前言
这也是一个笔记,就是计划用jmeter做性能测试,但是这里是只要将数据放到kafka的topic里,后面查看下游业务处理能力。
一、方案
因为只要实现数据放到kafka,参考了下博友的方案,可行。
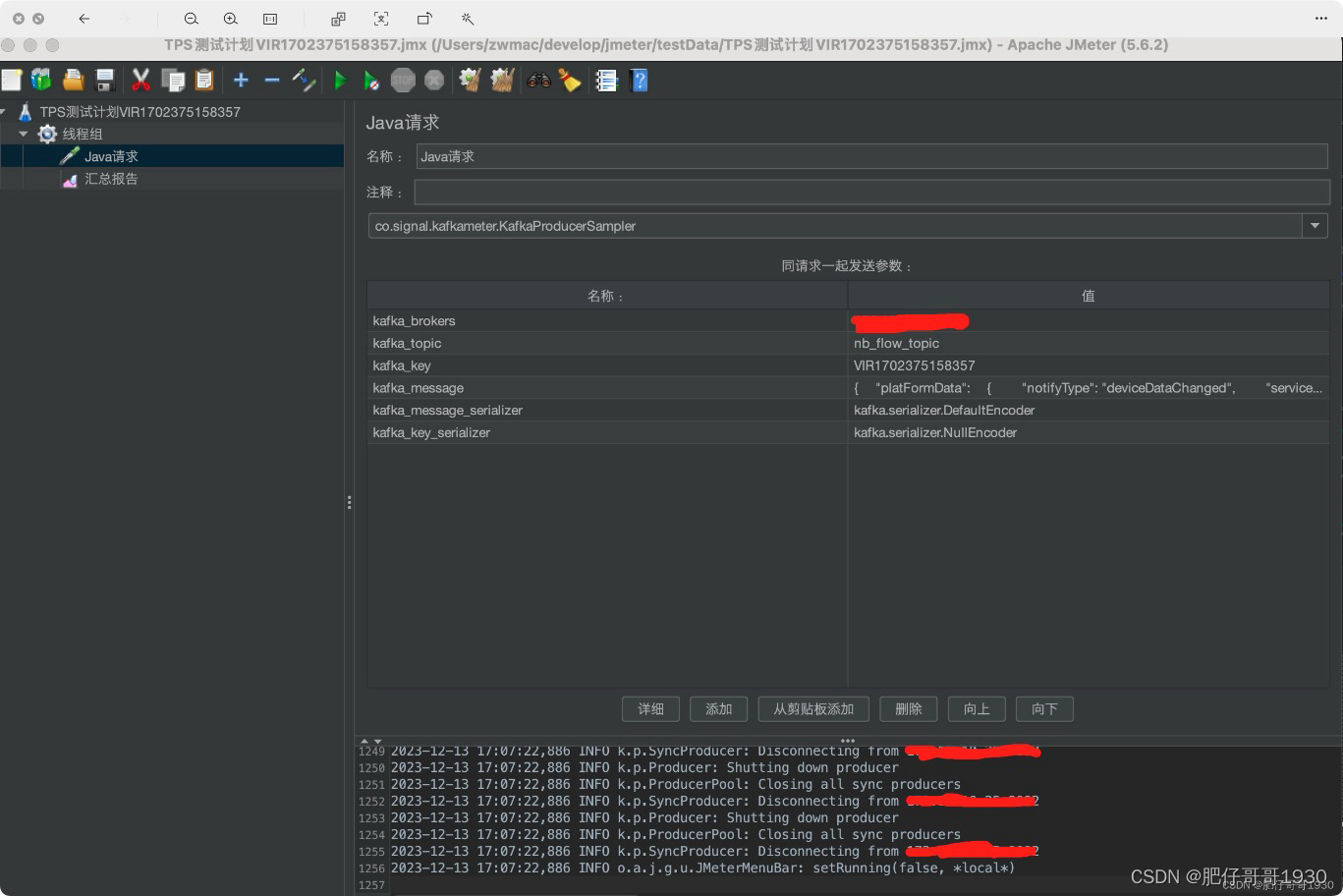
二、方案验证
详细过程就不重复写了。直接上博友的链接吧。
1.方案一
https://blog.csdn.net/shan286/article/details/105216381
2.方案二
https://blog.csdn.net/jwcxs_m/article/details/103530869
个人认为方案二简单些。
总结
就是笔记,自己备忘,也希望博友一次能找到2个方案,帮到大家