咸阳网站建设公司哪家好厦门seo优化推广
选择

传输层叫段 网络层叫包 链路层叫帧

A

2^16-2

C


D

C
70都没收到,确认号代表你该从这个号开始发给我了,所以发70而不是71

B

D

C
248&123=120
OSI 物理层 数据链路层 网络层 传输层 会话层 表示层 应用层

C
记一下304读取浏览器缓存
502错误网关
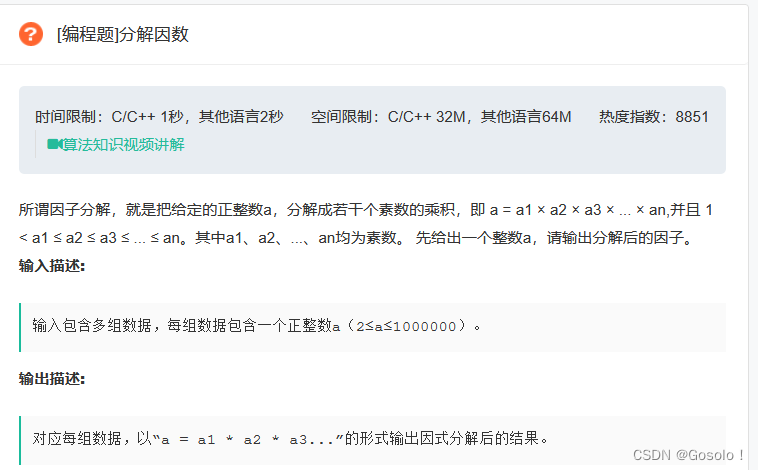
编程
分解因数
分解因数__牛客网
#include <iostream>
#include <vector>
using namespace std;
int main()
{int n;while(cin>>n){vector<int>nums;//2 3 7 42int tmp=n;for(int i=2;i*i<=n;i++){if(n%i==0){while(n%i==0) {nums.push_back(i);n/=i;}}}if(n!=1) nums.push_back(n);cout<<tmp<<" "<<"="<<" ";for(int i=0;i<nums.size()-1;i++){cout<<nums[i]<<" "<<"*"<<" ";}cout<<nums.back()<<endl;}return 0;
}美国节日
美国节日__牛客网
#include <iostream>
#include <cstdio>
using namespace std;
// 根据 年-月-日 通过蔡勒公式计算当前星期几
int day_of_week(int year, int month, int day){if(month == 1 || month == 2){month += 12;year -= 1;}int century = year / 100;year %= 100;int week = century / 4 - 2 * century + year + year / 4 + (13 * (month + 1)) / 5 + day - 1;week = (week % 7 + 7) % 7;if(week == 0){week = 7;}return week;
}
// 给定年月和第几周的星期几,求出是该月的几号几号
int day_of_demand(int year, int month, int count, int d_of_week){int week = day_of_week(year, month, 1);// 计算该月1号是星期几// 1 + 7(n - 1) + (所求星期数 + 7 - 1号星期数) % 7int day = 1 + (count - 1) * 7 + (7 + d_of_week - week) % 7;return day;
}
// 元旦
void new_year_day(int year){printf("%d-01-01\n", year);
}
// 马丁·路德·金纪念日(1月的第三个星期一)
void martin_luther_king_day(int year){printf("%d-01-%02d\n", year, day_of_demand(year, 1, 3, 1));
}
// 总统日(2月的第三个星期一)
void president_day(int year){printf("%d-02-%02d\n", year, day_of_demand(year, 2, 3, 1));
}
// 阵亡将士纪念日(5月的最后一个星期一)
void memorial_day(int year){// 从 6 月往前数int week = day_of_week(year, 6, 1);// 星期一的话,从 31 号往前数 6 天,否则,数 week - 2 天int day = 31 - ((week == 1) ? 6 : (week - 2));printf("%d-05-%02d\n", year, day);
}
// 国庆
void independence_day(int year){printf("%d-07-04\n", year);
}
// 劳动节(9月的第一个星期一)
void labor_day(int year){printf("%d-09-%02d\n", year, day_of_demand(year, 9, 1, 1));
}
// 感恩节(11月的第四个星期四)
void thanks_giving_day(int year){printf("%d-11-%02d\n", year, day_of_demand(year, 11, 4, 4));
}
// 圣诞节
void christmas(int year){printf("%d-12-25\n\n", year);
}
// 美国节日
void holiday_of_usa(int year){new_year_day(year);martin_luther_king_day(year);president_day(year);memorial_day(year);independence_day(year);labor_day(year);thanks_giving_day(year);christmas(year);
}
int main(){int year;while(cin >> year){holiday_of_usa(year);}return 0;
}