什么软件可以做网站html网站如何做反链
部署容器云平台[5 分]
使 用 OpenStack 私 有 云 平 台 创 建 两 台 云 主 机 , 云 主 机 类 型 使 用 4vCPU/12G/100G 类型,分别作为 Kubernetes 集群的 Master 节点和 node 节点, 然后完成 Kubernetes 集群的部署,并完成 Istio 服务网格、KubeVirt 虚拟化和 Harbor 镜像仓库的部署。
登录OpenStack私有云平台,使用CentOS7.9镜像创建两台云主机,完成Kubernetes 1.25.1集群的搭建。
curl -O http://10.18.4.46/chinaskills_cloud_paas_v2.1.iso
mount chinaskills_cloud_paas_v2.1.iso /mnt
cp -rvf /mnt/* /opt
cp /opt/kubeeasy-v2.0 /usr/bin/kubeeasy
kubeeasy --help#[install dependencies package cluster]kubeeasy install dependencies \--host 10.18.4.10,10.18.4.20 \--user root \--password 000000 \--offline-file /opt/dependencies/packages.tar.gz#[install k8s cluster offline]kubeeasy install kubernetes \--master 10.18.4.10 \--worker 10.18.4.20 \--user root \--password 000000 \--version 1.25.2 \--offline-file /opt/kubeeasy.tar.gz
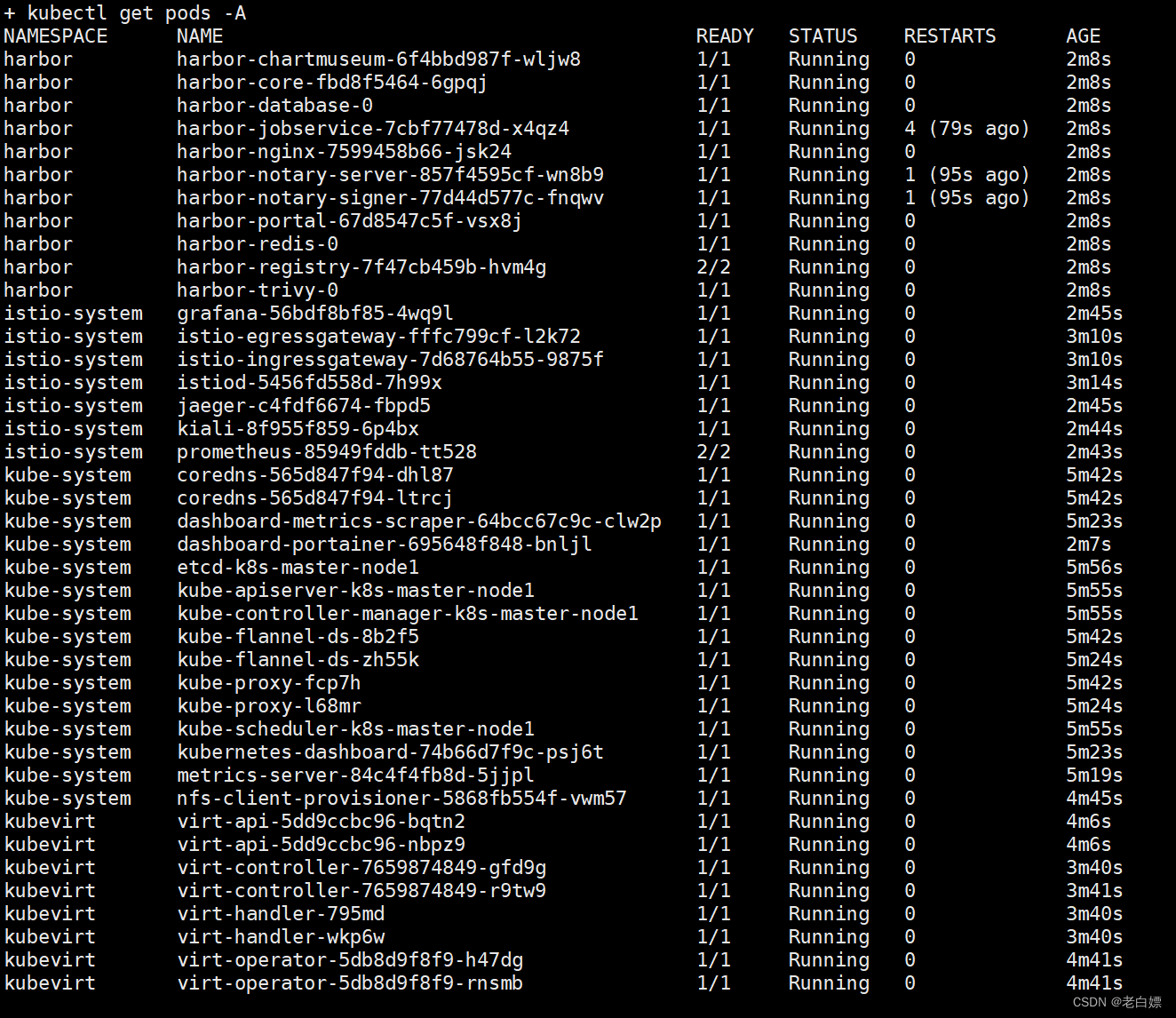
检查Pod的运行状态:
[root@k8s-master-node1 ~]# kubectl get pods -A
 检查节点状态
检查节点状态
[root@k8s-master-node1 ~]# kubectl get nodes

