怎么建设手机网站网站策划专有技术
最近在学习BI软件,因为最近工作中需要开发报表,因此选用了国内市场比较热门的报表工具——Finereport和Spreadsheet进行学习。
BI软件经常会定期发布新的版本,增加新的功能模块,或者对现有功能进行增强,提升运行效率。如果已经安装部署过旧版本,现在又需要使用新版本的某些功能,就需要对系统进行升级,将其更新到最新版本。
在使用过程中,它们的版本各自都进行了更新,因此我想分享一些更新过程中的体会和对比。
spreadsheet的升级方法:
停止Tomcat应用服务器。为了升级更顺畅,按照他们的文档的说明需要删除一些文件夹的内容,具体如下:
①删除Tomcat\webapps\ 目录下的spreadsheet文件夹。如果还有spreadsheet.war文件,也一并删除。
②清除Tomcat\temp\ 目录下 ( 注意不是把temp删除,是删除temp里边的内容 ) 的所有文件和文件夹。
③清除Tomcat\work\ 目录下 ( 注意不是把work删除,是删除work里边的内容 ) 的所有文件和文件夹。
停止服务及清除相关文件后,在服务器所在目录路径更换war包
接下来可以重启应用服务器
重启应用服务器,此时系统会自动进行升级工作。此过程可能会比较耗时,根据所升级版本的跨度大小,以及系统中开发的报表资源多少,升级过程可能会从几分钟到几十分钟不等。
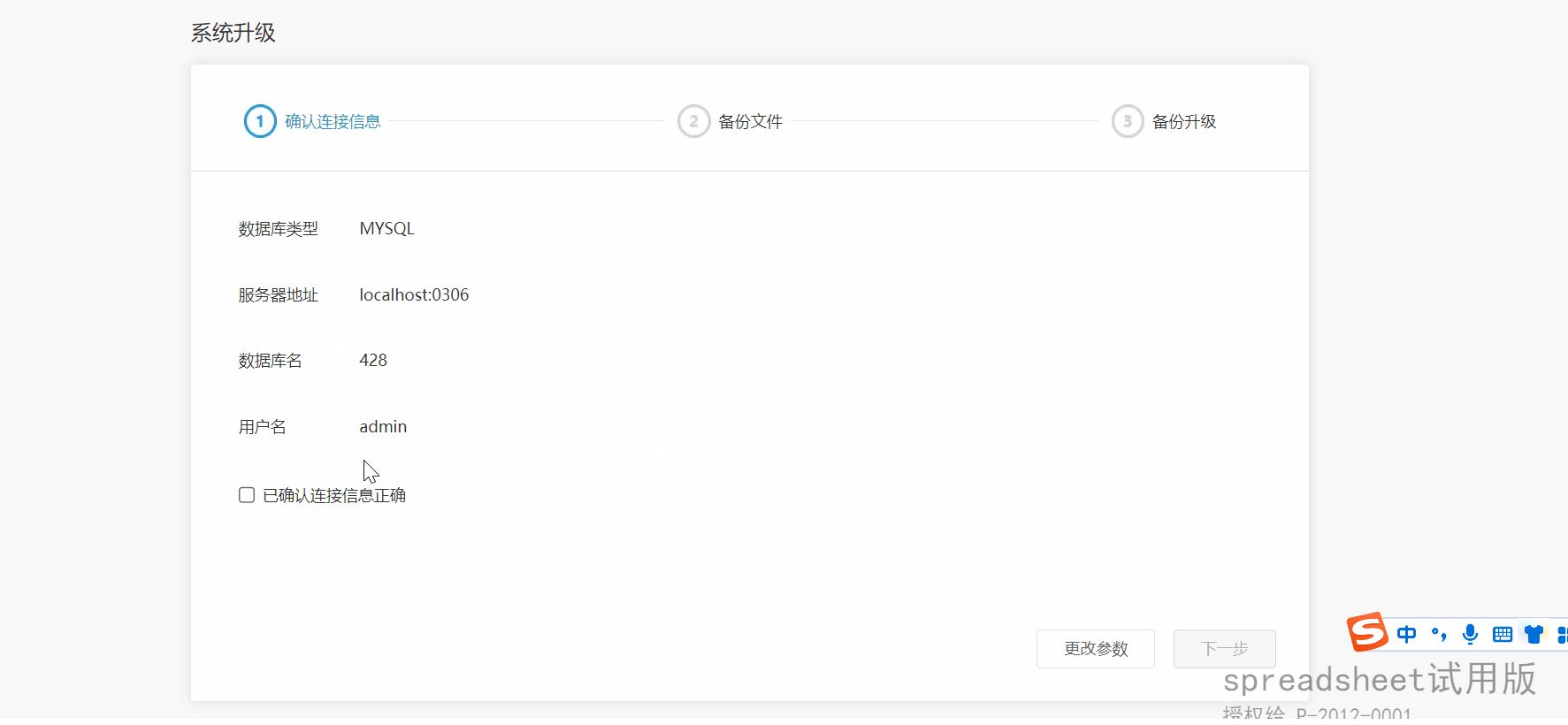
spreadsheet版本回退:
系统不支持直接替换旧 war 包以回退版本,只能重新部署旧版本的 war 包并在空库上恢复旧版本的知识库。
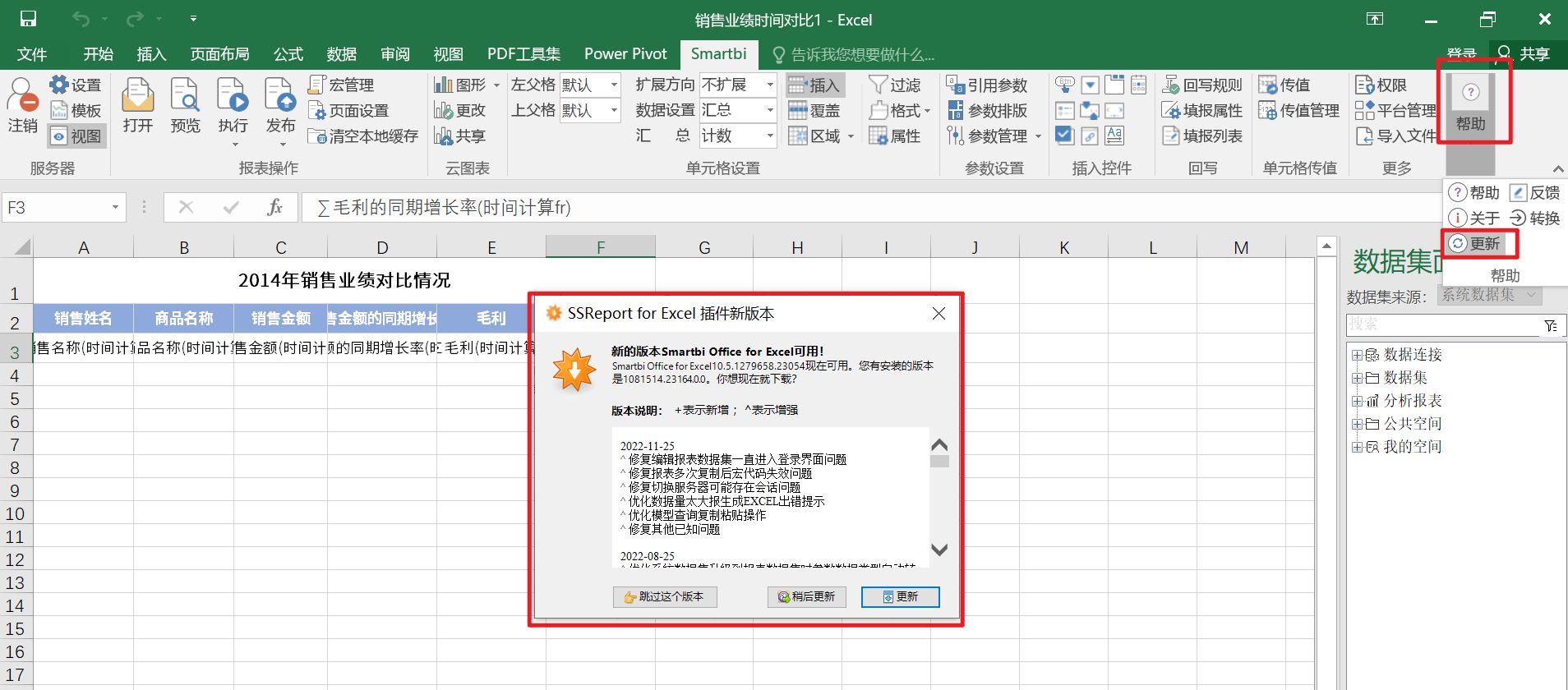
spreadsheet插件的升级方法,点击帮助-更新,设计器会根据当前连的服务器版本进行同步更新
FineReport 的升级方法:
FineReport 11.0 设计器提供了设计器 JAR 包的一键升级功能,升级更为方便。需要联网操作。打开设计器,点击菜单栏「帮助>更新升级」
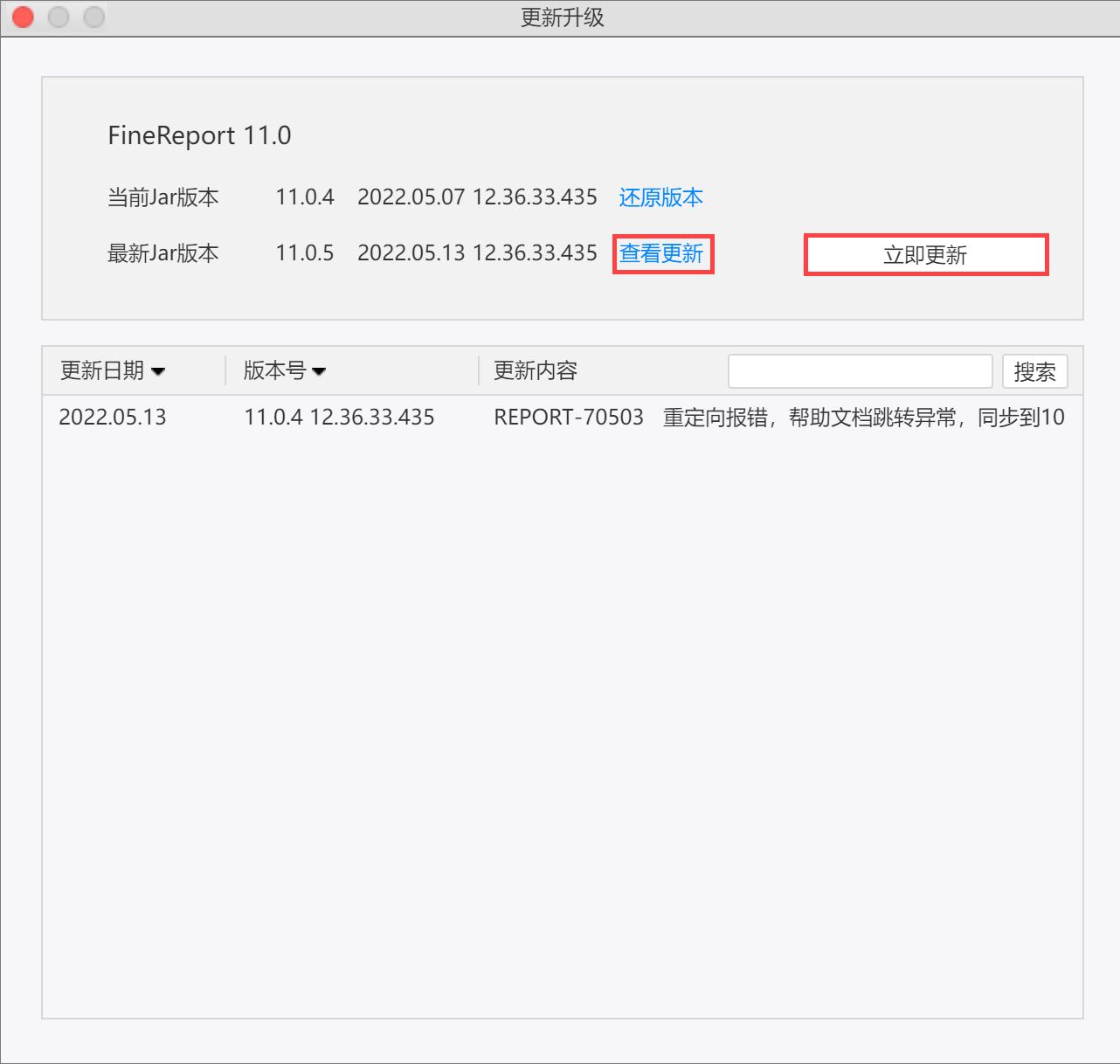
打开更新升级界面,在 JAR 包更新一栏会显示当前版本号和最新 JAR 版本号。下方版本更新日志中可以看到每个版本对应更新的功能以及更新的版本号和日期。
若相对当前版本,有新版本可更新,在上方的「最新JAR」后会出现「立即更新」(否则不显示立即更新按钮。)如下图所示:
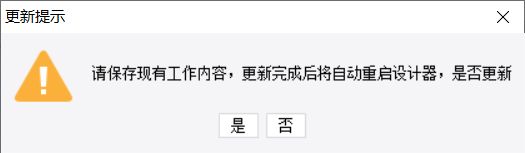
点击「立即更新」按钮,触发更新后,系统提示保存重要信息,如下图所示:
设计器更新时由于要获取比对 JAR 包内容并解析,会出现几秒的延迟,获取更新信息中,如下图所示:

按照提示更新,下方显示下载 JAR 包进度,如下图所示:

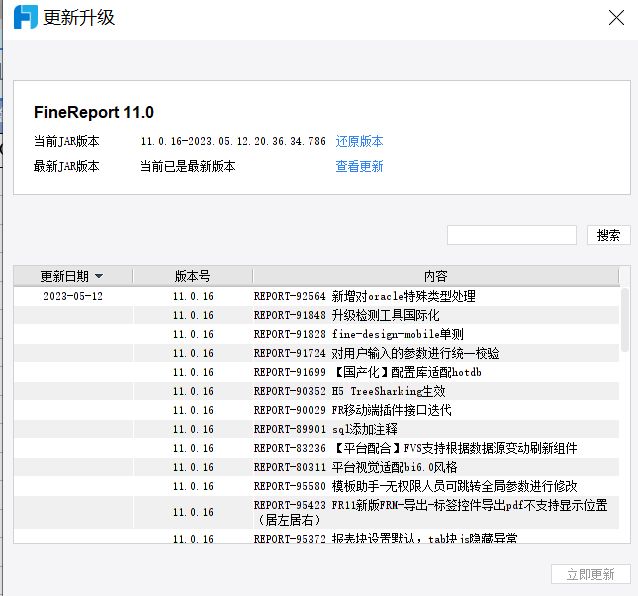
