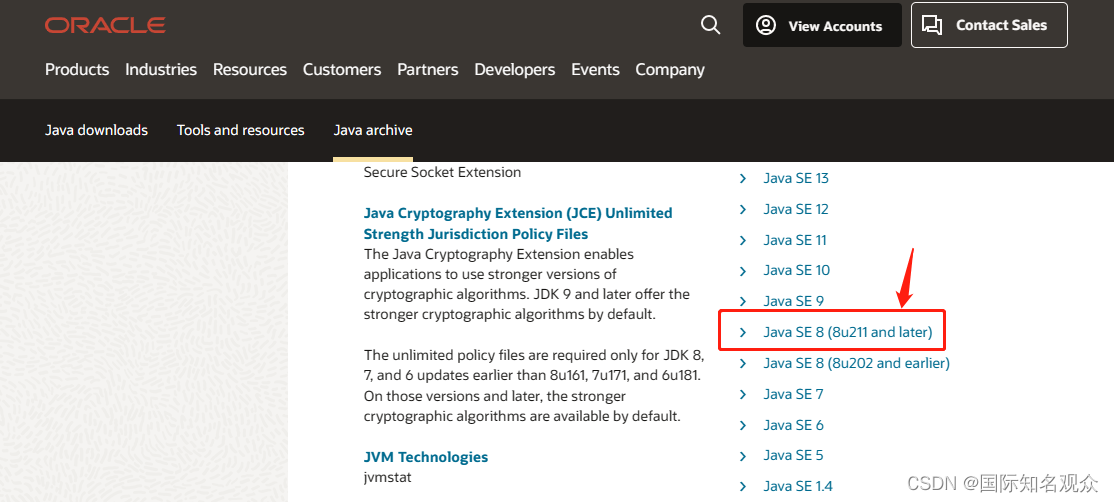
②选择 Java SE 8 (8u211 and later):
③下载Windows x64 Installer :

④后面就是点击exe,一直下一步完成安装,注意选择路径中不能有中文:

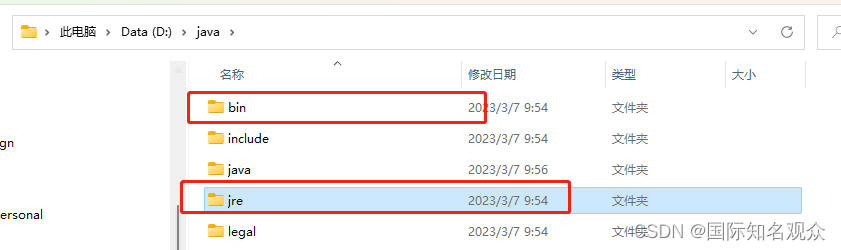
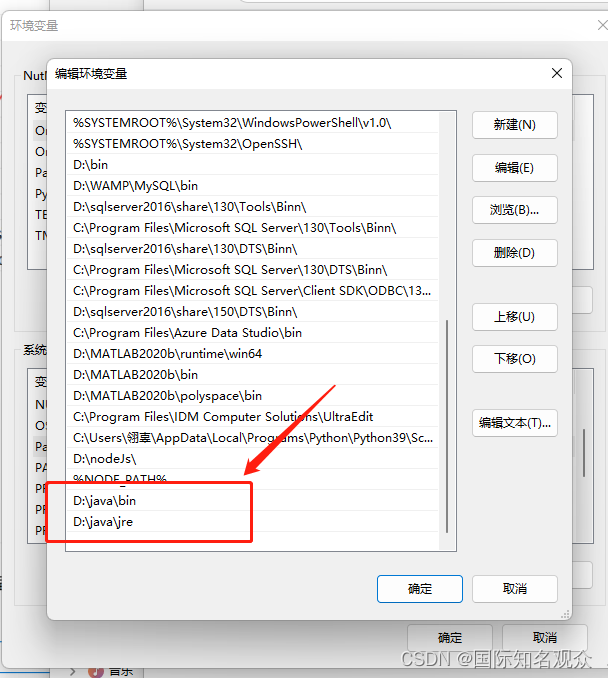
⑤找到安装目录中bin和jre的路径,复制并加入系统变量path中:
D:\java\bin
D:\java\jre
⑥重新打开cmd输入java -version查看验证:
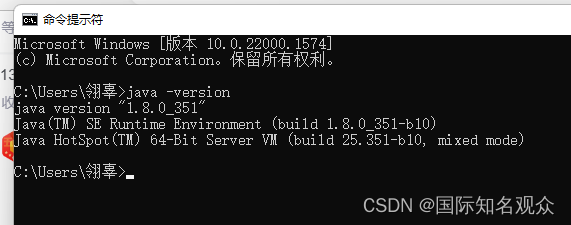
看到版本号1.8,成功!