Harbor服务:
[Harbor](http://10.18.4.10/harbor/projects)
登录用户/密码: admin/Harbor12345
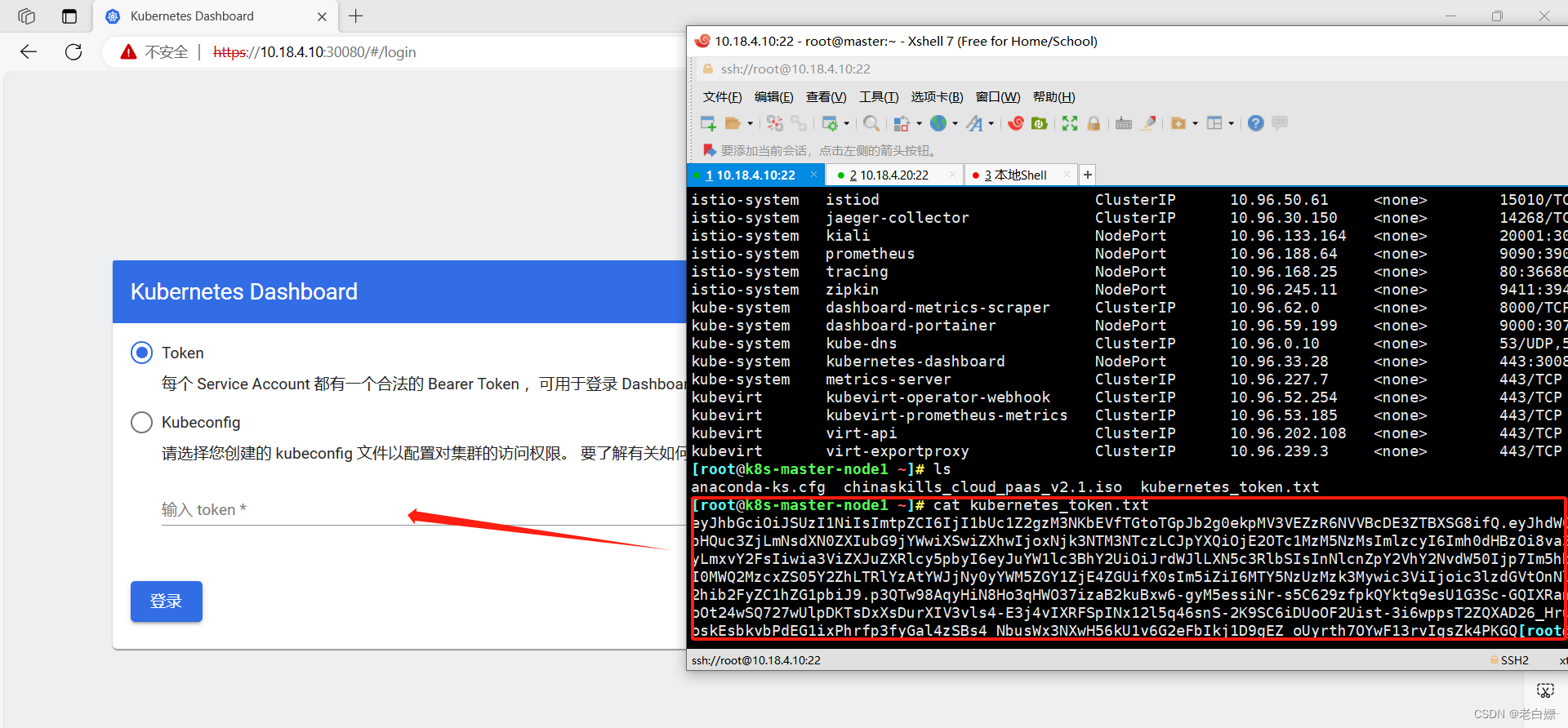
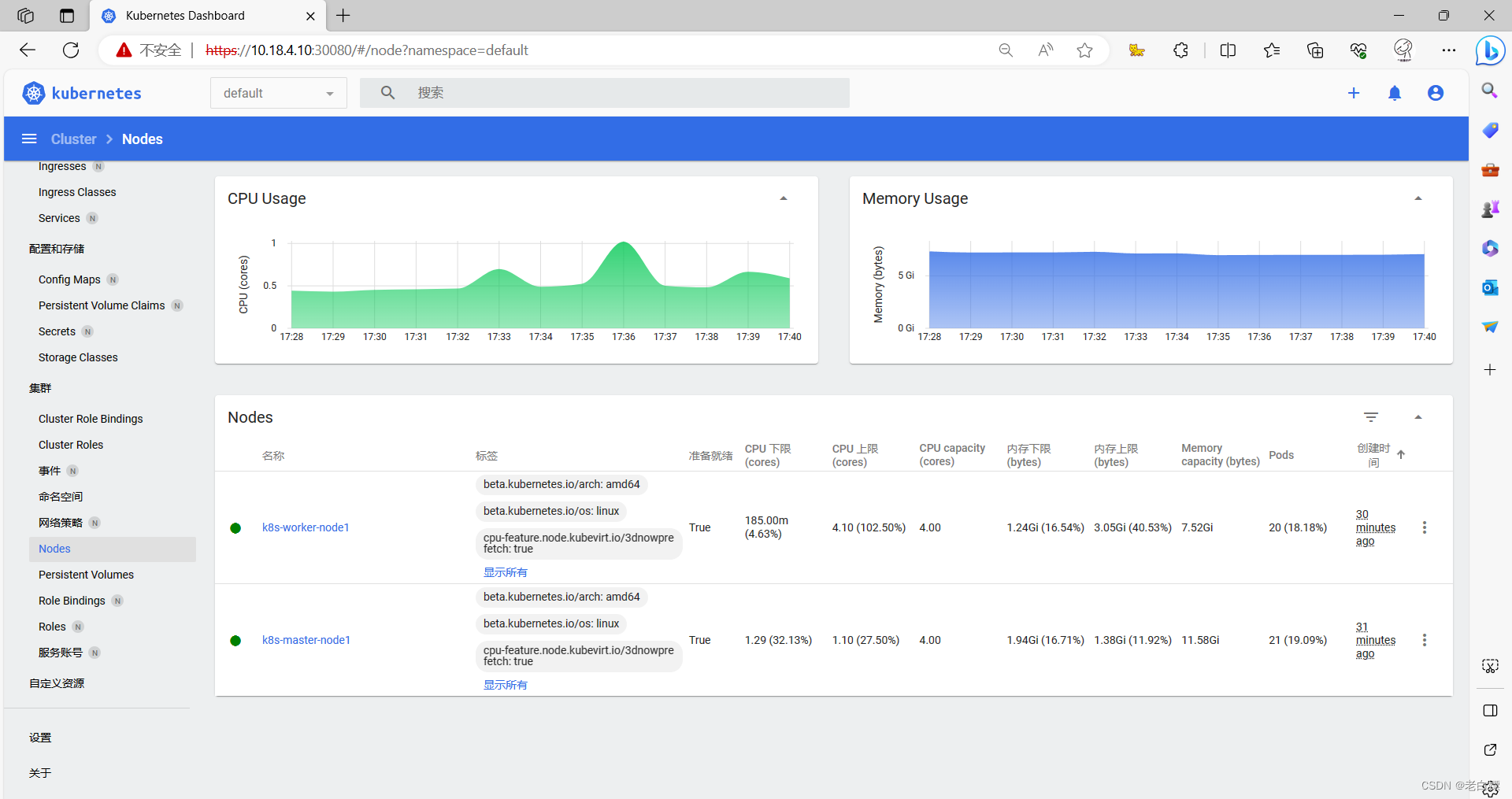
Kuberntes原生dashboard:
[Kubernetes Dashboard](https://10.18.4.10:30080/#/login)
在部署完成以后,会有token的生成,可以直接输入。
istio相关内容:
