做网站的销售团队凡科建站可以做几个网站
文件操作与IO
- Java中操作文件
- 针对文件系统的操作
- File类概述
- 字段
- 构造方法
- 方法及示例
- 文件内容的读写 —— 数据流
- Java提供的 “流” API
- 文件流读写文件内容
- `InputStream` 示例
- 读文件
- 示例1:将文件完全读完的两种方式
- 示例二:读取汉字
- 写文件
- 谈谈 `OutputStreamWriter` 和 `PrintWriter`
- `Reader`
- `Writer`
- `Scanner` 辅助输入
Java中操作文件
Java对于文件操作的API:
-
针对文件系统的操作
包括但不限于:创建文件、删除文件、重命名文件、列出目录内容… -
针对文件内容的操作
读文件 / 写文件
针对文件系统的操作
Java 使用 File 类来进行对文件系统的操作,这个类所在的包叫 java.io
解释一下IO:
I:input(输入)
O:output(输出)
对于计算机来说,CPU是最关键的部分,所以要坐在CPU的头上来看待问题:
- 数据从硬盘到CPU,这个叫输入
- 数据从CPU离开,这个叫输出
File类概述
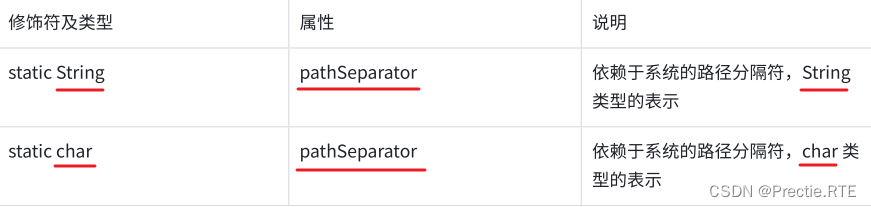
字段
也就是路径之间的分隔符,根据系统自动调整
构造方法
在练习中,使用第二个便够用了
![![[Pasted image 20240117122431.png]]](https://img-blog.csdnimg.cn/direct/d328c7efaef24995b76b83edad781c66.png)
注:如果写作相对路径,一定要明确其工作目录
- 如果直接在 idea 中运行程序,此时工作目录就是项目所在目录
- 如果把代码打包成一个单独的 jar 包来执行,此时工作目录就是 jar 包所在目录
方法及示例
![![[Pasted image 20240117124331.png]]](https://img-blog.csdnimg.cn/direct/fab90767c87842b795dd172695078ffd.png)
绝对路径:
![![[Pasted image 20240117140533.png]]](https://img-blog.csdnimg.cn/direct/63324551e7e141869ddf259c7876caae.png)
相对路径:
注意:这里使用的相对路径,只是在人的视角看是存在这一路径的。
但是这个路径信息很少,在编译器的角度上,这个路径是不存在的
![![[Pasted image 20240117141017.png]]](https://img-blog.csdnimg.cn/direct/114b655dc16f4423847d4e6842249f18.png)
![![[Pasted image 20240117124646.png]]](https://img-blog.csdnimg.cn/direct/dfc71b0d89814b7d8c4447a04bb1e150.png)
![![[Pasted image 20240117141750.png]]](https://img-blog.csdnimg.cn/direct/76ba53ea20b4461abaa2ee2a9890f567.png)
![![[Pasted image 20240117142149.png]]](https://img-blog.csdnimg.cn/direct/7d4774f79a704fa6aad6cda04148e81b.png)
再运行一次:
![![[Pasted image 20240117141941.png]]](https://img-blog.csdnimg.cn/direct/dcca4871d8e64a13a0ff614416a8164b.png)
delete 和 deleteOnExit
程序运行结束再删除,这样的文件,称为“临时文件”
![![[Pasted image 20240117142622.png]]](https://img-blog.csdnimg.cn/direct/f836fe1127ff4e8a96b0ba976d5cb8be.png)
list 和 listFiles
PS:直接打印出来的,不叫“地址” ,是叫 “哈希值”
![![[Pasted image 20240117204700.png]]](https://img-blog.csdnimg.cn/direct/0f95c8a964da4fa39a73af0a34ca44b8.png)
![![[Pasted image 20240117204825.png]]](https://img-blog.csdnimg.cn/direct/57f82ac8494d449db9ed3f6b27ce9553.png)
list ,获取到 “当前目录“ 下的所有文件名
