建一个域名网站要多少钱网站组成部分
目录
一、GPIO 简介
1.1 GPIO 基本结构
1.2 GPIO 位结构
1.3 GPIO 工作模式
二、GPIO 输出
三、GPIO 输入
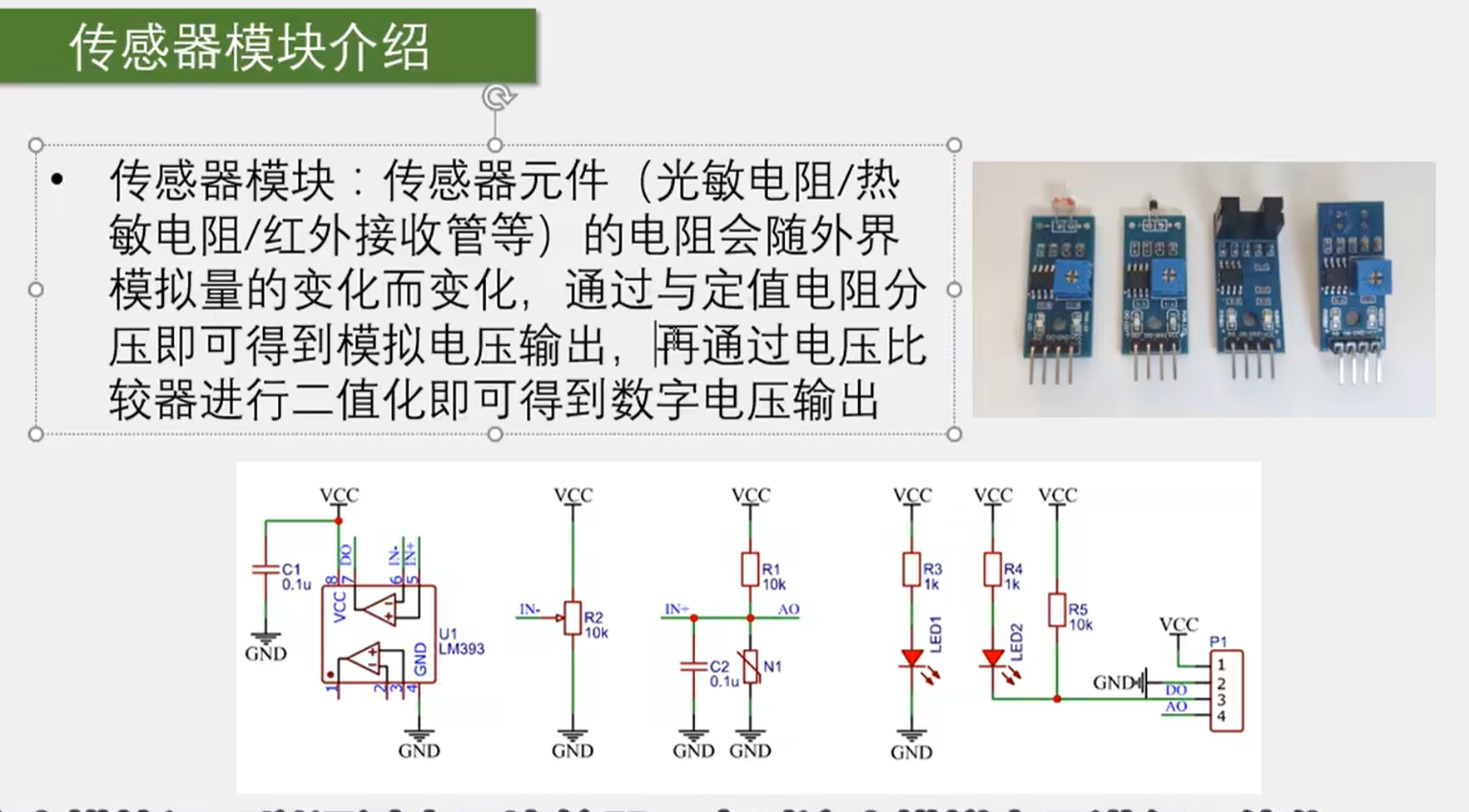
1.1 传感器模块
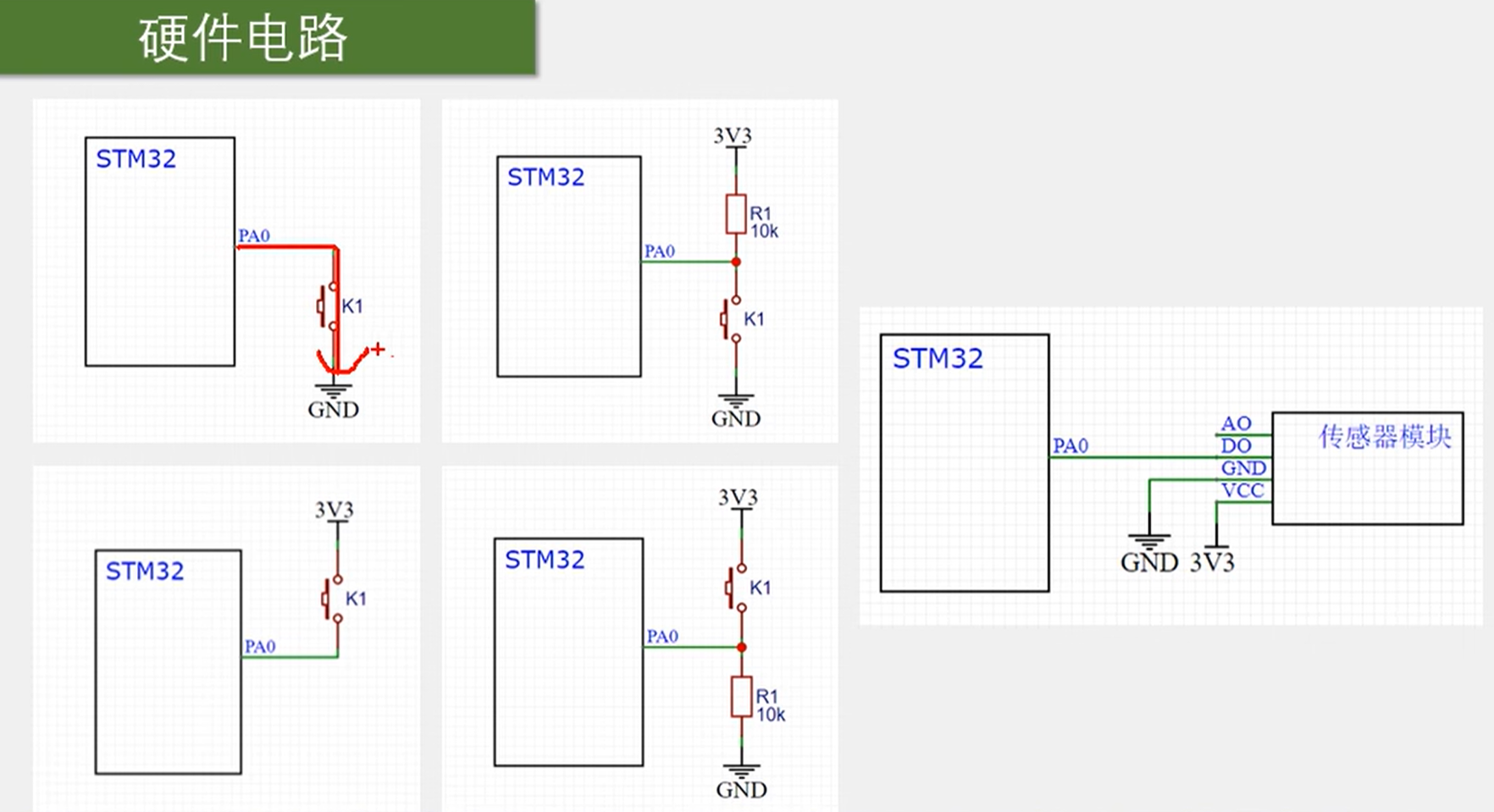
1.2 开关
一、GPIO 简介
GPIO(General Purpose Input Output)即通用输入输出口。

1.1 GPIO 基本结构
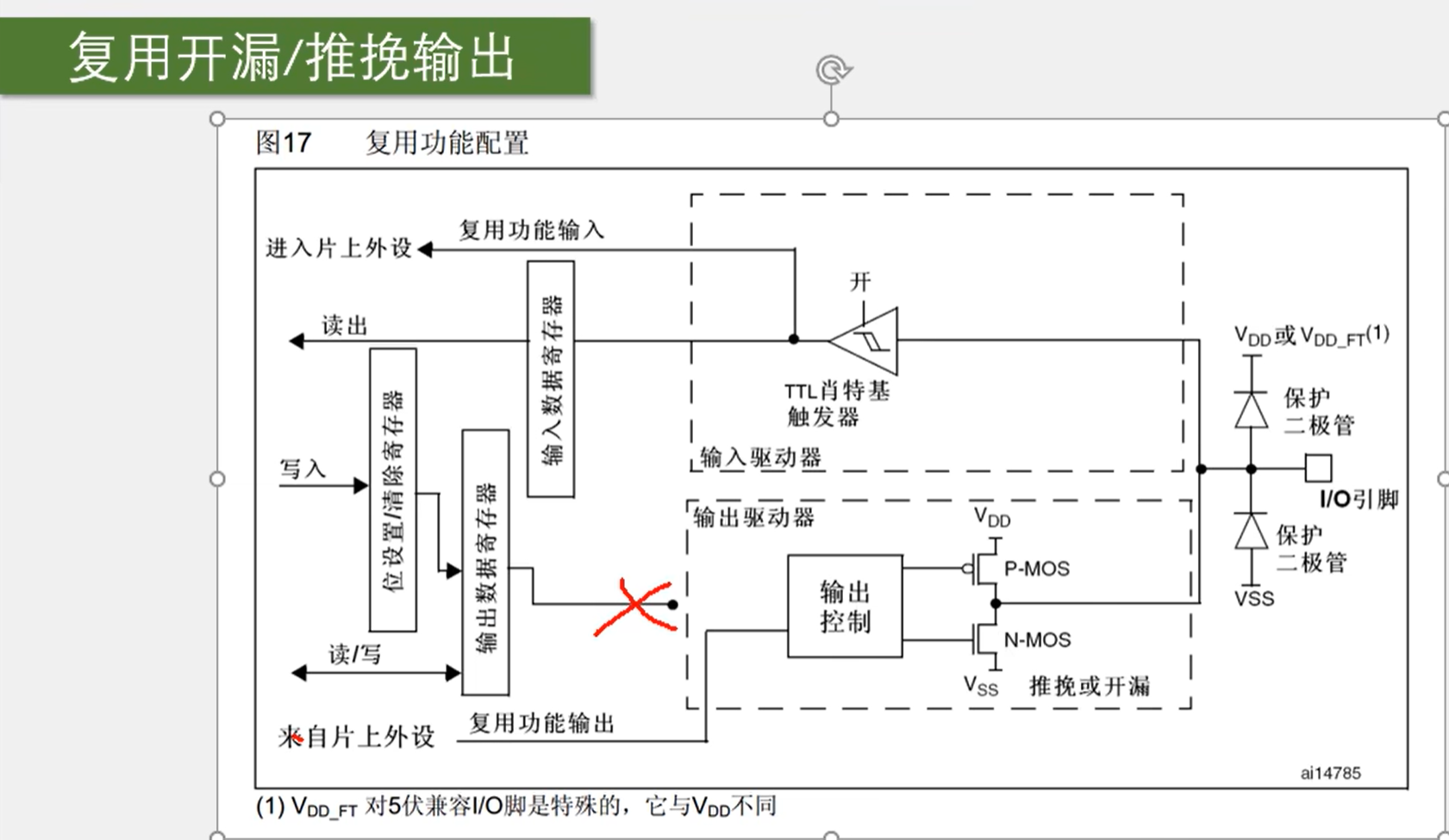
如下图,命名为 GPIOA, GPIOB...,每个 GPIO 外设总共有 16 个引脚,编号是从 0 到 15,内部包含了寄存器和驱动器,寄存器就是一段特殊的寄存器,内核可以通过 APB2 总线对寄存器进行读写。在输出模式中,对输出寄存器写 1,对应的引脚就会输出高电平,反之则为低电平;在输入模式中,如果输入寄存器读取为 1,则表示引脚电平为高,反之则表示引脚电平低。
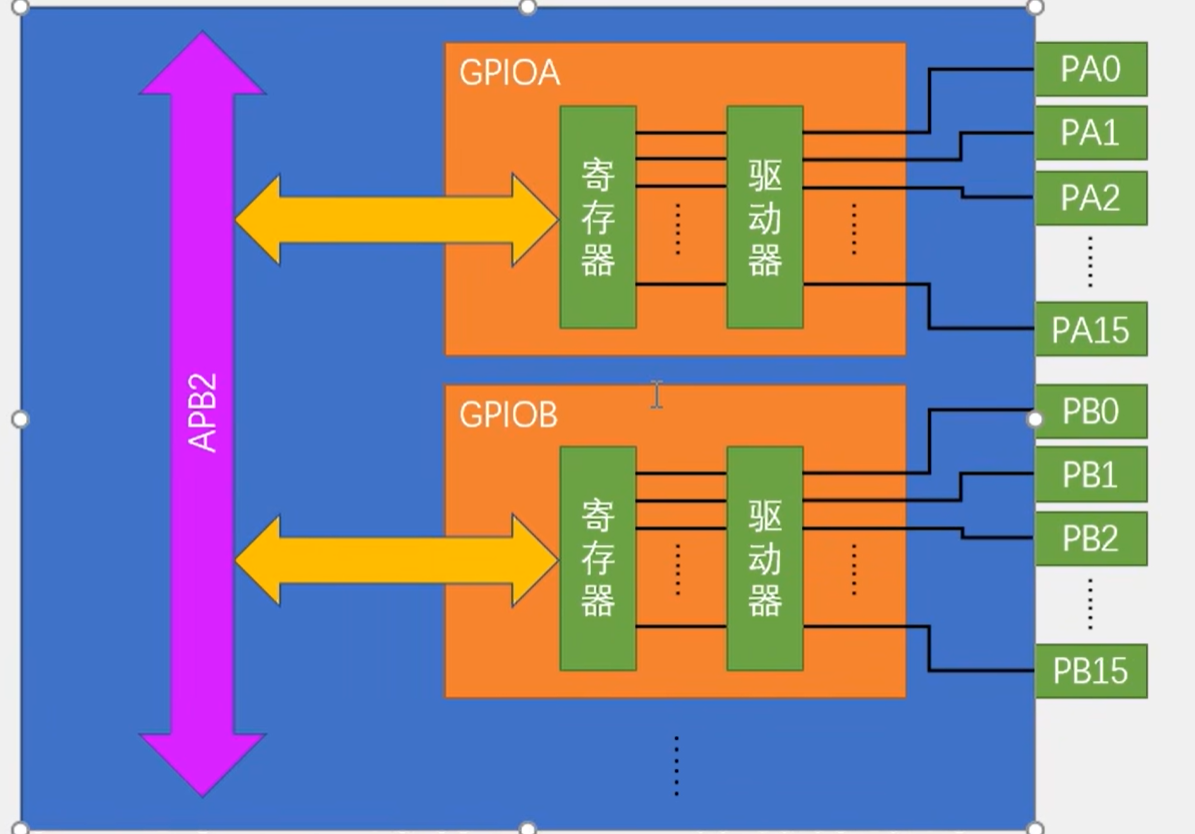
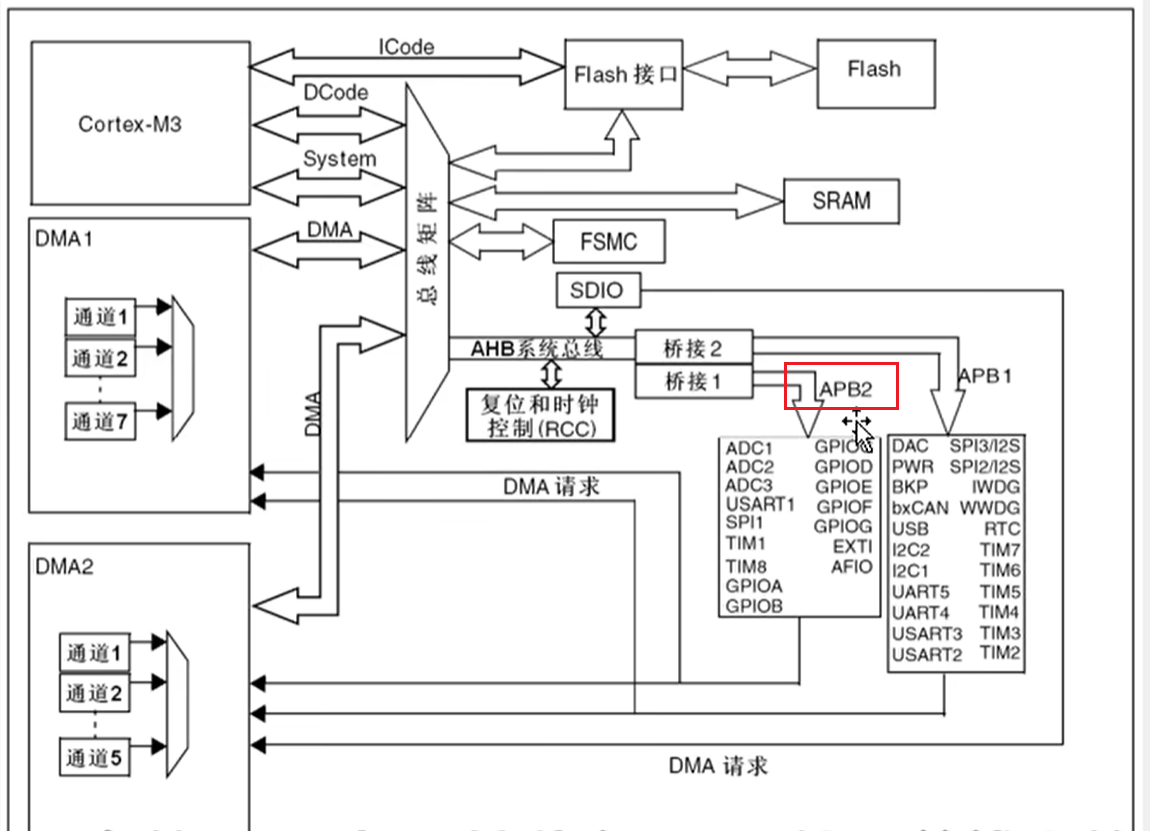
在 STM32 中,所有 GPIO 都是挂载在 APB2 外设总线上的:
1.2 GPIO 位结构
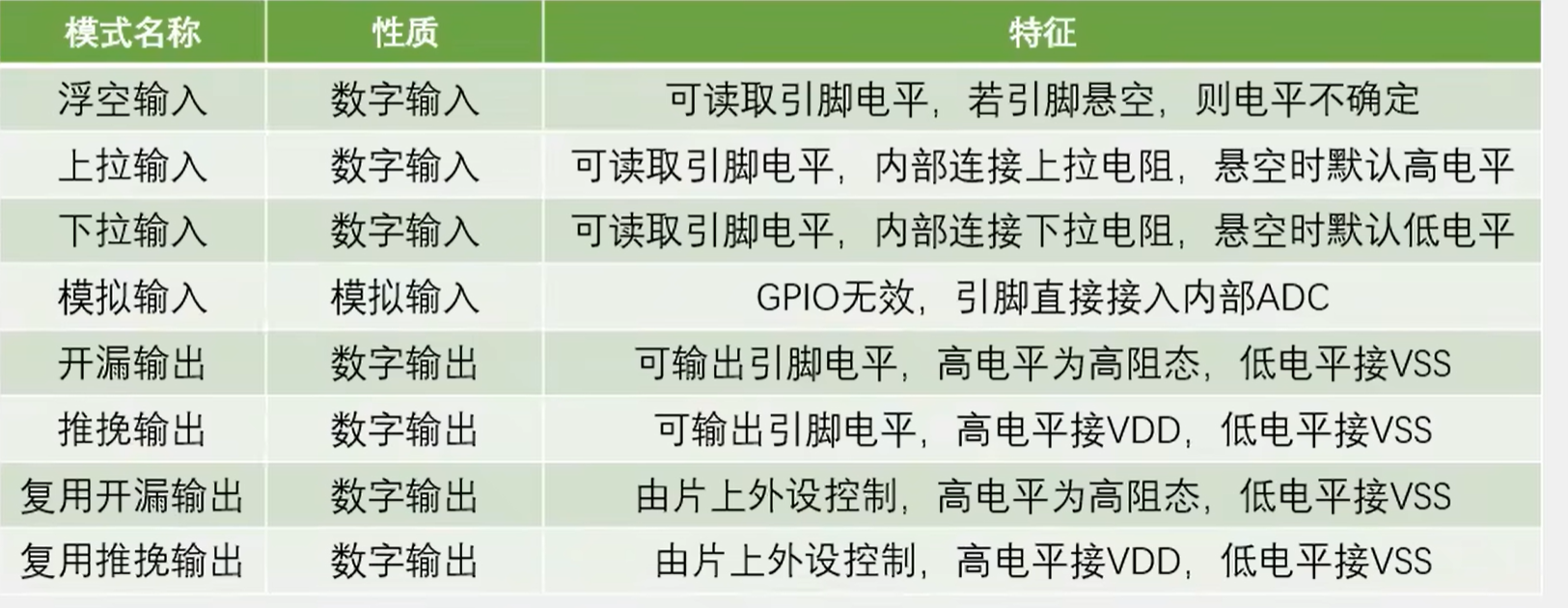
可以分为上下两部分,上部分为输入,下部分为输出。
