网站切换宾馆管理系统
sql server软件是一款关系型数据库管理系统。具有使用方便可伸缩性好与相关软件集成程度高等优点。并且有些应用软件使用过程中是需要sql server数据库的后台支持的,我们在数据编程操作时经常会使用这款编程软件,在编程时系统有时会提示sql server服务无法启动,那么大家该如何正常启动呢?
1.当SQL SERVER服务没有开启时,SQL SERVER管理器连接不上数据库服务,会出现如下提示。
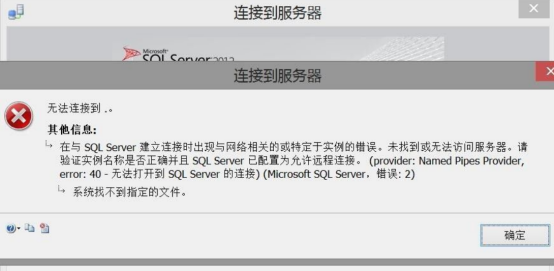
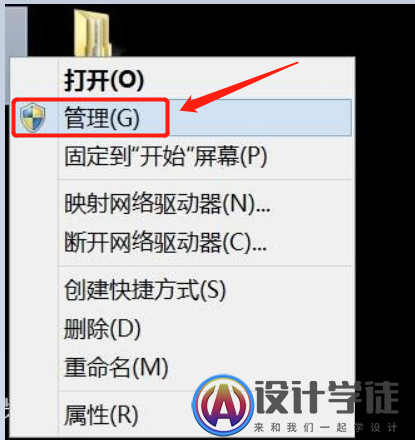
2.解决方法:在“计算机”上右键-"管理"。
文章源自设计学徒自学网-https://www.sx1c.com/32029.html
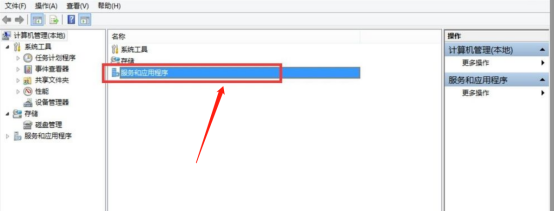
3.双击“服务和应用程序”。
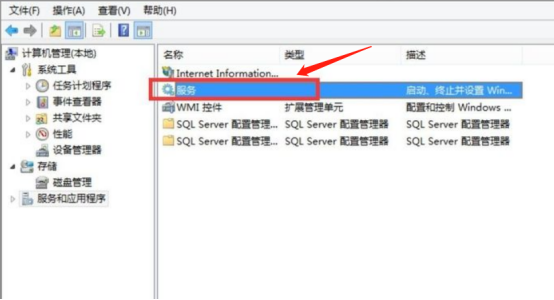
4.双击“服务”。
5.找到SQL SERVER(MSSQLSERVER),点击右键-“启动”。cad转pdf怎么变成黑白呢? | 一堂课
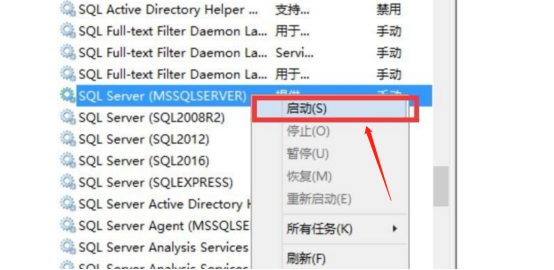
6.启动完毕后状态会变为:正在运行。
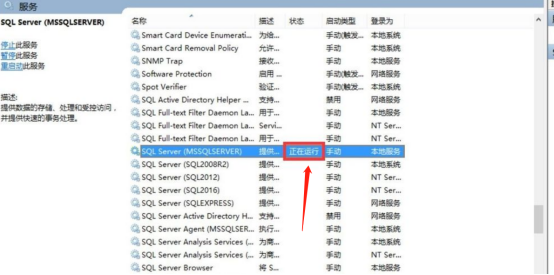
7.切换会SQL Server Management Studio(简称SSMS),点击连接,即可连接上SQL SERVER管理数据库。乡村小别墅设计建筑CAD施工图纸 | 四五设计网
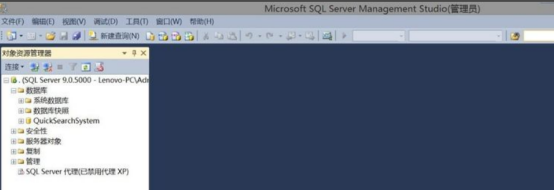
以上就是sql server服务无法启动,如何正确开启的教程,如果sql server服务未开启,sql server相关的应用将无法正常运行使用,大家学会了今天的教程,就可以按照上述操作讲解步骤进行解决。正常启动以后,我们就可以在该软件里进行数据编程了,进行正常工作了。sql server数据库管理系统,可以面向数据库执行查询、存储和检索数据,是当今企业管理必备的软件,今天的教程就为大家分享到这里。