2.maven
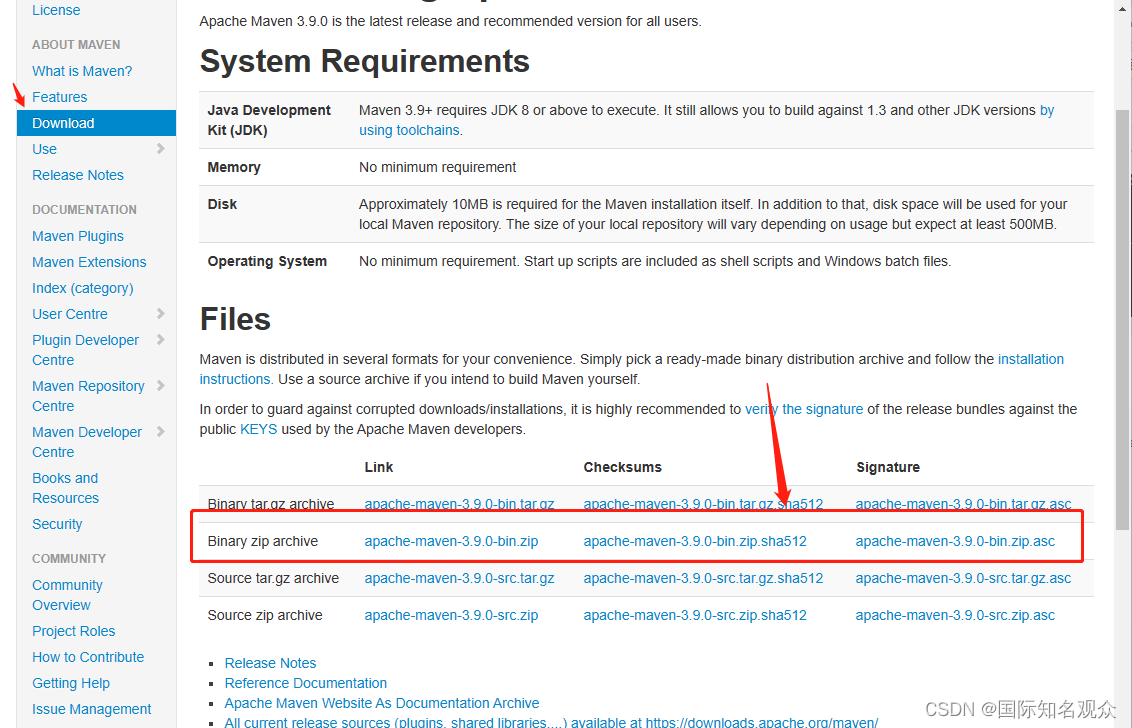
①打开官网链接下载apache-maven-3.9.0-bin.zip:
网址:https://maven.apache.org/download.cgi
下载完成后解压到没有中文的路径下即可

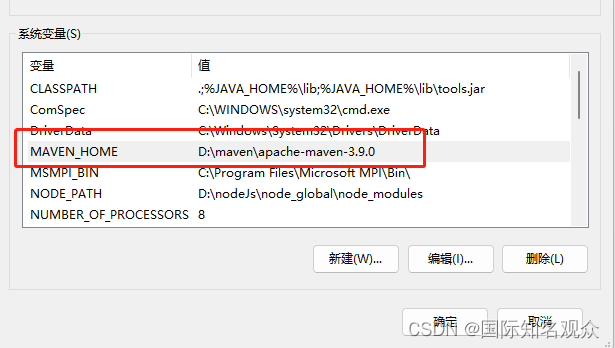
②配置环境变量:
在系统变量中新建,变量名:MAVEN_HOME,变量值:maven文件夹路径:
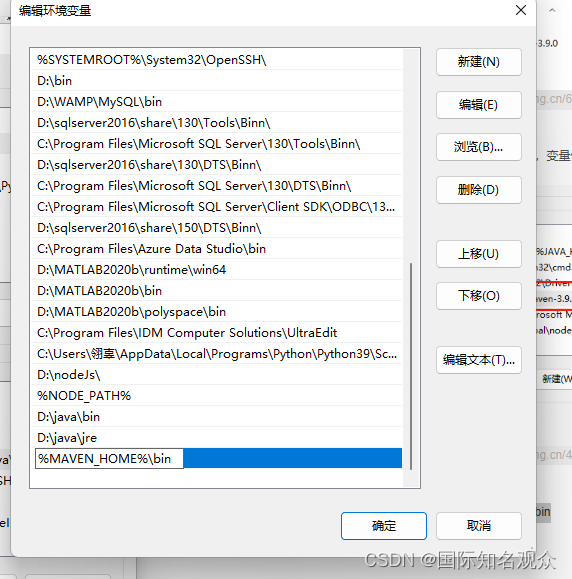
在系统变量path中新建:%MAVEN_HOME%\bin
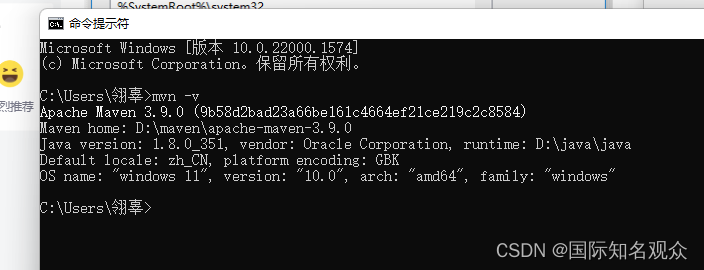
③打开cmd验证:mvn -v
,显示版本号,成功!
