一起做玩具网站电子工程师在哪里报名
47、通用组件 - 倒计时组件
特惠部分存在一个倒计时的功能,所以我们需要先处理对应的倒计时模块,并把它处理成一个通用组件。
那么对于倒计时模块我们又应该如何进行处理呢?
所谓倒计时,其实更多的是一个时间的处理,那么对于时间的处理,此时我们就需要使用到一个第三方的包: dayis。通过这个包我们可以处理对应的倒计时格式问题。
那么时间格式处理完成之后,接下来我们就需要处理对应的数据:
我们期望对倒计时模块,可以传递两个值:
time毫秒值:表示倒计时的时长- format格式:表示倒计时的展示格式
那么到这里咱们整个的倒计时功能即使就分析的差不多了,总共分成了两部分:
1.时间格式
2.数据
<template><slot :data="{ timeStr, timeValue }"><div>{{ timeStr }}</div></slot>
</template><script setup>
import dayjs from 'dayjs'
import duration from 'dayjs/plugin/duration'
import 'dayjs/locale/zh-cn'
import { watch, ref, computed, onUnmounted } from 'vue'dayjs.extend(duration)
dayjs.locale('zh-cn')
let timer = null
const props = defineProps({time: {// 倒计时时间, ms单位type: Number,required: true},format: {// 格式化时间type: String,default: 'HH小时mm分钟ss秒SSS'}
})// 组件销毁时清理定时器
onUnmounted(() => {close()
})
const timeValue = ref(props.time)// 封装格式化日期函数
const fmtTime = (milliseconds) => {const d = dayjs.duration(milliseconds)return d.format(props.format)
}const handleSetInterval = () => {timer = setInterval(() => {if (typeof timeValue.value === 'number' && timeValue.value <= 0) {//完成close()} else {timeValue.value -= 9}}, 9)
}
const timeStr = computed(() => {return typeof timeValue.value === 'number' ? fmtTime(timeValue.value) : ''
})
/*** 关闭定时器*/
const close = () => {clearInterval(timer)
}
/*** 开启定时器*/
const start = () => {handleSetInterval()
}
/*** 从新设置定时器*/
const reset = (v) => {const setV = v > 0 ? v : props.timetimeValue.value = setV
}
watch(() => props.time,(v) => {timeValue.value = vclose()start()},{immediate: true}
)defineExpose({close,start,reset,timeStr,timeValue
})
</script>48、第三方平台登录解决方案流程大解析
通常情况下我们所说的第三方登录,多指的是:通过第三方APP进行登录
那么我们这个第三方的 APP 是如何和我们自己的应用进行关联的呢?
如果大家不是很清楚,那么本小节将为你解答。
想要搞明白这个问题,那么我们首先需要搞清楚整个第三方登录的流程是如何进行的。
我们以常见app第三方登录为例:
- 1.点击第三方登录按钮
- 2.弹出一个小窗口,展示对应二维码
- 3.手机打开对应的 APP进行扫码之后,会跳转到同意页面,同时浏览器端也会显示扫码成功
- 4.手机端操作同意登录之后,会出现两种情况:
- 1.当前用户已注册:直接登录