Prometheus是一款开源的、自带时序数据库的监控告警系统。目前,Prometheus已经成为Kubernetes集群中监控告警系统的标配。[Prometheus Server](http://10.18.4.10:39090)
Tracing与Jaeger:[Jaeger UI](http://10.18.4.10:36686/jaeger/search)
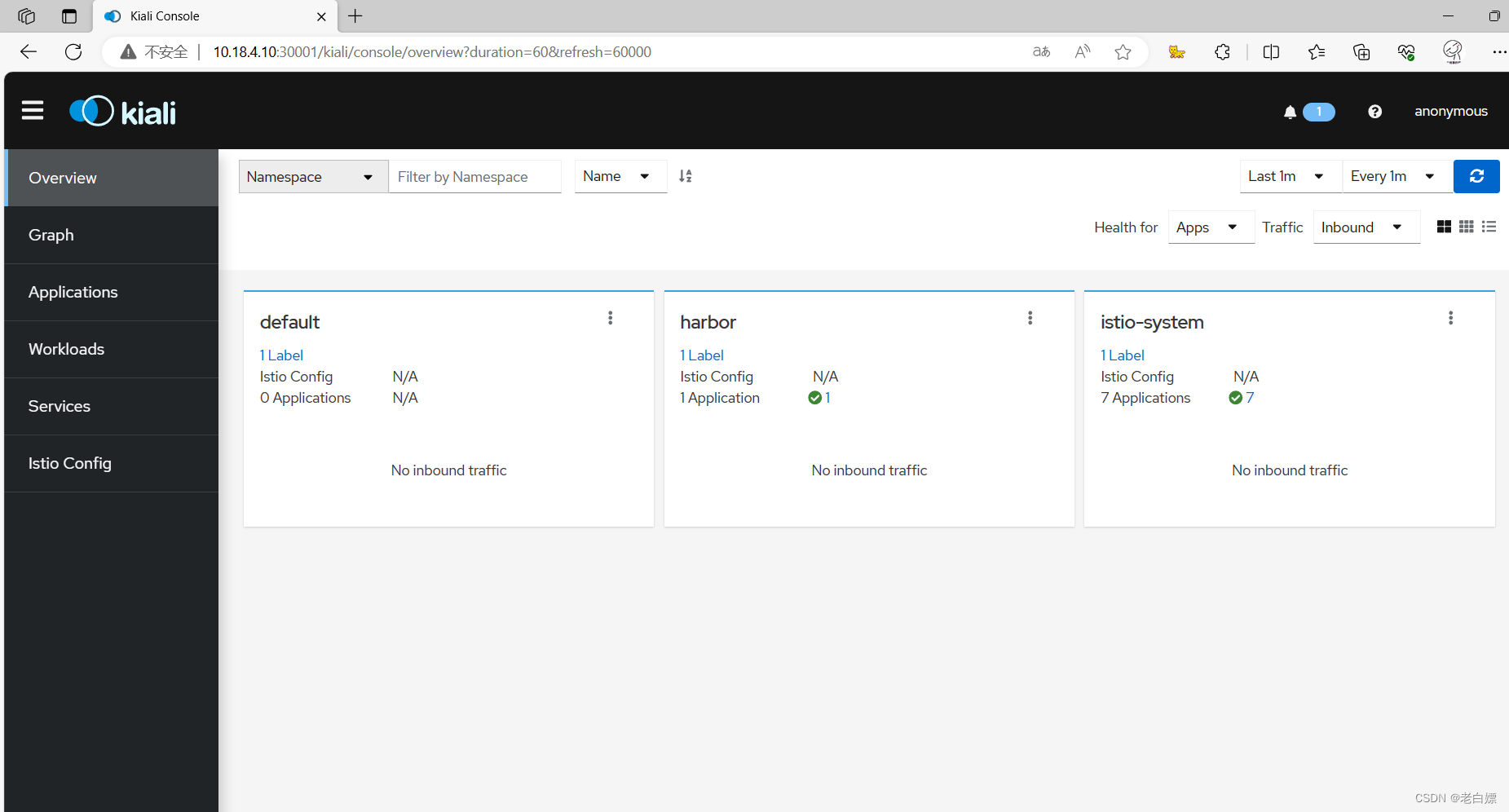
Kiali能通过推断流量拓扑来显示服务网格的结构,并显示网格的健康状况,提供了详细的指标、强大的验证、访问以及与 Jaeger 进行分布式跟踪的强大集成。http://10.18.4.10:30001/kiali/