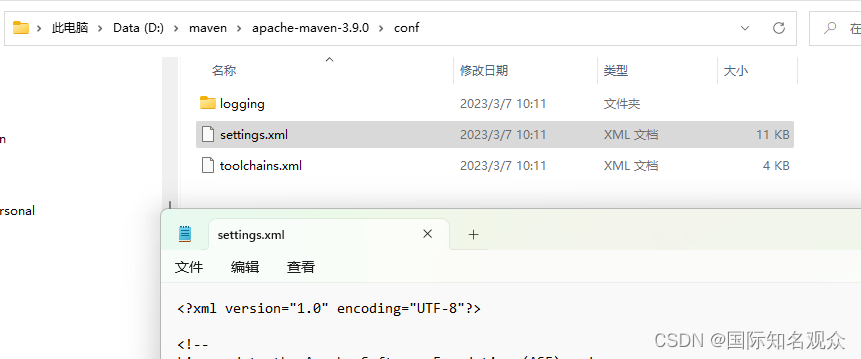
④配置本地仓库
记事本打开D:\maven\apache-maven-3.9.0\conf:
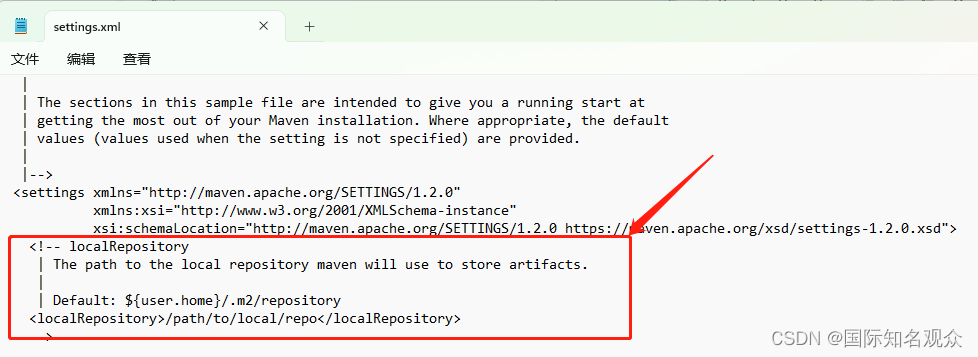
修改第53行:这里写你的本地仓库的路径
3.gradle
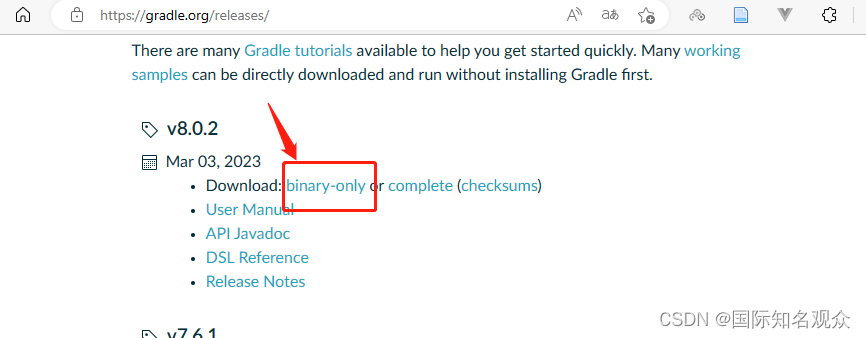
①打开网址https://gradle.org/releases/ 选择一个版本下载binary-only,然后解压至某一个无中文路径下
②配置环境变量:环境变量新建GRADLE_HOME,变量值:gradle文件夹路径(D:\gradle\gradle-8.0.2)
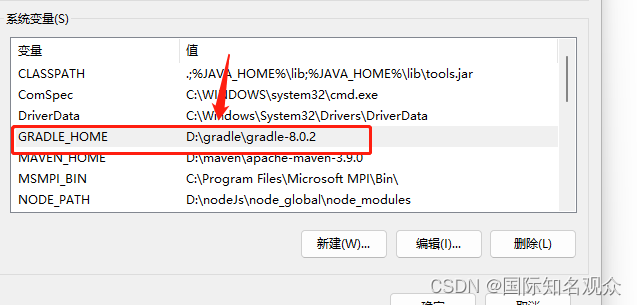
在系统变量path中新建:%GRADLE_HOME%\bin
③重新打开cmd,输入 gradle -v 。显示如下说明配置成功。(显示的有点慢就耐心等一下~

4.IDEA
①下载地址:https://www.jetbrains.com/idea/download/#section=windows,下载社区版
②下载完后点击exe开始安装,先next,然后选择安装路径:
勾选建立桌面快捷方式:
之后默认即可,完成:
③打开,初次使用选择不导入:
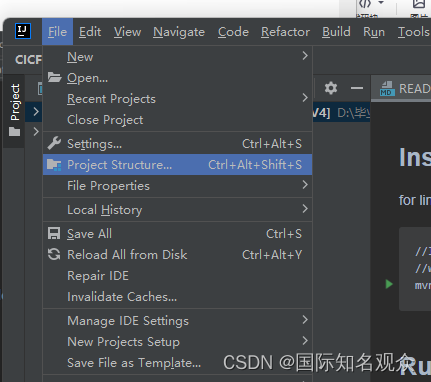
④设置jdk
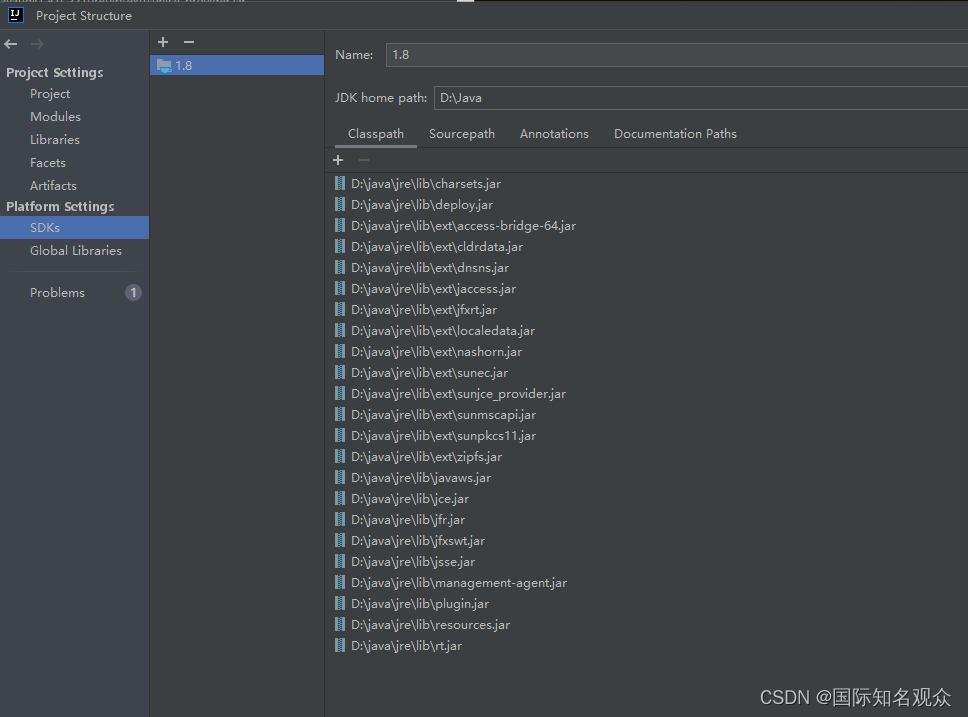
打开file、project structure
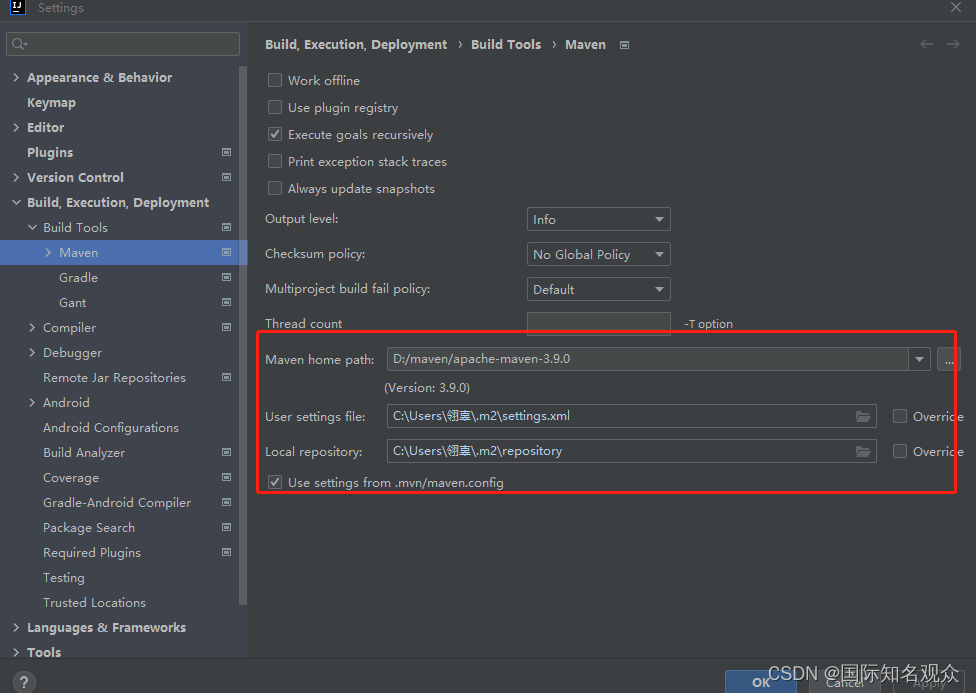
⑤设置maven:打开file、setting,搜索maven:
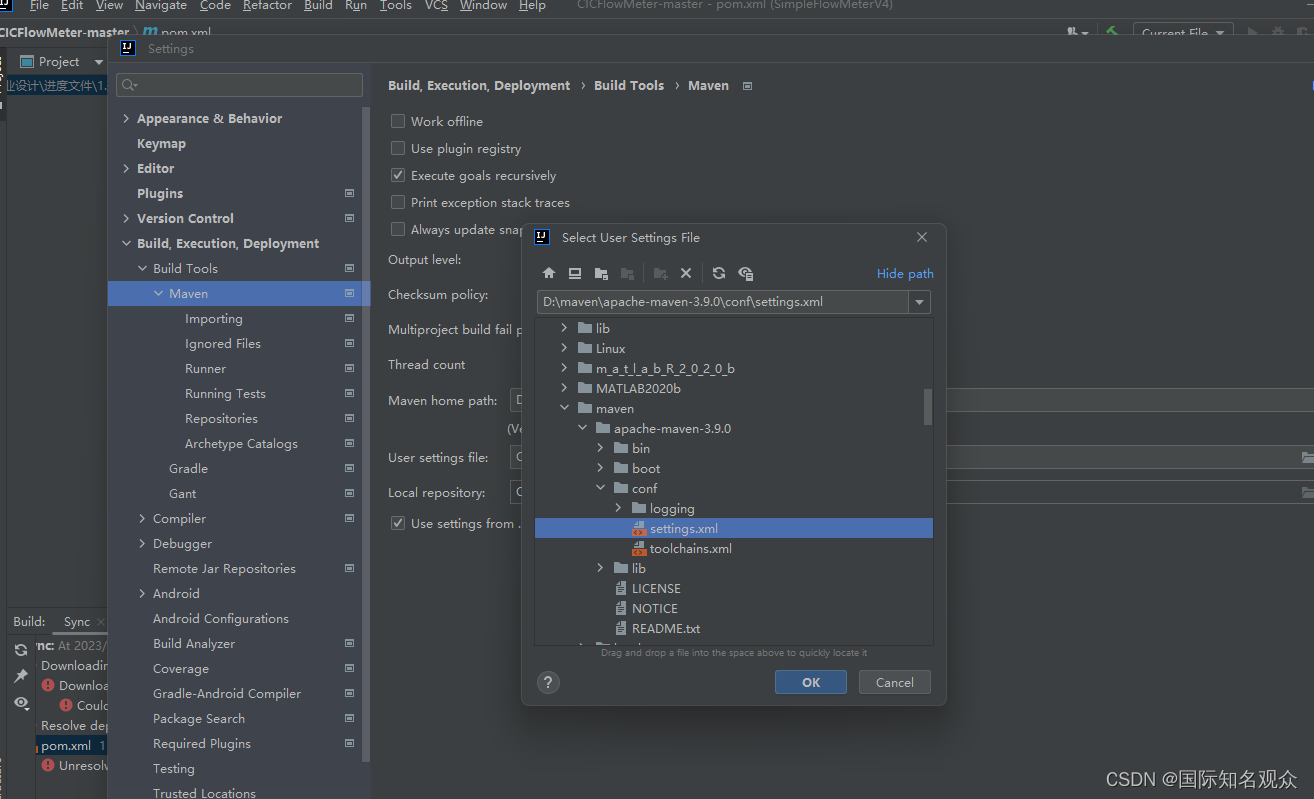
修改地址:

⑥设置gradle:打开file,setting,搜索gradle:
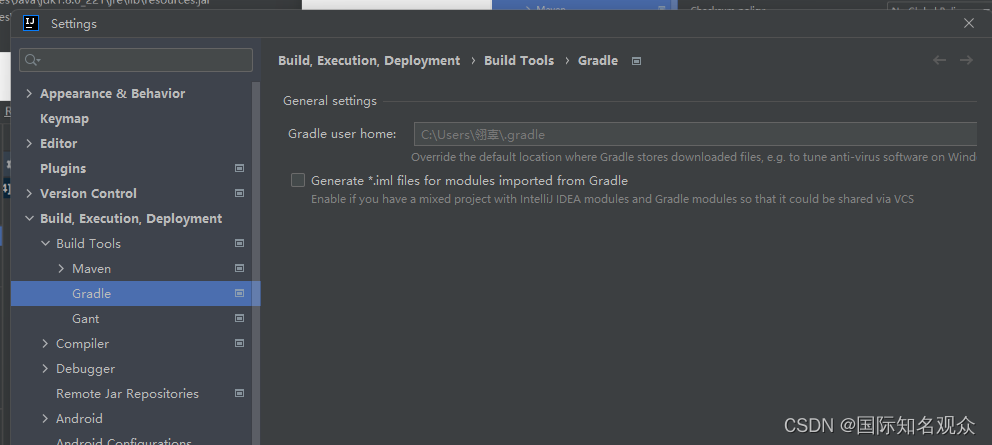
⑦Jnetpcap设置:
打开file、project structure、modules、dependencies:
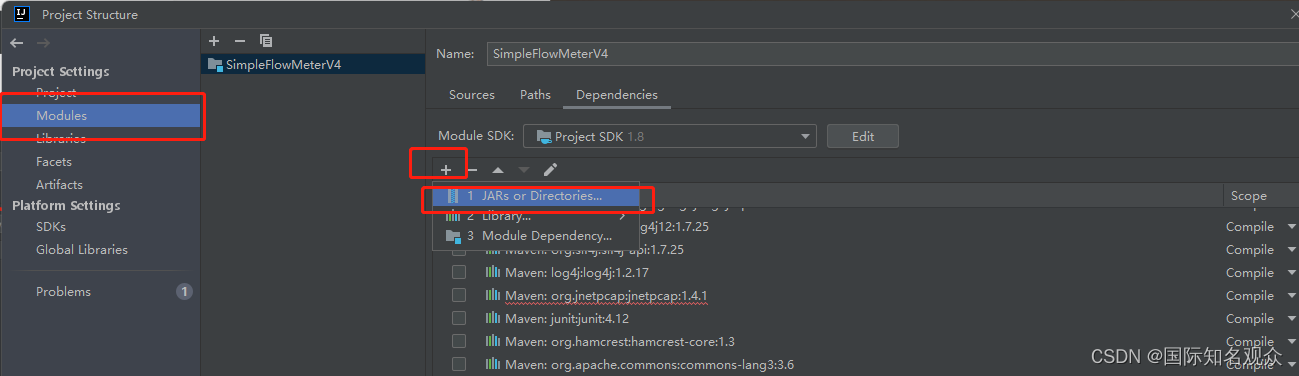
点击+,导入jnetpcap.dll与jnetpcap.jar文件,路径如图所示

把对勾打上

三、CICFlowMeter-master使用
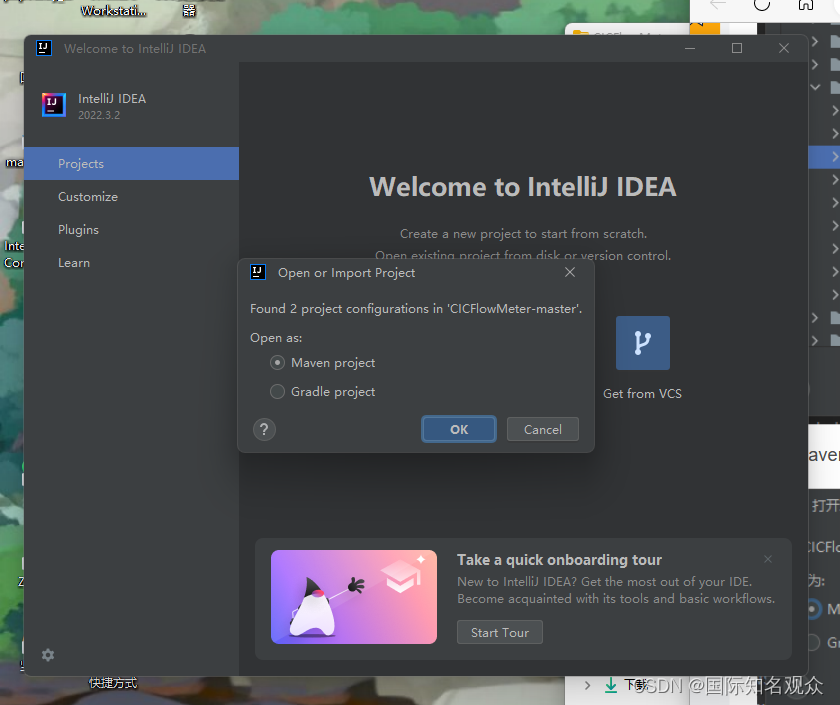
①使用IDEA打开CICFlowMeter-master文件夹,注意一定要放在没有中文的路径下!!!!!,选择Maven项目
②将CICFlowMeter-master\jnetpcap\win\jnetpcap-1.4.r1425\jnetpcap.jar复制到CICFlowMeter-master根目录下
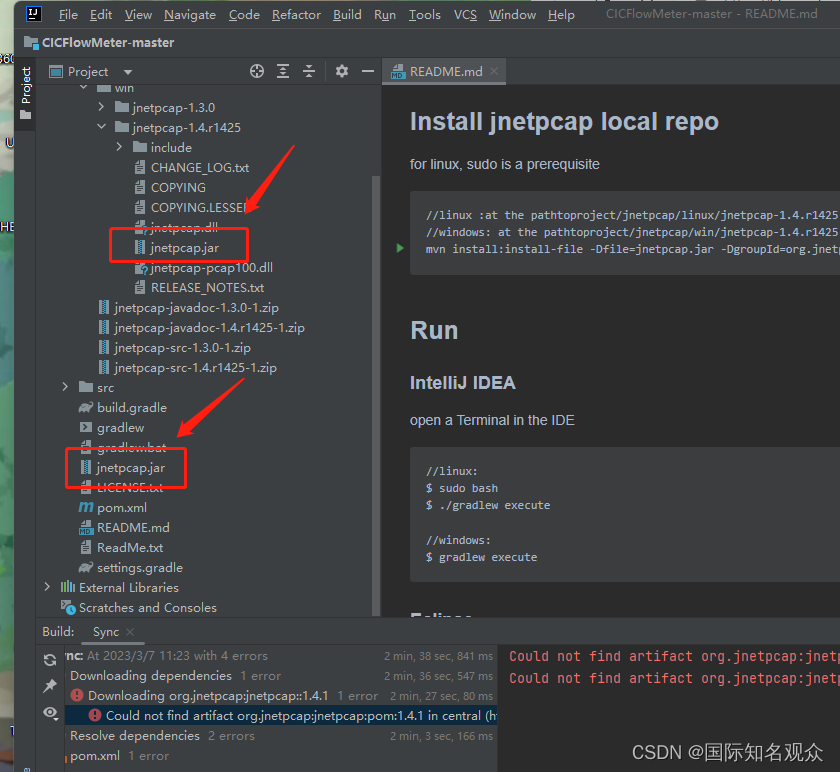
先把jar包放在本地
D:>cd CICFlowMeter\CICFlowMeter-master
D:\CICFlowMeter\CICFlowMeter-master>mvn install:install-file “-Dfile=jnetpcap.jar” “-DgroupId=org.jnetpcap” “-DartifactId=jnetpcap” “-Dversion=1.4.1” “-Dpackaging=jar”
成功:
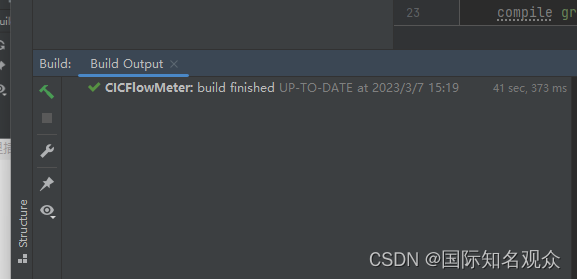
执行:gradlew execute

成功:
根据需要选择离线数据集或实时数据,本次测试使用离线数据pcap文件:
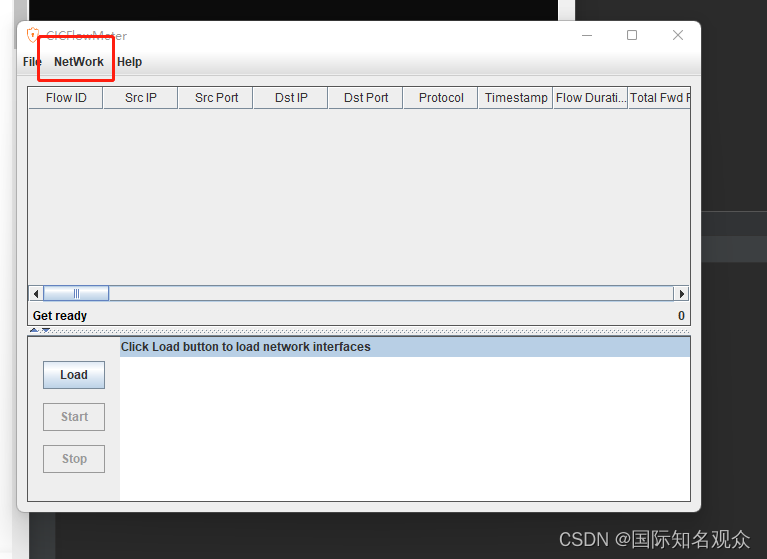