- 2.当前用户未注册:执行注册功能
详细流程如下:
- 1.点击第三方登录按钮:执行
window.open方法,打开一个第三方指定的URL窗口,该地址会指向第三方登录的URL,并且由第三方提供一个对应的二维码 - 2.弹出一个小窗口,展示对应二维码: 此处展示的二维码,即为上一步中第三方提供的二维码
- 3.手机打开对应的
APP进行扫码之后,会跳转到同意页面,同时浏览器端也会显示扫码成功:在第三方中会一直对该页面进行轮询,配合第三方APP 来判断是否扫码成功 - 4.手机端操作同意登录之后,会出现两种情况:在 APP 中同意之后,第三方会进行对应的跳转,跳转地址为你指定的地址,在该地址中可以获取到第三方的用户信息,该信息即为第三方登录时要获取到的关键数据
- 5**.至此,第三方操作完成。接下来需要进行本平台的登录判定。**
- 1.该注册指的是第三方用户是否在本平台中进行了注册。
- 2.因为在之前的所有操作中,我们拿到的是第三方的用户信息。
- 3.该信息可以帮助我们直接显示对用的用户名和头像,但是因为不包含关键信息(手机号、用户名、密码)所以我们无法使用该信息帮助用户直接登录
- 4.所以我们需要判断当前用户是否在咱们自己的平台中完成了注册
- 1.当前用户已注册:直接登录
- 2.当前用户未注册:执行注册功能
48.1、QQ开放平台流程大解析
那么接下来我们先来处理QQ第三方登录功能。
想要对接QQ登录,那么需要使用到QQ互联平台,在该平台中:
1.注册账户
2.认证开发者
3.注册应用
48.2、QQ登录对接流程: 获取QQ用户信息
官网文档
对接QQ登录分为以下几步:
- 1.展示
QQ登录二维码 - 2.获取用户信息
- 3.完成跨页面数据传输
- 4.认证是否已注册分
- 5.完成
QQ对接
展示QQ登录二维码
1、在index.html中引入QQ的SDK
<!-- QQ 登录 --><scripttype="text/javascript"charset="utf-8"src="https://connect.qq.com/qc_jssdk.js"data-appid="[你的appid]"data-redirecturi="[你在QQ互联中配置的成功之后的回调]"></script>
2、创建qq-login组件、来凤凰qq登录组件
<template><div class="qq-connect-box"><span id="qqLoginBtn"></span><svg-iconclass="w-4 h-4 fill-zinc-200 dark:fill-zinc-300 duration-500 cursor-pointer"name="qq"></svg-icon></div>
</template><script setup>
import { onMounted } from 'vue'
onMounted(() => {QC.Login({btnId: 'qqLoginBtn' //插入按钮的节点id},(data, ops) => {console.log(data, '登录成功')})
})
</script>
上面的图片可以得知、qqLoginBtn就是放置调起二维码按钮的地方、点击qqLoginBtn标签中的a链接、可以调起二维码;但是这样写有太丑;所以我们可以将a链接的透明度设置为0,并且置于最下方即可;css如下
<style lang="scss" scoped>
.qq-connect-box {position: relative;&:deep(#qqLoginBtn) {a {position: absolute;top: 0;right: 0;bottom: 0;left: 0;z-index: -1px;opacity: 0;}}
}
</style>
完整示例
<template><div class="qq-connect-box"><span id="qqLoginBtn"></span><svg-iconclass="w-4 h-4 fill-zinc-200 dark:fill-zinc-300 duration-500 cursor-pointer"name="qq"></svg-icon></div>
</template><script setup>
import { onMounted } from 'vue'