Grafana是一款开源的跨平台可视化分析工具,主要用于大规模指标数据的可视化展示,可以帮助用户简化监控的复杂度。这里用于展示istio或者kubernetes集群相应的数据。
Grafana URL :http://10.18.4.10:33000/
Portainer是一款开源的容器管理平台,支持多种容器技术,如Docker、Kubernetes和Swarm等。它提供了一个易于使用的Web UI界面,用于管理和监控容器和集群。Portainer旨在使容器管理更加简单和可视化,并且它适用于各种规模的容器环境,从个人计算机到企业级部署,而且能够一次性管理多种类型的多个集群。
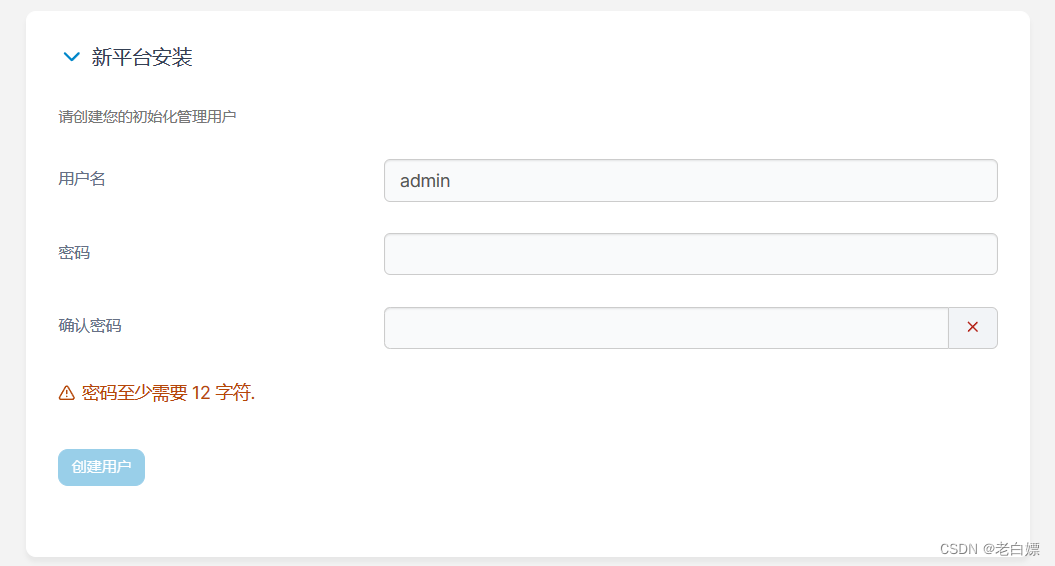
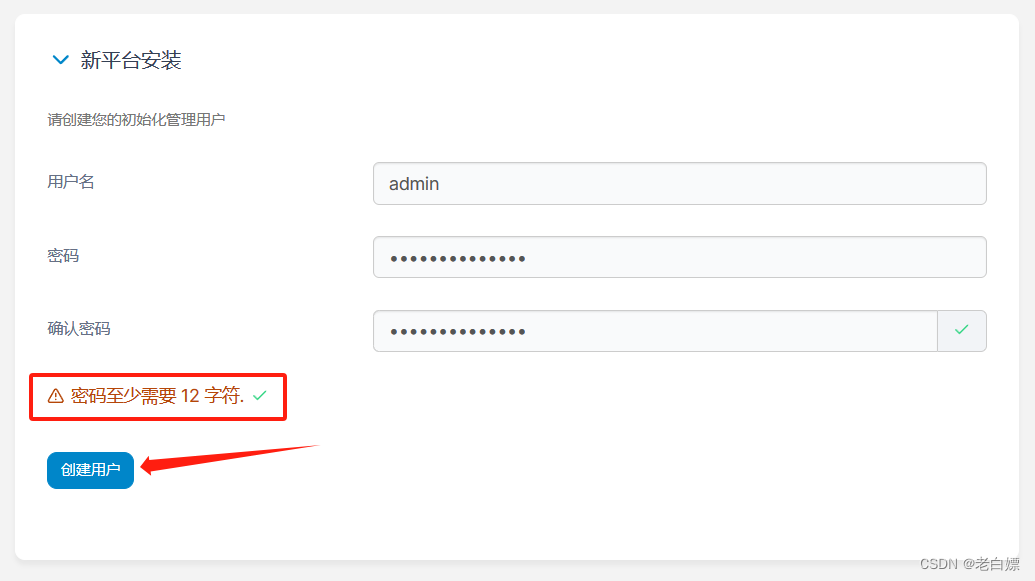