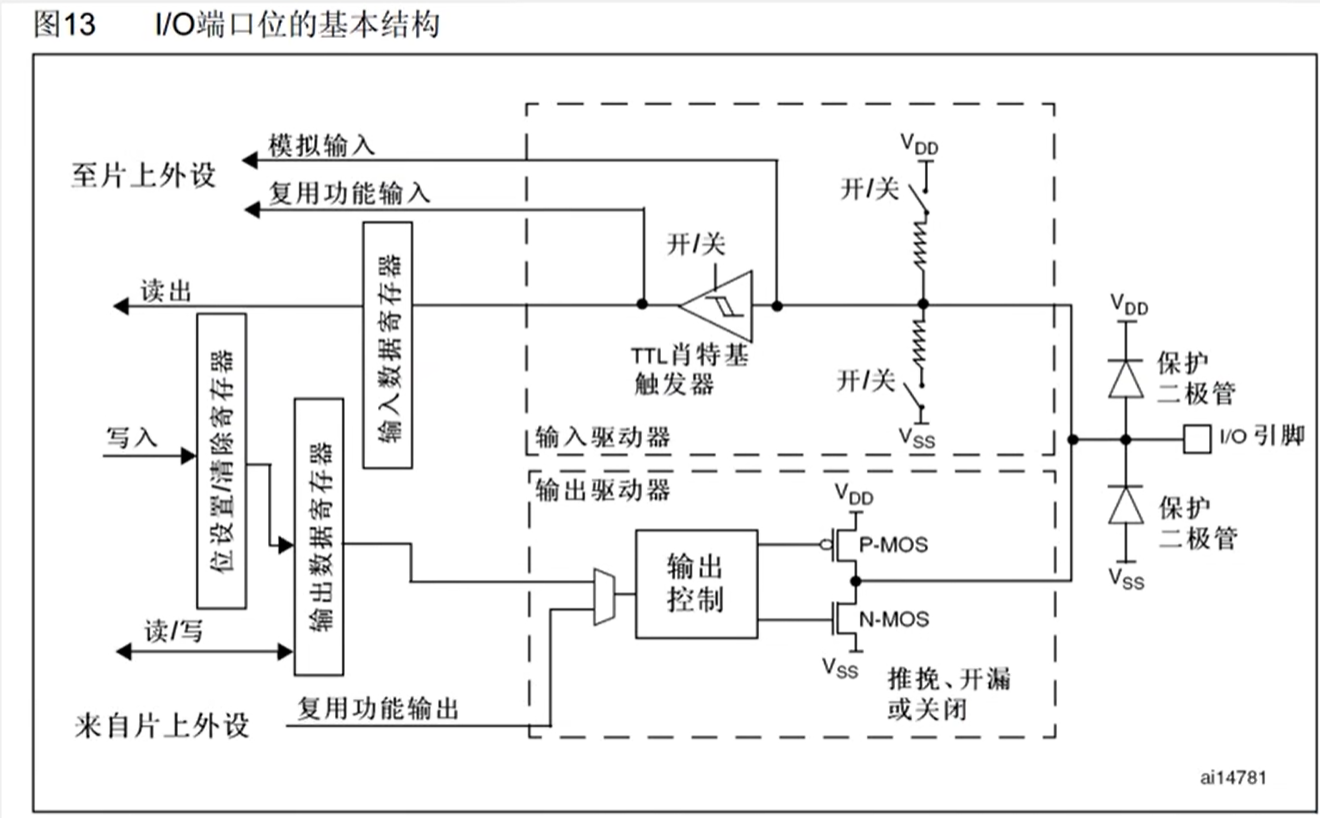
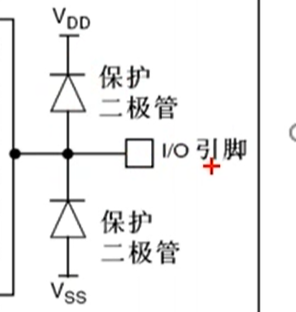
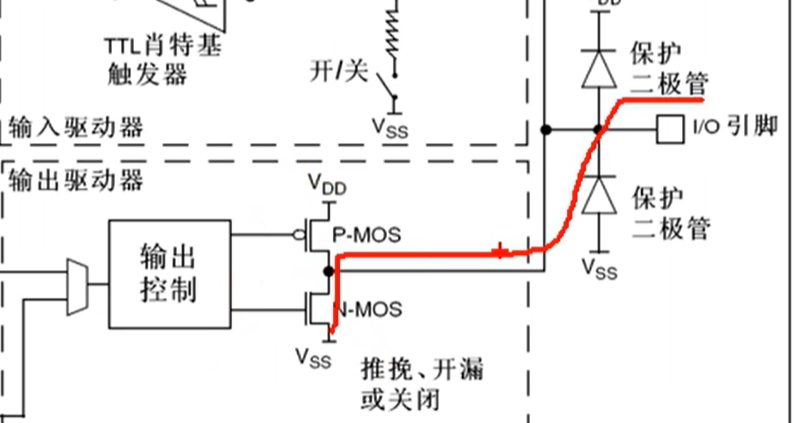
右边有两个保护二极管,VDD 为 3.3V,VSS 为 0V,如果 I/O 引脚输入大于 3.3V,则二极管导通,防止损坏内部电路;当 I/O 引脚输入小于 0V 时,下方二极管导通,也可以保护电路。在 0~3.3V 之间则为正常。
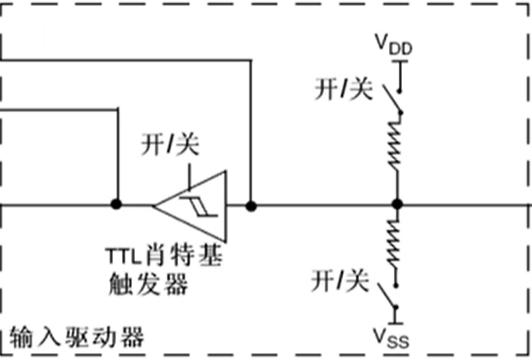
下图中有一个上拉电阻至 VDD,一个下拉电阻至 VSS,而开关可以通过程序进行配置。如果上面导通,下面断开,就是上拉输入模式;如果下面导通,上面断开,则是下拉输入模式;如果两个都端口就是浮空输入模式。
上拉下拉的作用:可以给输入提供一个默认的输入电平,因为引脚如果什么都不接就会处于浮空状态,容易受到外界干扰,为了避免引脚悬空导致输入输出不确定,就需要加入上拉或下拉电阻(电路中上拉、下拉电阻的作用及原理 - 知乎)。
上图中的 TTL 施密特触发器可以对输入电压进行整形,即:如果输入大于某一阈值,输出会瞬间升为高电平;如果输入电压小于某一阈值,则输出会瞬间降为低电平。可以有效地避免因为输入信号波动而产生的输出抖动现象。经过施密特触发器整形后的波形就可以直接写入输入数据寄存器了,程序可以通过读取输入数据寄存器的值而判断引脚的电平高低。
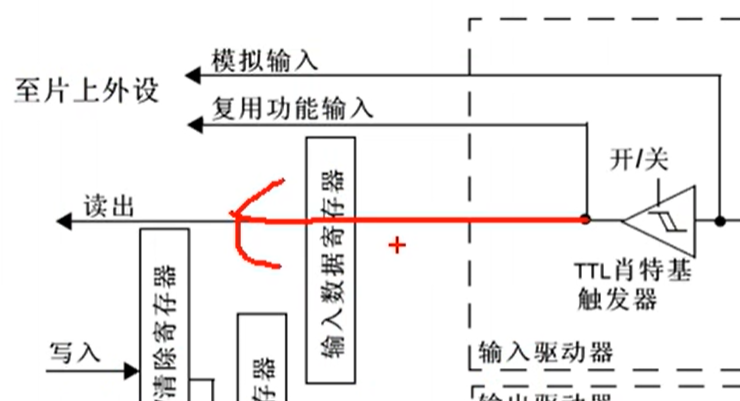
