软件公司网站系统集成建设建站哪家好用兴田德润

苏泽
大家好 这里是苏泽 一个钟爱区块链技术的后端开发者
本篇专栏 ←持续记录本人自学两年走过无数弯路的智能合约学习笔记和经验总结 如果喜欢拜托三连支持~
专栏的前面几篇详细了介绍了区块链的核心基础知识 有兴趣学习的小伙伴可以看看 http://t.csdnimg.cn/fCD5E关于区块链的基本组成、加密原理、共识机制都用最通俗易懂的方式讲解了 希望能够帮助大家学习
http://t.csdnimg.cn/fCD5E关于区块链的基本组成、加密原理、共识机制都用最通俗易懂的方式讲解了 希望能够帮助大家学习
下面是本文的正片
智能合约
简而言之 合约 也就是“约定” 既然谈到了 约定 很显然就想到了“信任” 我们不可能跟一个言而无信的人进行约定 人是如此 计算机也是如此 区块链更是如此
提到了信任 就不得不提前 最小信任机制 了
最小信任机制
这里有以太坊对最小信任机制的官方描述 可以在油管子里看看视频 当然了要是进不去或者嫌麻烦 这里用最简单的方式让你理解
在一个正常运行的社会中,人与人之间拥有足够的信任,可以支撑有效的社会和经济活动。然而,社会的信任水平不一定与事实划等号。一旦人们发现自己对社会运行机制的认知与事实存在偏差,信任就会出现裂痕,并且不可避免地导致更大的分歧,人们最终也会要求彻底改变整个运行机制。
当前社会正处于这样一场危机中,用户和机构之间的实际关系与用户认知存在偏差,比如人们对合约中法律责任的认知存在偏差,以及机构对外声称的情况与实际情况存在偏差。
这是什么意思呢 最简单我们举个现实的例子 那就是银行 啊不对 是老王办的某家投资公司 老王是个奸商,他对外宣称“把钱投给我 我让你躺着赚钱” 但事实上 他拿着客户给他的钱去巴厘岛度假了 只留下一堆包装工厂在原地风中萧瑟
上述的例子就很直白的表述出用户和机构之间的实际关系与用户认知存在偏差 那这样的事情怎么避免呢?
很简单。由于代码执行和验证不依赖对陌生人的信任或不可控的变量,因此代码可以严丝合缝地执行。区块链采用加密技术实现信任最小化, 简单来说 就是让代码站在 用户与用户之间、 或是用户与机构 、机构与机构之间。这样就能很好的实现最小信任机制

最小信任机制的关键是将信任分散到多个参与者之间,以减少对单一实体的依赖。 简单来说就是找一堆人盯着老王 不让他卷你的钱跑路 以此提高你和老王之间 交易的可靠性 而这里的“很多”则恰好体现了 分布式的应用
好了,既然这个最小信任机制那么高级 也那么有价值 他应该靠什么实现呢?
很好 那就是智能合约
智能合约
智能合约(Smart Contract)是一种基于区块链技术的自动化合约。它是一段程序代码,可以在区块链上执行、验证和执行合约的条款和条件。
智能合约的执行过程:
创建合约:首先,有一个人(创建者)使用一笔特殊的交易(称为合约创建交易)来部署合约。这笔交易包含了合约的字节码(即合约的编译后代码)和其他必要参数。在这笔交易中,创建者向合约地址发送以太币(ETH),作为合约的初始资金。
合约创建交易:合约创建交易被广播到整个以太坊网络,并被矿工包含在一个区块中。
区块链确认:矿工通过执行交易中的合约字节码创建新的区块。这是合约在以太坊网络中的创建过程。
触发合约:一旦合约被创建,任何人都可以通过向合约地址发送交易来调用合约。这笔交易包含了调用合约的数据,即要执行的合约函数及其参数。
合约执行:当这笔交易被矿工打包并写入区块链后,以太坊网络中的每个节点都会执行合约的字节码,模拟合约的执行过程。这确保所有节点达成相同结果。
作为合约 其实本质上就是代码 既然是代码 他就有许多种编程语言可以选择
- Solidity:目前 DeFi TVL (DeFi 锁定的通证价值)占比最大的语言。是一种高级语言,类似于 JavaScript。
- Vyper:目前 DeFi TVL 排名第二的语言。也是一种高级语言,类似于 Python。
- Huff:一种类似于汇编的底层语言。
- Yul:一种类似于汇编的底层语言,内置于 Solidity
你可以选择自己喜欢的 但如果你是面向市场 建议还是选solidity(同时也是本篇专栏的重点)根据 DefiLlama 的数据,截至目前,在 DeFi 领域,Solidity 智能合约获得了 87% 的 TVL
因为Solidity 是一种面向对象的编程语言,用于在以太坊和其他区块链上来编写智能合约。 Solidity 深受Java、 C++、Python 和 JavaScript 的影响,并且专为 EVM (待会会详细说这个)而设计。