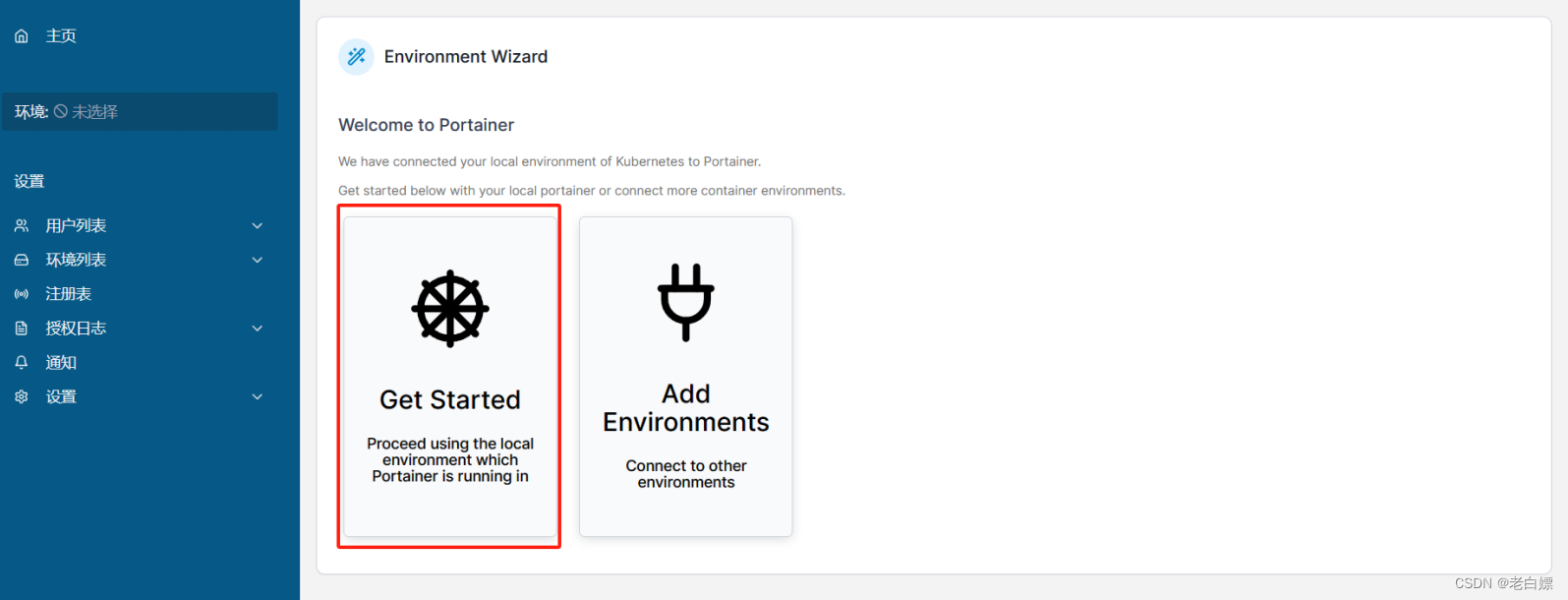
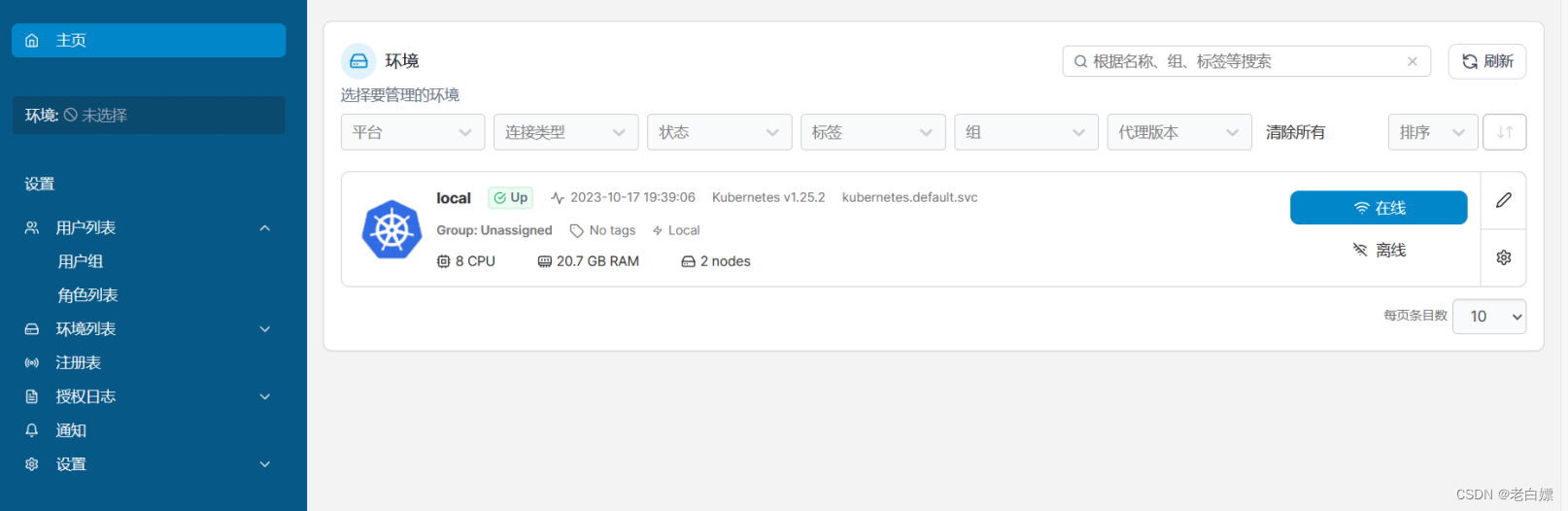
除了原生的dashboard以外,该镜像还提供有Portainer。
[Portainer](http://10.18.4.10:30777)
注意,如果长时间不对Potainer初始化,就会发生如下报错,直接删除掉提供服务的Pod,让其在创建一个Pod实例即可。

kubectl get pod -A | grep dash
kubectl delete pod -n kube-system dashboard-portainer-695648f848-bnljl