添加pcap文件和输出文件地址,点击ok开始运行:
此时点击OK没有反应,去https://sourceforge.net/projects/jnetpcap/下载最新的jNetPcap,然后把原文件中的
运行结束后输出路径下会产生“输入文件名_flow.csv”文件,内容如下所示:
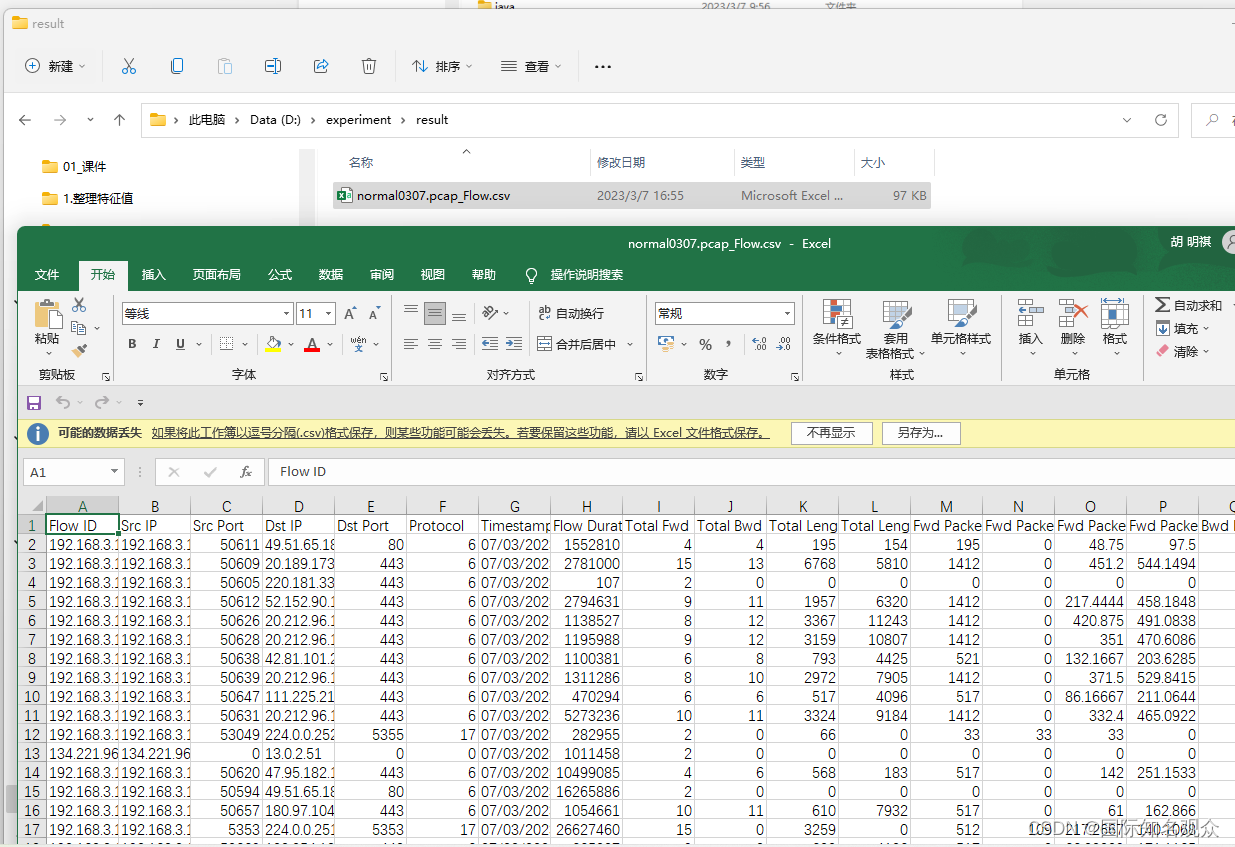
实时使用需要先找到注册表,
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Interfaces
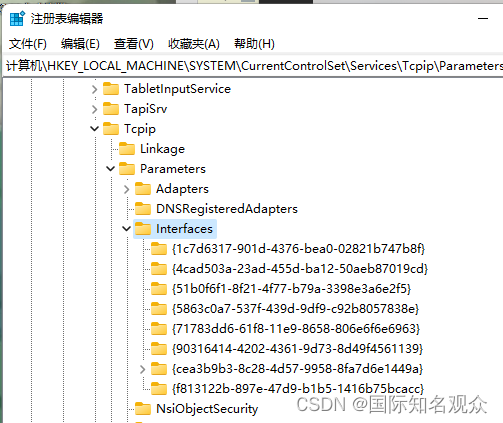
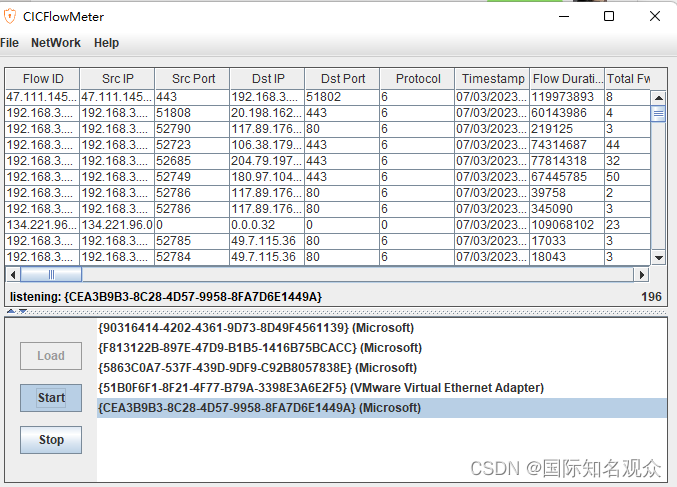
查看可用的网卡参数,然后抓包即可,开始之后需要等待一会儿
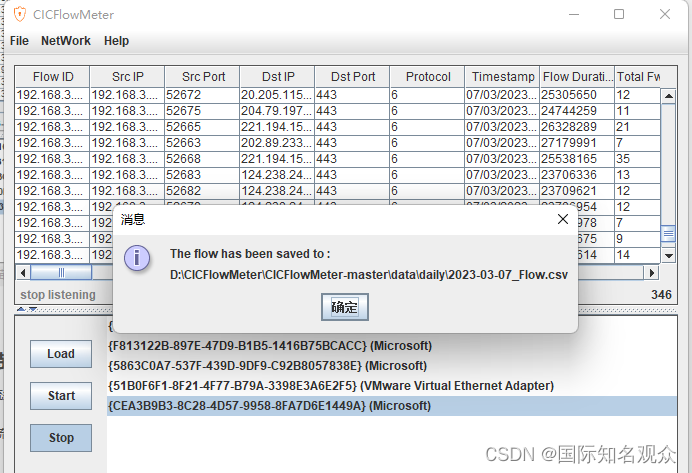
停止之后,csv自动保存 D:\CICFlowMeter\CICFlowMeter-master\data\daily
四、流量特征
1.含义
(1)fl_dur - - > 流持续时间
(2)tot_fw_pk(流出方向?) - - > 在正向上包的数量
(3)tot_bw_pk - - > 在反向上包的数量
(4)tot_l_fw_pkt - - > 正向数据包的总大小
(5)fw_pkt_l_max - - > 包在正向上的最大大小
(6)fw_pkt_l_min - - > 包在正向上的最小大小
(7)fw_pkt_l_avg - - > 数据包在正向的平均大小
(8)fw_pkt_l_std - - > 数据包正向标准偏差大小
(9)Bw_pkt_l_max - - > 包在反向上的最大大小
(10)Bw_pkt_l_min - - > 包在反向上的最小大小
(11)Bw_pkt_l_avg - - > 数据包在反向的平均大小
