校园网站设计代码wordpress PHP合并js
目录
一、泛型
1、概述
2、通配符
3、有界类型
二、集合
1、概述
2、迭代器接口
三、集合类
1、Collection接口
2、List接口
3、Set接口
4、Queue接口
5、Map接口
四、集合转换
五、集合工具类
一、泛型
1、概述
从JDK5.0开始,Java引入泛型类型,将数据类型实现参数化,提高代码了重用性,使得程序更加灵活、安全和简洁。
泛型可以被使用于类、接口、方法的定义中,实现泛型类、泛型接口、泛型方法。
泛型类的一般定义方法,以及实现实例化对象,可以参考C++的泛型使用方法。
下面给出一个实例:
//创建泛型类
public class Generic <T>{private T data;public Generic(T data){this.data=data;}public void show(){System.out.println("数据类型为:"+data.getClass().getName());System.out.println("数据为:"+this.data);}
}//主函数
public class Demo {public static void main(String[]args){Generic<String> s=new Generic<String>("张三"); //创建实例,实例化类型为StringGeneric<Integer> i=new Generic<Integer>(123); //创建实例,实例化类型为Integers.show();i.show();}
}输出:
数据类型为:java.lang.String数据为:张三
数据类型为:java.lang.Integer
数据为:123
2、通配符
当使用一个泛型类时,应该为泛型类传入一个实参,否则会提出泛型警告,但如果在定义一个方法时,无法确定泛型实例化变量类型,那么需要使用通配符“?”来表示一个未知类型,从而解决不能动态选择实例的缺点。
紧接着上一个实例,添加这样一个方法:
public static void showtype(Generic <?> g)
{g.show();
}主函数使用showtype(i)和showtpe(s)同样可以达到i.show(),s.show()的作用,这也是多态的另一种体现。
3、有界类型
有界类型分为两种:extends,super,一般用来在泛型的尖括号<>中指代声明类型的上界和下界。
在泛型类中使用:
public class Generic <T extends Math> //指定T类型的上界为Math
public class Generic <T super String> //指定T类型的下界为String
在泛型方法中使用:
public class Generic <? extends Math>{ //指定T类型的上界为Math
//方法体...
}
public class Generic <? super String> { //指定T类型的下界为String
//方法体...
}
二、集合
1、概述
Java中的集合类类似于C++中的STL,用于实现一些常见的数据结构。Java的集合类主要由两个接口派生出来:Collection和Map
Collection集合体系下有三个接口,Set(无序,不可重复的集合)、List(有序、可以重复的集合)、Queue集合(队列集合)
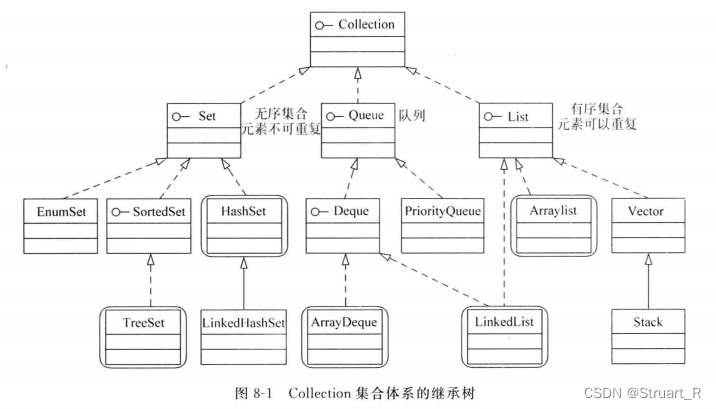
Map集合用于保存具有映射关系的数据,由Key-Value键值对组成,key用于标识集合中的每项数据,所以不可重复。
2、迭代器接口
迭代器可以采用统一方式,对Collection集合中的元素进行遍历操作,由于Iterable接口是Collection接口的父接口,所以迭代器的集合类可迭代的,都支持foreach循环遍历。
Iterator接口中的方法:
| boolean hasNext() | 判断是否有下一个可访问的元素 |
| E next() | 返回可访问的下一个元素 |
迭代器接口实现:
import java.util.ArrayList;
import java.util.Iterator;