JAR 包更新完后,系统将立即自动重启。重启之后 JAR 包更新一栏显示为「已经是最新版本」,即完成版本更新。如下图所示:
FineReport 的版本回退
更新升级后,在页面会出现「还原版本」的按钮,用户若想还原到之前的版本,可以点击此处还原回之前的 JAR 包版本。如下图所示:
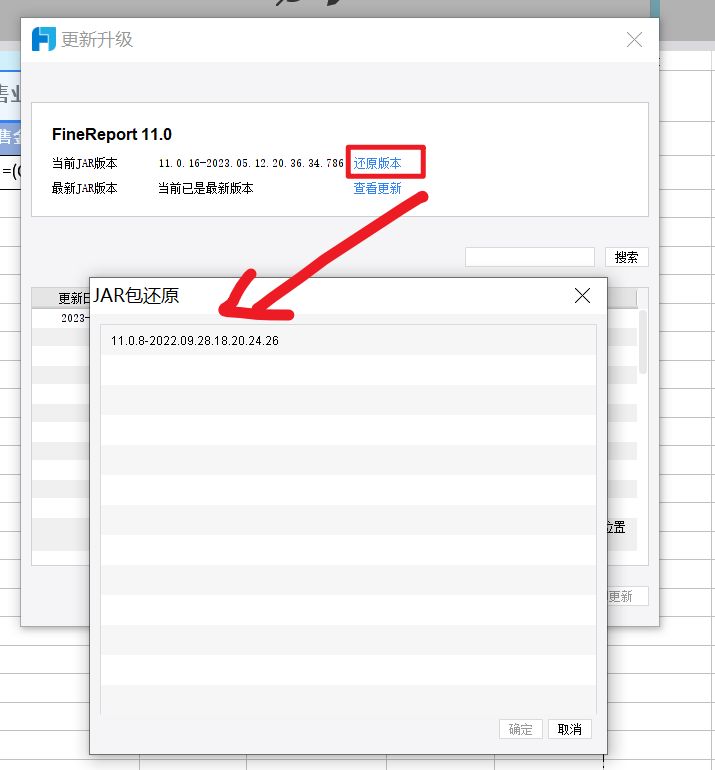
点击确定后,会出现询问重启的弹框,可选择「稍后重启」或「立即重启」,如下图所示:
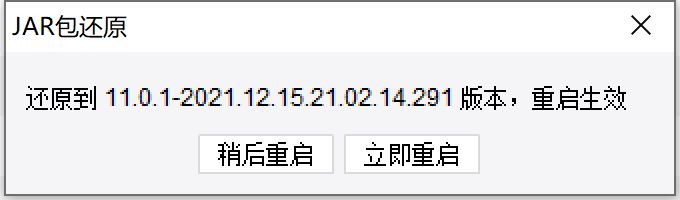
如果选择「立即重启」,你就可以开始回到以前的版本了;如果选择「稍后重启」,那么现在不会回退,等到下一次设计器重启时再回退。选择之后,设计器重启时,会自动进行更改JAR包版本的回退操作,如下图所示,操作结束后,设计器就可以回退到以前的版本了。
总结:总的来说,两者基本可以实现系统的平滑升级,用户可以从旧版本顺利升级到最新版本,而且不会影响已经开发的任何报表资源。