(12)Bw_pkt_l_std - - > 数据包反向标准偏差大小
(13)fl_byt_sv - - > 流字节率,即每秒传输的数据包字节数
(14)fl_pkt_s - - > 流包率,即每秒传输的数据包数
(15)fl_iat_avg - - > 两个流之间的平均时间
(16)fl_iat_std - - > 两个流之间标准差
(17)fl_iat_max - - > 两个流之间的最大时间
(18)fl_iat_minv - - > 两个流之间的最小时间
(19)fw_iat_tot - - > 在正向发送的两个包之间的总时间
(20)fw_iat_avg - - > 在正向发送的两个包之间的平均时间
(21)fw_iat_std - - > 在正向发送的两个数据包之间的标准偏差时间
(22)fw_iat_max - - > 在正向发送的两个包之间的最大时间
(23)fw_iat_min - - > 在正向发送的两个包之间的最小时间
(24)bw_iat_tot - - > 反向发送的两个包之间的总时间
(25)bw_iat_avg - - > 反向发送的两个数据包之间的平均时间
(26)bw_iat_std - - > 反向发送的两个数据包之间的标准偏差时间
(27)bw_iat_max - - > 反向发送的两个包之间的最大时间
(28)bw_iat_min - - > 反向发送的两个包之间的最小时间
(29)fw_psh_flag - - > 在正向传输的数据包中设置PSH标志的次数(UDP为0)
(30)bw_psh_flag - - > 在反向传输的数据包中设置PSH标志的次数(UDP为0)
(31)fw_urg_flag - - > 在正向传输的数据包中设置URG标志的次数(UDP为0)
(32)bw_urg_flag - - > 反方向数据包中设置URG标志的次数(UDP为0)
(33)fw_hdr_len - - > 用于前向方向上的包头的总字节数