上图中还引出了两路信号,模拟输入是连接到 ADC 上的,因为 ADC 要接收模拟量,接在施密特触发器前面;复用功能输入连接到其他需要读取端口的外设上的,接在施密特触发器后,因为需要数字量。
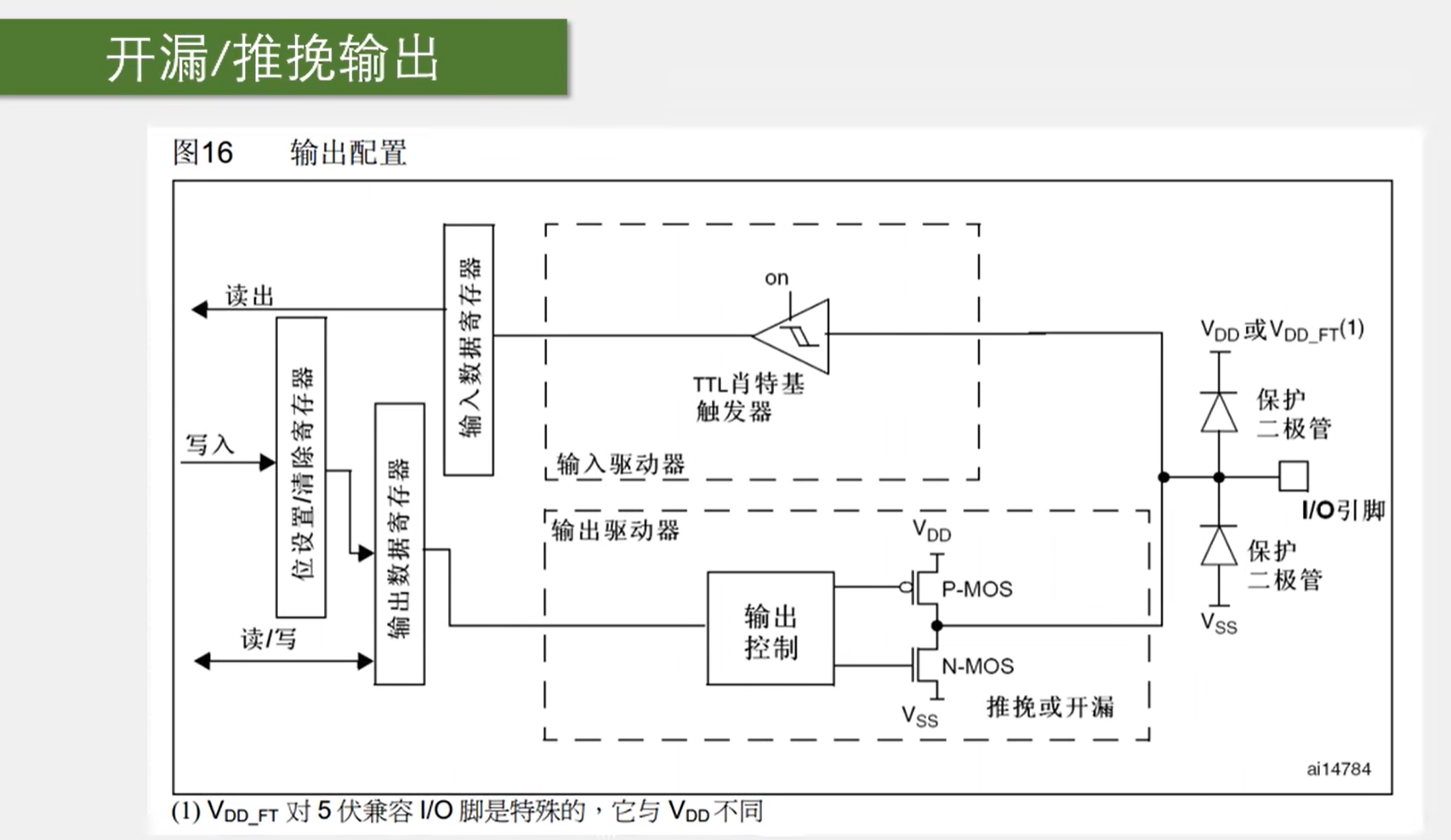
输出部分可以由输出数据寄存器或复用功能输出(来自片上外设)来控制。位设置\清除寄存器可以单独控制输出数据寄存器的某一位而不影响其他位,
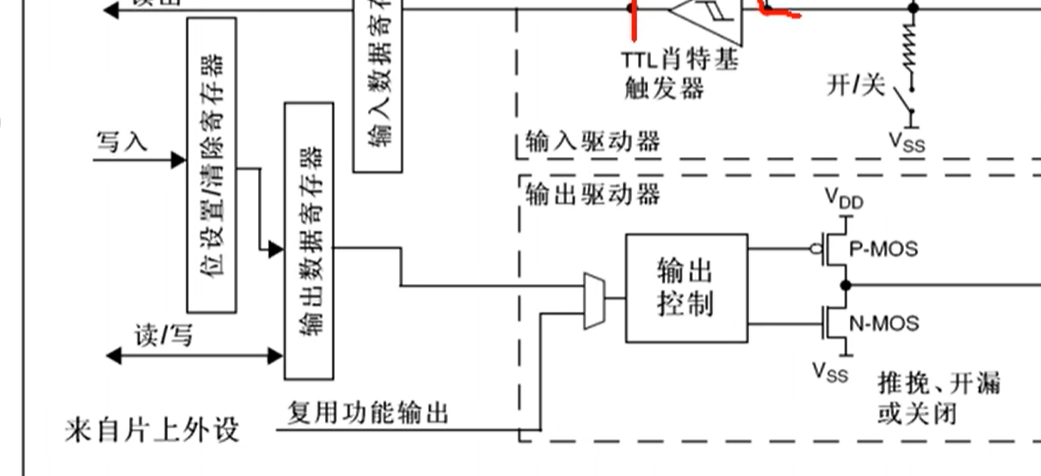
输出控制之后接到了两个 MOS 管,MOS 管是一种电子开关,我们的信号可以控制开关的导通和关闭,开关负责将 I/O 口接入到 VDD 或 VSS。开关可以选择推挽、开漏或关闭。
在推挽模式下,P-MOS 和 N-MOS 均有效,在输出寄存器为 1 时,上管导通,下管断开,输出直接接到 VDD,也就是输出高电平;输出寄存器为 0 时,上管断开,下管导通,输出直接接到 VSS,也就是输出低电平。在这种模式下,高低电平均有较强的驱动能力,所以推挽模式也叫强推输出模式。在推挽模式下,STM32 对 IO 口具有绝对的控制权。
在开漏输出模式下,P-MOS 无效,数据寄存器为 1 时,下管断开,输出相当于断开,也就是高阻模式;数据寄存器为 0 时,下管导通,输出直接接到 VSS,也就是输出低电平。也就是说高电平没有驱动能力,只有低电平才有驱动能力,开漏模式可以作为通信协议的驱动方式,比如 I2C 协议的引脚;在多机通信的情况下,这个模式可以避免各个设备的相互干扰。
