在线网站建设建议vs做的网站案例
一、安装Flask-Mail扩展
pip install Flask-Mail
二、配置Flask-Mail
格式:app.config['参数']='值'
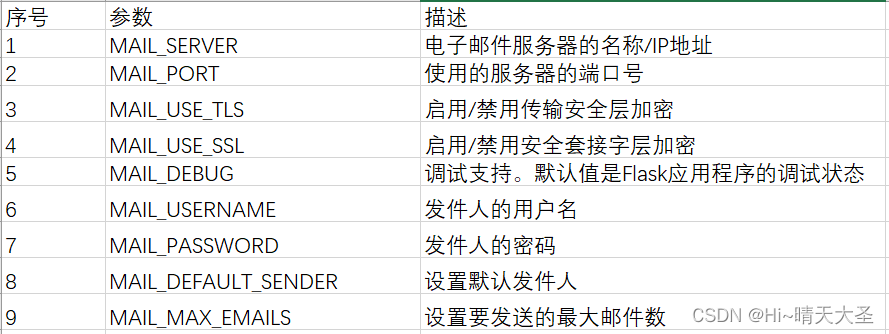
三、实现方法
3.1、Mail类
常用类方法

3.2、Message类,它封装了一封电子邮件。构造函数参数如下:
flask-mail.Message(subject, recipients, body, html, sender, cc, bcc, reply-to, date, charset, extra_headers, mail_options, rcpt_options)
其它方法:
attach(filename,content_type,data) - 为邮件添加附件。filename:附件名、content_type - MIME类型的文件、data - 原始文件数据
add_recipient() - 向邮件添加另一个收件人
四、举例说明
from flask import Flask
from flask_mail import Mail, Messageapp =Flask(__name__)app.config['MAIL_SERVER']='smtp.gmail.com' #配置邮箱
app.config['MAIL_PORT'] = 456
app.config['MAIL_USERNAME'] = 'tester01@gmail.com'
app.config['MAIL_PASSWORD'] = '*****'
app.config['MAIL_USE_TLS'] = False
app.config['MAIL_USE_SSL'] = True
mail = Mail(app) #创建Mail类实例@app.route("/")
def index():msg = Message('Hello', sender = 'tester01@gmail.com', recipients = ['tester02@gmail.com'])msg.body = "Hello World"mail.send(msg)return "Sented"if __name__ == '__main__':app.run(debug = True)