(34)bw_hdr_len - - > 用于后向方向上的包头的总字节数
(35)fw_pkt_s - - > 每秒前向包的数量
(36)bw_pkt_s - - > 每秒后向包的数量
(37)pkt_len_min - - > 流的最小长度
(38)pkt_len_max - - > 流的最大长度
(39)pkt_len_avg - - > 流的平均长度
(40)pkt_len_std - - > 流长度的方差
(41)pkt_len_va - - > 最小包到达间隔时间
(42)fin_cnt - - > 带有FIN的包数量
(43)syn_cnt - - > 带有SYN的包数量
(44)rst_cnt - - > 带有RST的包数量
(45)pst_cnt - - > 带有PUSH的包数量
(46)ack_cnt - - > 带有 ACK的包数量
(47)urg_cnt - - > 带有URG的包数量
(48)cwe_cnt - - > 带有CWE的包数量
(49)ECE - - > 带有ECE的包数量
(50)down_up_ratio - - > 下载和上传的比例
(51)pkt_size_avg - - > 数据包的平均大小
(52)fw_seg_avg - - > 观察到的前向方向上数据包的平均大小
(53)bw_seg_avg - - > 观察到的后向方向上数据包的平均大小
(54)fw_byt_blk_avg - - > 在正向上的平均字节数块速率
(55)fw_pkt_blk_avg - - > 在正向方向上数据包的平均数量
(56)fw_blk_rate_avg - - > 在正向方向上平均bulk速率
(57)bw_byt_blk_avg - - > 在反向上的平均字节数块速率
(58)bw_pkt_blk_avg - - > 在反向方向上数据包的平均数量
(59)bw_blk_rate_avg - - > 在反向方向上平均bulk速率