在关闭模式下,两个 MOS 管均无效,也就是输出关闭,端口的电平由外部信号来控制。
1.3 GPIO 工作模式
通过配置 GPIO 端口的配置寄存器,端口可以配置成以下 8 种模式。
根据工作模式配置的不同,上面介绍的 GPIO 位结构的电路就会根据我们的配置进行改变。
浮空输入、上拉输入、下拉输入配置,输出开关断开,端口只能输入不能输出:
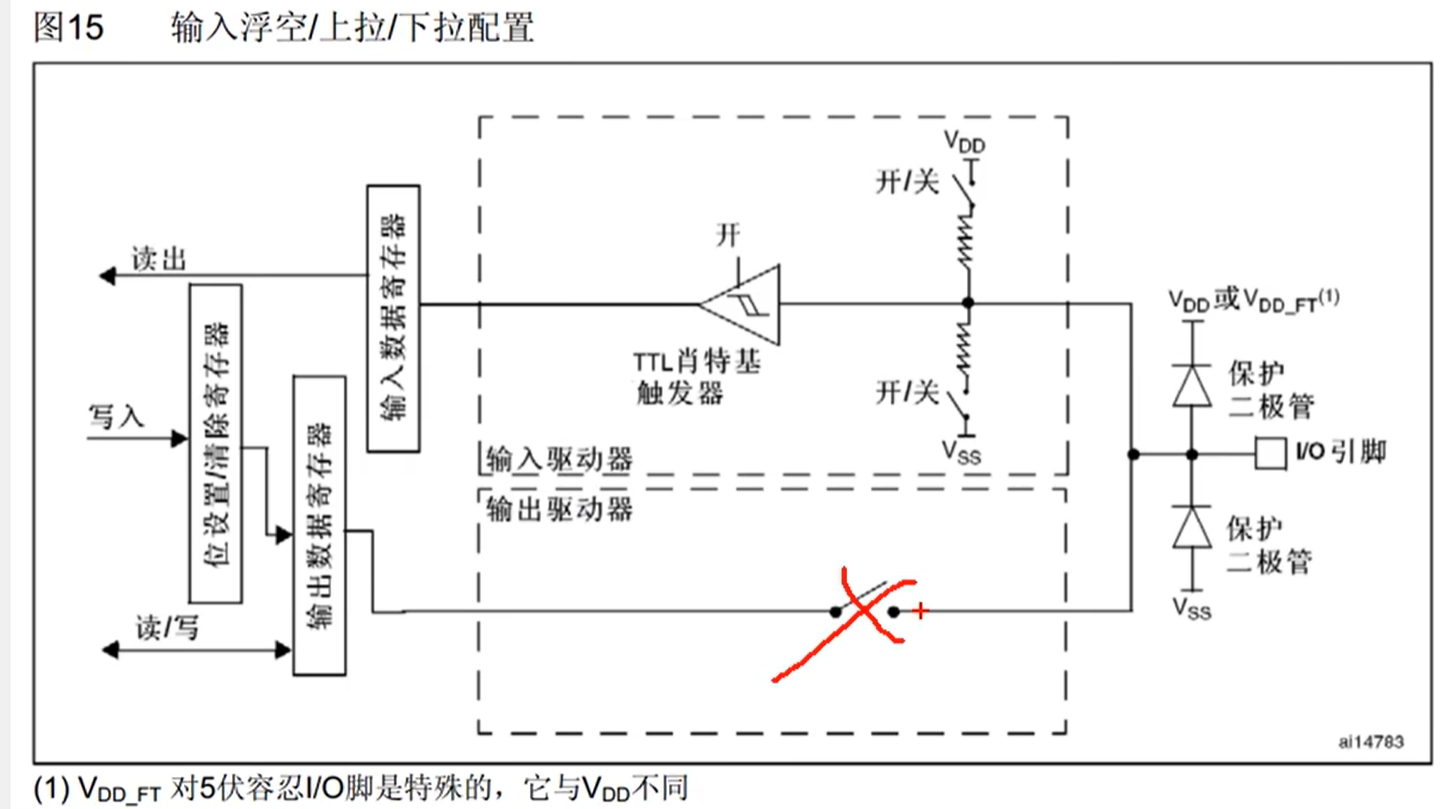
模拟输入:
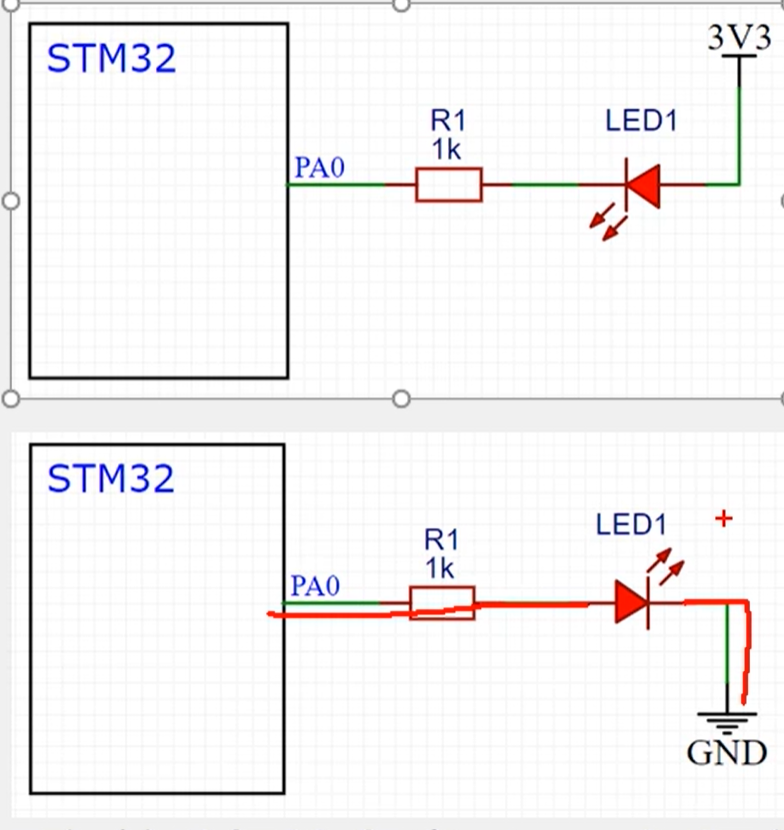
LED 硬件电路有如下两种,在输出引脚驱动能力较强的时候,可以采用第二个图,如果驱动能力较弱则采用第一个图。
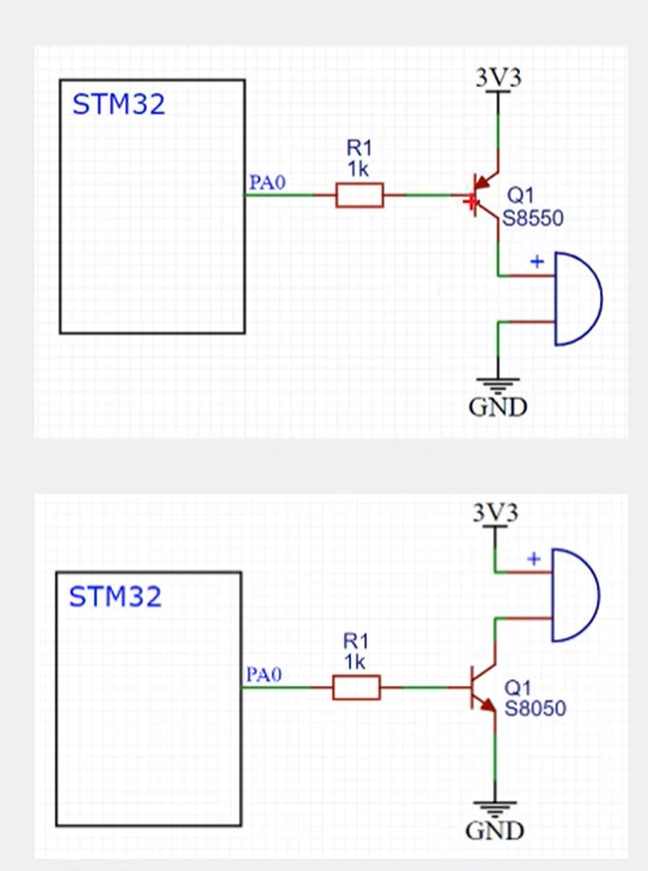
蜂鸣器的硬件电路有如下两种,直接使用 IO 口驱动会导致 STM32 负担过重。
上面的图为 PNP 型三极管,左边为基级,带箭头的为发射级,剩下的为集电极。基级为低电平时,三极管导通,此时蜂鸣器工作;基级为高电平时,三极管截止,蜂鸣器无电流。
下面的图为 NPN 型三极管,基级高电平导通,低电平截止,和上面相反。
二、GPIO 输出
第一个是外设时钟控制函数, 因为我们要设置 pA0 引脚,所以第一个参数选择 RCC_APB2Periph_GPIOA。
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE);第二个是 GPIO_Init 函数,需要初始化 GPIO_InitTypeDef 结构体:
GPIO_InitTypeDef GPIO_InitStruct;
GPIO_InitStruct.GPIO_Mode = GPIO_Mode_Out_PP;
GPIO_InitStruct.GPIO_Pin = GPIO_Pin_0 | GPIO_Pin_1;
GPIO_InitStruct.GPIO_Speed = GPIO_Speed_50MHz;
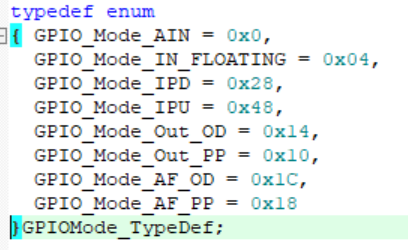
GPIO_Init(GPIOA, &GPIO_InitStruct);其中 GPIO_InitStruct.GPIO_Mode 用于配置 GPIO 的工作模式,有如下八种工作模式:
- AIN (Analog In)为模拟输入;
- IN_FLOATING 为浮空输入;
- IPD(In Pull Down)为下拉输入;
- IPU(In Pull Up)为上拉输入;
- Out_OD(Out Open Drain)为开漏输出;
- Out_PP(Out Push Pull)为推挽输出;
- AF_OD(Alt Open Drain)为复用开漏;
- AF_OD(Alt Push Pull)为复用推挽;
GPIO_InitStruct.GPIO_Pin 用于配置引脚,如 GPIO_Pin_0 为第 0 个引脚,可以同时初始化多个引脚。
最后再使用 GPIO_Init(GPIOA, &GPIO_InitStruct) 函数对对应 GPIO 进行初始化。
第三个是使用 GPIO 的输入输出函数:
uint8_t GPIO_ReadInputDataBit(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
uint16_t GPIO_ReadInputData(GPIO_TypeDef* GPIOx);
uint8_t GPIO_ReadOutputDataBit(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
uint16_t GPIO_ReadOutputData(GPIO_TypeDef* GPIOx);// 将指定端口设置为高电平
void GPIO_SetBits(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
GPIO_SetBits(GPIOA, GPIO_Pin_0); // 设置pA0为高电平// 将指定端口设置为低电平
void GPIO_ResetBits(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin);
GPIO_ResetBits(GPIOA, GPIO_Pin_0); // 设置pA0为低电平// 根据第三个参数的值来设置指定的端口
void GPIO_WriteBit(GPIO_TypeDef* GPIOx, uint16_t GPIO_Pin, BitAction BitVal);// 可以同时对 16 个端口进行写入操作
void GPIO_Write(GPIO_TypeDef* GPIOx, uint16_t PortVal);三、GPIO 输入
1.1 传感器模块
下图中的 C2 电容是一个滤波电容,起到平滑电压波形的作用,该电容并不是电路图中的主要部分,经过 C2 的平滑,AO 引脚输出一个模拟电压。而数字电压输出则是通过左边的 LM393 来完成,它是一个电压比较器芯片,C1 是一个电源供电的滤波电容,电压比较器是一个运算放大器,当 IN+ 和 IN- 为大于关系时,输出 DO 会上升到 VCC,小于时会下降到 GND,从而对模拟电压进行二值化,其中 IN+ 接 AO,IN- 接 到第二个可调电位器上,从而可以调节阈值。其中 N1 对应传感器(比如光敏传感器对应光敏电阻)。
1.2 开关
一般使用上面两个图,并且会使用上拉电阻来使得按键未按下时导致引脚悬空时为高电平,所以可以初始化引脚为上拉输入模式。
在 stm32 中 int 为 32 位,而在 51 中占 16 位(使用 stdint.h 可以避免这个问题,uint8_t)。
RO-data:Read Only data,即只读数据域,它指程序中用到的只读数据,这些数据被存储在ROM区,因而程序不能被修改的内容。例如C语言中const关键字定义的变量就是典型的RO-data。
RW-data:Read Write data,即可读写数据域,它指初始化为“非0值”的可读写数据,程序刚运行时,这些数据具有非0的初始值,程序运行的时候它们又会常驻在RAM区,应用程序可以修改其内容。例如C语言中定义的全局变量,且定义时赋予“非0值”给该变量。