onMounted(() => {// 当我们登录成功之后、会缓存起来、下次登录不需要扫码、所以我们需要注销登录、避免用户下次登录时展示上次的记录QC.Login({btnId: 'qqLoginBtn' //插入按钮的节点id},(data, ops) => {// 扫码授权登录成功后的回到console.log(data, '登录成功')// 注销登录QC.Login.signOut()// 登录成功的回调// https://imooc-front.lgdsunday.club/login#access_token=4723B87EC749FA12A7247F40975D7BFB&expires_in=7776000// 解析地址栏地址获取tokenconst accessToken = getQQAccessToken()// 将data中的用户昵称、和用户头像、以及accessToken发送给后台// TODO})
})const getQQAccessToken = () => {const hash = window.location.hash || ''const reg = /access_token=(.+)&expires_in/return hash.match(reg)[1]
}
</script><style lang="scss" scoped>
.qq-connect-box {position: relative;&:deep(#qqLoginBtn) {a {position: absolute;top: 0;right: 0;bottom: 0;left: 0;z-index: -1px;opacity: 0;}}
}
</style>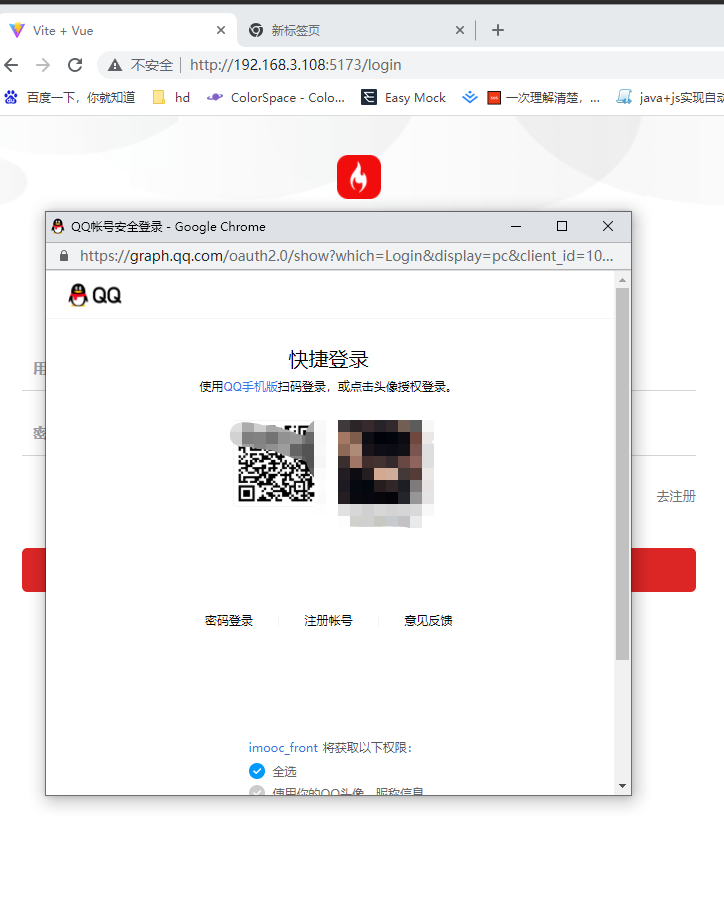
注意:扫码成功重定向的地址是在小窗口打开的、并不是在原来的窗口打开、登录成功的回调也是在小窗口中回调
48.3、 QQ登录对接流程:跨页面信息传输
由于拿到扫码用户的 AccessToken 和 用户的信息(昵称、头像…) 都是在小窗口上获取到的;
这小节最要作用:就是将小窗口获取到的这些信息传递给主窗口上
想要实现跨页面信息传输,通常由两种方式:
- 1、
BroadcastChannel:允许同源的不同浏览器窗口,Tab页,frame或者iframe下的不同文档之间相互通信。但是会存在兼容性问题,实测Safari15.3无法使用 - 2、
localStorage+window.onstorage: 通过localStorage进行同源的数据传输。用来处理BroadcastChannel不兼容的浏览器。
那么依据以上两个API,我们实现对应的通讯模块:
utils/broadcase.js
/**** 向同源且不同tab标签页发送数据*/// BroadcastChannel的信道key; 或者localStorage的设置项的key
const BROAD_CASE_CHANNEL_KEY = 'BROAD_CASE_CHANNEL_KEY'
// BroadcastChannel实例
let broadcastChannel = null
if (window.BroadcastChanne) {// 创建BroadcastChannel实例broadcastChannel = new window.BroadcastChanne(BROAD_CASE_CHANNEL_KEY)
}
/*** 发送数据* @param {*} data 发送的数据包*/
export const sendMsg = (data) => {if (broadcastChannel) {broadcastChannel.postMessage(data)} else {window.localStorage.setItem(BROAD_CASE_CHANNEL_KEY, JSON.stringify(data))}
}/*** 监听数据传输* @returns promise对象*/
export const listener = () => {return new Promise((resolve, reject) => {if (broadcastChannel) {broadcastChannel.onmessage = (event) => {resolve(event.data)}} else {window.onstorage = (event)