![![[Pasted image 20240117204932.png]]](https://img-blog.csdnimg.cn/direct/cb3c18f221b54b0da700ccbec22335c4.png)
listFiles,获取到 “当前目录” 下的所有文件名,但是是以 File 对象表示
![![[Pasted image 20240117205135.png]]](https://img-blog.csdnimg.cn/direct/b83a9ae7b7a146fb9a4fbb2c75ed2d59.png)
这两个方法是用于创建目录的
![![[Pasted image 20240117124811.png]]](https://img-blog.csdnimg.cn/direct/6b6892f5999f42d980da21cad189ec75.png)
mkdir,只能创建一级目录
![![[Pasted image 20240117205404.png]]](https://img-blog.csdnimg.cn/direct/8142b3c3c41e4a9bb3a47e6814135084.png)
mkdirs:能创建多级目录
![![[Pasted image 20240117205506.png]]](https://img-blog.csdnimg.cn/direct/8da9f02fd0504c45aeabf70098b46e79.png)
![![[Pasted image 20240117124925.png]]](https://img-blog.csdnimg.cn/direct/17e2aedc59b749048f6d97b44eb133bb.png)
renameTo:重命名
![![[Pasted image 20240117205732.png]]](https://img-blog.csdnimg.cn/direct/fc1a8dda813e455e8a573f0b3a97fd76.png)
还有移动的功能(只能移动文件,不能移动目录)
![![[Pasted image 20240117210416.png]]](https://img-blog.csdnimg.cn/direct/f5c6357883cb46dc831a89027c961f6b.png)
文件内容的读写 —— 数据流
“流” 是操作系统中提出的概念,而编程语言基于这一概念抽象并封装出API来使用
什么叫抽象?
可以简单理解为:
信息越多,就越具体
信息越少,就越抽象
什么叫流?
比如:接 100L 的水,可以分10次接,一次接10L;也可以分20次接,一次接20L;也可以分1次接,一次性接完。接法有很多种,但最终的效果是一样的
文件流也是类似的:读写 100 字节的数据,可以分20次,每次读写5字节;也可以分1次读写,一次性读写完…
读写方式任意多种,但最终的结果都是把 100 字节的数据读写完毕
Java提供的 “流” API
Java标准库对于 “流” 进行了一系列的封装,提供了一组类来负责进行这些工作。
针对这么多类,大体可分为两大类别:
-
字节流
以字节为单位进行读写,一次最少读写 1 字节代表类:
InputStream输入
OutputStream输出 -
字符流
以字符为单位进行读写。
比如:如果是以 utf8 来表示汉字,一个汉字为 3 字节;那么每次读写都得以 3 个字节为单位来进行读写,不能以其他字节数来读写(不然给你读取半个汉字?不可能吧)代表类:
Reader输入
Write输出
文件流读写文件内容
因为流这一概念是从操作系统中借过来的,所以读写文件内容在各种编程语言中,都是“固定套路“:
-
打开文件
-
关闭文件
-
读文件
-
写文件
InputStream 示例
InputStream 点进源码可以看到是一个抽象类,不可实例化
再谈为什么要加 抽象类这一概念
abstract主要还是为了多一重 “校验”,因为这个抽象类我们是不希望它能够实例化的,就像 “单例模式” ,所以让编译器给我们再一次校验
所以我们实例化它的 “子类”,Java标准库中给我们提供了很多
![![[Pasted image 20240118133828.png]]](https://img-blog.csdnimg.cn/direct/4456e0febfc1448ca4a5f28d27e9d2c1.png)
我们选择 FileInputStream ,顾名思义,是从文件中 读 取
注:因为是 “读” 文件,所以得先有文件,这里创建一个 test.txt 文件来作为示例。
![![[Pasted image 20240118135644.png]]](https://img-blog.csdnimg.cn/direct/2035ddeae6a24dd9b08f2ba8c9b5263d.png)
.close() 可以理解是:释放了文件的相关资源,当然这种写法是不对的,中间逻辑但凡出了问题,这个资源就释放不了了。
第一种写法:自己手动释放资源