ZI-data:Zero Initialie data,即0初始化数据,它指初始化为“0值”的可读写数据域,它与RW-data的区别是程序刚运行时这些数据初始值全都为0,程序运行时和RW-data的性质一样,它们也常驻在RAM区,应用程序可以更改其内容。例如C语言中使用定义的全局变量,且定义时赋予“0值”给该变量(如若定义该变量时没有赋予初始值,编译器会把它当ZI-data来对待,初始化为0);
下面是获取按键输入的程序 Key.c:
#include "Key.h"
#include "Delay.h"void Key_Init(void)
{// 配置APB2定时器使能;RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOB, ENABLE);// 配置引脚;GPIO_InitTypeDef GPIO_InitStruct;GPIO_InitStruct.GPIO_Mode = GPIO_Mode_IPU; // 上拉输入GPIO_InitStruct.GPIO_Pin = GPIO_Pin_6;GPIO_InitStruct.GPIO_Speed = GPIO_Speed_50MHz; // 输入模式下该配置没用GPIO_Init(GPIOB, &GPIO_InitStruct);
}uint8_t Key_GetValue(void)
{uint8_t value = 0;if(GPIO_ReadInputDataBit(GPIOB, GPIO_Pin_6) == 0){value = 1;}else{value = 0;}return value;
}