按照上面的思路 我们开心的学完solidity 就能愉快的编写合约啦 但是 我们需要什么来执行?
EVM
EVM是一个计算引擎,有助于智能合约的部署和操作。没有EVM,就不可能在以太坊协议上执行软件程序。因此,EVM是以太坊核心架构的关键部分。
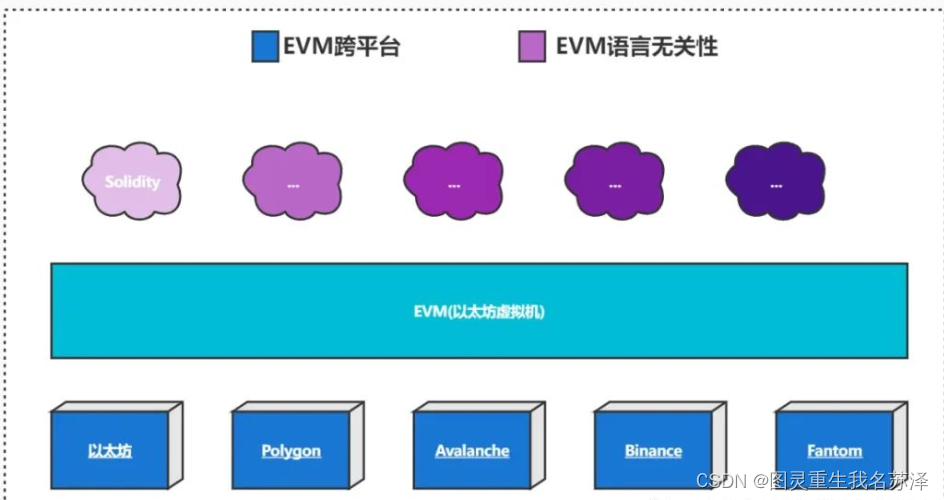
简而言之就是执行合约代码的地方
EVM是图灵完备的,因为它可以用于执行各种复杂度的计算。这就是以太坊与比特币的区别,因为比特币是图灵不完整的,限制了其功能。
比特币的主要功能是“分布式账本”,它规定了价值转移的规则。除了处理价值转移,以太坊(通过EVM)还支持智能合约的部署。因此,以太坊被描述为“分布式状态机”。
“State”(状态)是指在任何时间点有关系统的信息。在以太坊中,状态指的是特定时刻存在的地址、账户余额和智能合约代码。每个事务都会导致以太坊的状态发生变化(状态转换),这种变化会反映在整个网络中。
到了这里我们发现我们可以跟在我们自己部署的区块链上面执行代码了 但这场游戏显得不那么有趣 因为这是一场单机游戏 我们发现如果只到了这里 我们仅仅只是换了个编程语言 并没有做什么实际的事情
所以就有了预言机
Chainlink预言机
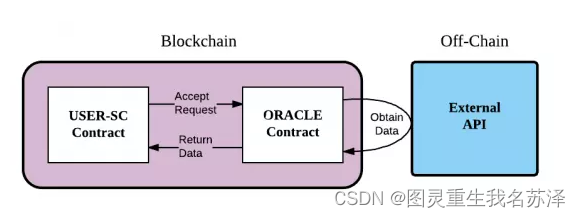
区块链为什么需要预言机?
区块链上的智能合约和去中心化应用(Dapp)对外界数据拥有交互需求。也就是说 区块链需要跟现实世界进行交互 就必须经过 预言机的处理
预言机就是一种单向的数字代理,可以查找和验证真实世界的数据,并以加密的方式将信息提交给智能合约。预言机就好比区块链与现实世界的桥梁。

预言机的原理
-
数据获取过程:预言机的数据获取过程通常包括以下步骤:
- 智能合约发起数据请求:智能合约向预言机发送数据请求,指定需要获取的数据类型和参数。
- 预言机获取数据:预言机根据智能合约的请求,从外部数据源中获取相应的数据。
- 数据验证和处理:预言机对获取的数据进行验证和处理,确保数据的准确性和完整性。
- 数据提交到区块链:预言机将处理后的数据通过提交事务/交易的方式,将数据提交到区块链上,供智能合约使用。