![![[Pasted image 20240118141616.png]]](https://img-blog.csdnimg.cn/direct/da06837dee334e6cae4fe3fd0ef5dc6a.png)
第二种写法:Java的 try 操作还提供了另外一个版本:try with resources(带有资源的 try 操作)
一旦执行完 try 代码块,try 会自动调用 inputStream 的 close() 方法
![![[Pasted image 20240118141952.png]]](https://img-blog.csdnimg.cn/direct/fa1ef3b233a14ae2a6c329309bd2f02c.png)
读文件
.read() 方法,有三种:
![![[Pasted image 20240118143943.png]]](https://img-blog.csdnimg.cn/direct/4d10adfe66d2451fba2e13d82130d3a3.png)
- 不带参数的
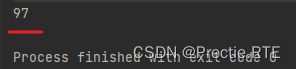
read()方法:读取 1 个字节的数据,虽然返回值是int类型,但实际上是byte,取值为 0 - 255,正好是1个字节的取值量。如果读取到文件末尾,继续read()就会返回-1,正因为多了一个 -1,才会用int作为返回值。- 这种读取一个字节的数据,返回值为这个字节对应码表的数值。如第一个字节数值为
a,那么返回值就是对应 ASCII 码表的 97

- 这种读取一个字节的数据,返回值为这个字节对应码表的数值。如第一个字节数值为
-
read(byte[] buffer),最多读取buffer.length字节的数据到 b 中,返回实际读取到的数量;-1 代表已经读取完毕- 返回值为 buffer 数组的长度。
- 假设
.txt文件中存的是111ab.c,read(buffer)操作就把该.txt文件的每个字节填充进buffer中,buffer每个空间存的就是 对应ASCII码表的值,如图: ![![[Pasted image 20240119131443.png]]](https://img-blog.csdnimg.cn/direct/2996c62665b94be79522c3c14c10cbb8.png)
-
read(byte[] b, int off, int len),从off处开始读取,最多读取len个字节的数据;-1 代表已经读取完毕这里的
off是offset偏移量的意思。
如图:off 处传1,len处传5。表示:从 buffer 数组的 1 下标位置开始读取,读取 5 个字节
![![[Pasted image 20240119131700.png]]](https://img-blog.csdnimg.cn/direct/da0923d5620844b8b8d90614c92061dc.png)
注:使用 read 方法的时候,往往是定义一个内容为空的数组(不是null),把空的数组交给 read,read内部对数组内容进行填充(读取到的内容放哪?放在我们所给的数组中)
![![[Pasted image 20240118144811.png]]](https://img-blog.csdnimg.cn/direct/87a61f47b3f94e27b12836f85a06f69f.png)
示例1:将文件完全读完的两种方式
在 “当前目录” 下创建一个 test.txt 文件,随便输入几个字符,然后读取
相较之下,后一种的 IO 次数更少,性能更好
讨论IO时,一定要分清楚,I是I,O是O,两者是分开的。
这里的read站在内存的角度上看,就是 input,输入部分。带参数和不带参数的read在这里是没有性能差别的。
但 output 时,站在 内存 的角度上看,第一个没有缓冲区,每次都要重新从硬盘读取,然后输出;第二个有缓冲区,已经一次性把数据从硬盘读取到内存中了,每次输出时就不用再从硬盘读取了,直接从内存取。
这就是为什么后一种IO次数更少,性能更好的原因
read()一次读一个。要知道:操作硬盘,本身就是一个低效的操作,而低效的操作,出现的次数越少越好。
![![[Pasted image 20240119132141.png]]](https://img-blog.csdnimg.cn/direct/f9a4f9b25d7344adae4020d438024cde.png)
read(byte[] buffer):一次性地,从头到尾地,将 buffer 数组填充 “满”,加上循环的话,最后一次填充满了之后,返回值不会是 -1,而是数组的长度;再次调用,就会返回 -1
![![[Pasted image 20240119143334.png]]](https://img-blog.csdnimg.cn/direct/c96140cfabd04f658c7bee3e180bbd76.png)
![![[Pasted image 20240119143340.png]]](https://img-blog.csdnimg.cn/direct/ee8d6d119464498cb9081a8027bc5900.png)