(60)subfl_fw_pk - - > 在正向子流中包的平均数量
(61)subfl_fw_byt - - > 子流在正向中的平均字节数
(62)subfl_bw_pkt - - > 反向子流中数据包的平均数量
(63)subfl_bw_byt - - > 子流在反向中的平均字节数
(64)fw_win_byt - - > 在正向的初始窗口中发送的字节数
(65)bw_win_byt - - > 在反向的初始窗口中发送的字节数
(66)Fw_act_pkt - - > 在正向方向上具有至少1字节TCP数据有效负载的包
(67)fw_seg_min - - > 在正方向观察到的最小segment尺寸
(68)atv_avg - - > 流在空闲之前处于活动状态的平均时间
(69)atv_std - - > 流在空闲之前处于活动状态的标准偏差时间
(70)atv_max - - > 流在空闲之前处于活动状态的最大时间
(71)atv_min - - > 流空闲前激活的最小时间
(72)idl_avg - - > 流在激活之前空闲的平均时间
(73)idl_std - - > 流量在激活前处于空闲状态的标准偏差时间
(74)idl_max - - > 流在激活之前空闲的最大时间
(75)idl_min - - > 流在激活之前空闲的最小时间
2.获取
官方网站为:https://www.unb.ca/cic/datasets/ids-2017.html
直接前往官网,最底部有下载按钮:
http://205.174.165.80/CICDataset/CIC-IDS-2017/Dataset/
如上图所示,在目录中,有三类文件,其中 GeneratedLabelledFlows 是完整提取文件,而 MachineLearningCSV 则是在前者基础上进行修剪后的版本,剔除了 IP 和时间戳等不适合机器学习的属性列,如果只是单纯进行机器学习训练,只需要下载后者即可。