求一个做美食视频的网站工业设计包括哪些产品
第一个SpringBoot程序
自动装配原理
Springboot的自动装配实际上就是为了从Spring.factories文件中获取到对应的需要进行自动装配的类,并生成相应的Bean对象,然后将它们交给Spring容器来帮我们进行管理
启动器:以starter为标记
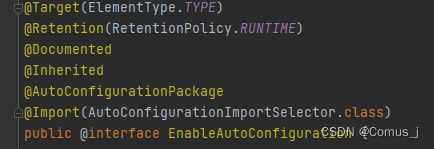
@EnableAutoConfiguration
这个注解是开启自动配置的功能,里面包含了两个注解
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
@AutoConfigurationPackage
这个注解的作用说白了就是将主配置类(@SpringBootApplication标注的类)所在包以及子包里面的所有组件扫描并加载到spring的容器中,这也就是为什么我们在利用springboot进行开发的时候,无论是Controller还是Service的路径都是与主配置类同级或者次级的原因
@Import(AutoConfigurationImportSelector.class)
上一个注解我们把所有组件都加载到了容器里面,这个注解就是将需要自动装配的类以全类名的方式返回,那是怎么找到哪些是需要自动装配的类呢?
1、AutoConfigurationImportSelector这个类里面有一个方法selectImports(),如下

springboot自动装配的流程
1、在springboot启动的时候会创建一个SpringApplication对象,在对象的构造方法里面会进行一些参数的初始化工作,最主要的是判断当前应用程序的类型以及设置初始化器以及监听器,并在这个过程中会加载整个应用程序的spring.factories文件,将文件中的内容放到缓存当中,方便后续获取;
2、SpringApplication对象创建完成之后会执行run()方法来完成整个应用程序的启动,启动的过程中有两个最主要的方法prepareContext()和refreshContext(),在这两个方法中完成了自动装配的核心功能,在run()方法里还执行了一些包括上下文对象的创建,打印banner图,异常报告期的准备等各个准备工作,方便后续进行调用;
3、在prepareContext()中主要完成的是对上下文对象的初始化操作,包括属性的设置,比如设置环境变量。在整个过程中有一个load()方法,它主要是完成一件事,那就是将启动类作为一个beanDefinition注册到registry,方便后续在进行BeanFactoryPostProcessor调用执行的时候,可以找到对应执行的主类,来完成对@SpringBootApplication、@EnableAutoConfiguration等注解的解析工作;
4、在refreshContext()方法中会进行整个容器的刷新过程,会调用spring中的refresh()方法,refresh()方法中有13个非常关键的方法,来完成整个应用程序的启动。而在自动装配过程中,会调用的关键的一个方法就是invokeBeanFactoryPostProcessors()方法,在这个方法中主要是对ConfigurationClassPostProcessor类的处理,这个类是BFPP(BeanFactoryPostProcessor)的子类,因为实现了BDRPP(BeanDefinitionRegistryPostProcessor)接口,在调用的时候会先调用BDRPP中的postProcessBeanDefinitionRegistry()方法,然后再调用BFPP中的postProcessBeanFactory()方法,在执行postProcessBeanDefinitionRegistry()方法的时候会解析处理各种的注解,包含@PropertySource、@ComponentScan、@Bean、@Import等注解,最主要的是对@Import注解的解析;
5、在解析@Import注解的时候,会有一个getImport()方法,从主类开始递归解析注解,把所有包含@Import的注解都解析到,然后在processImport()方法中对import的类进行分类,例如AutoConfigurationImportSelect归属于ImportSelect的子类,在后续的过程中会调用DeferredImportSelectorHandler类里面的process方法,来完成整个EnableAutoConfiguration的加载。