示例二:读取汉字
byte 占 1 个字节,而一个汉字占3个字节(因为Java中是utf8编码,GBK一个汉字占2个字节,不要弄混),所以两个汉字需要用 6 个byte空间来存储。
如果要输出汉字,可以使用 String 的构造方法,然后输出字符串。这里Java是进行了特殊的处理,这个后续再表
![![[Pasted image 20240119145616.png]]](https://img-blog.csdnimg.cn/direct/87d688a20edb47d992b3f84a89cecfe5.png)
![![[Pasted image 20240119145629.png]]](https://img-blog.csdnimg.cn/direct/2f0575ad3a074624988df70304ae1341.png)
写文件
注意!:写文件操作,在 new FileOutputStream 的时候,就会把文件中的内容清空
但也可以不清空,在文件内容的**下一行写入数据**
append 追加,设置为 true,就可以不清空内容了
![![[Pasted image 20240119150536.png]]](https://img-blog.csdnimg.cn/direct/0d06168fae5a4023a95b7ec048c551f5.png)
方法和 read 类似,使用也是相似的:
![![[Pasted image 20240119150353.png]]](https://img-blog.csdnimg.cn/direct/45a13101b8c1468498ee53aca5340b5e.png)
还有两个额外需要注意的方法:特别注意 flush()
![![[Pasted image 20240124125015.png]]](https://img-blog.csdnimg.cn/direct/3d5d3957afa4411fa66fb80abe0a1b40.png)
谈谈 OutputStreamWriter 和 PrintWriter
![![[Pasted image 20240124143010.png]]](https://img-blog.csdnimg.cn/direct/7b5d954bc865451fbe3105a85e6fa0d0.png)
其实第一步 new OutputStream 时就已经完成了输出工作,但 OutputStream 输出的时候在 “某些方面“ 不太方便
比如:输出之后换行,输出可以运算的内容。如图所示的
println/printf
要实现上面三个功能,就还需要通过其他类来 “加工” 一下,这些类就是 OutputStreamWriter 和 PrintWriter,也就是如上图书写的顺序
PrintWriter 是以 ”字符流“ 写入的
OutputStreamWriter 是 “字符流” 到 “字节流” 的桥梁(不是字节到字符)
所以具体流程为:PrintWriter 以 “字符流” 写入数据,随后通过 OutputStreamWriter 将写入的 ”字符流“ 数据转成 ”字节流“ 数据(此处内置了缓冲区),最后才将这些 ”字节流数据” 写入通过 OutputStream 从内存输出进文件内
Reader
Reader:大致用法都差不多,只不过这里是按字符char 来读取的
![![[Pasted image 20240119200611.png]]](https://img-blog.csdnimg.cn/direct/f81490b91f6b4ed18680dd08fb9d94a2.png)
注意这里:一个汉字是3个字节,但 char 只占 2 个字节,为什么能正常存储?而且还能打印出汉字?
文件内容是按 utf8 来编码的,
char在读取时,会将 utf8 转成 unicode,每个char里存储的是对应的 unicode 的值;String的构造方法,又可以基于 unicode 转换成 utf8。
总结:文件 utf8 -->char[]unicode --> String utf8这个转换过程是在Java中封装好了的
Writer
使用方式也是相似的,一般是用第二个:一次写入一串字符串
第一个是一次写入一个字符
第三个是一次写入一个字符数组
![![[Pasted image 20240119201523.png]]](https://img-blog.csdnimg.cn/direct/d8322003d3d74bb5b99cf2cbb32beda5.png)
Scanner 辅助输入
Scanner(System.in) 括号里面的,本质上就是一个 InputStream
示例:
![![[Pasted image 20240119202544.png]]](https://img-blog.csdnimg.cn/direct/4c8e39784e024f5fb228b73105ef935f.png)