public class test {public static void main(String[] args){ArrayList<String>list=new ArrayList<>();list.add("apple");list.add("banana");list.add("pear");Iterator<String> iterator=list.iterator(); //通过泛型对象调用iterator()方法while(iterator.hasNext()) //for each遍历{System.out.println(iterator.next());}}
}三、集合类
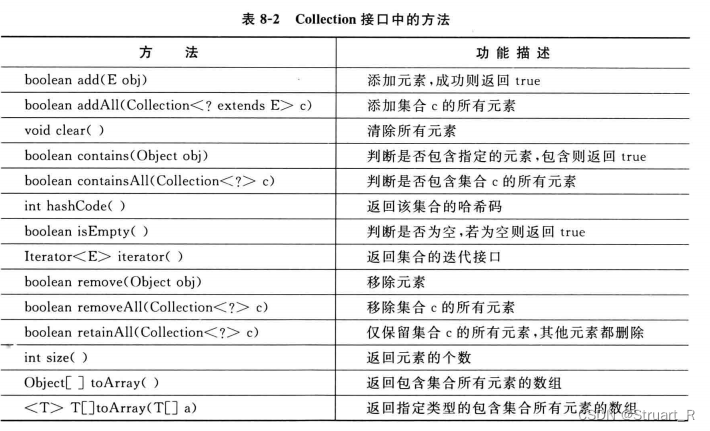
1、Collection接口
Collection接口作为Set、Queue、List接口的父接口,本身没有提供获取某个元素的方法,但可以通过iterator()方法来遍历集合中所有元素。
对于产生的异常:不建议将同一个集合Collection中存储不同类型的对象,不要将不兼容的对象添加进集合中,另外在执行add、remove这类指令时也容易引发异常。
一般来说在集合类的使用中不推荐使用Collection类。
2、List接口
List是Collection接口的子接口,用于存放有序、可重复的集合。
List接口的常用方法:

在List接口中有两个实现类,ArrrayList(数组列表)和Vector(向量),完全继承List的所有方法。
ArrayList和Vector的区别在于ArrayList是非线程安全的,而Vector是线程安全的,所以推荐使用ArrayList集合。
ArrayList进行for-each遍历:
import java.util.ArrayList;
public class ArrayListDemo {public static void main(String[] args){ArrayList<String> list= new ArrayList<String>();list.add("北京");list.add("南京");list.add("上海");for(String e:list) //for each遍历{System.out.println(e);}list.remove("北京"); //删除元素北京 System.out.println("第一个元素为:"+list.get(0)); //获取第一个元素}
}输出:
北京
南京
上海
第一个元素为:南京
另外Vector提供了一个Stack子类,用于模拟“栈”,有三个方法:peek(查看栈顶元素),pop(出栈),push(入栈)。
Stack<String> s=new Stack<String>();
for(int i=0;i<=5;i++)s.push(String.valueOf(i));
System.out.println("Stack入栈元素:");
for(int i=0;i<s.size();i++)System.out.println(s.get(i));
System.out.println("Stack出栈元素:");
for(int i=0;i<=5;i++)System.out.println(s.pop());输出:
Stack入栈元素:
1
2
3
4
5
Stack出栈元素:
5
4
3
2
1
3、Set接口
Set接口是一个不包含重复元素的集合,一般用于执行数学上的集合运算,如交集、并集,HashSet、TreeSet和EnumSet是Set接口的常见实现类。
HashSet:使用Hash算法存储集合中的元素,具有良好的存取查找功能。
TreeSet:采用Tree算法可以保证元素处于排序状态,TreeSet支持两种排序方式:自然排序和定制排序,默认情况采用自然排序。
EnumSet:为枚举类设计的集合类,其所有元素必须为指定的枚举类型,EnumSet中元素是有序的,按照枚举值顺序进行排序。
在TreeSet类进行排序时,会调用类内方法compareTo方法,所以我们可以通过重写默认排序时调用的compareTo方法,来实现排序的过程。
4、Queue接口
Queue为队列结构,采用先进先出方式排序每个元素,在继承于Collection接口的基础上,也提供了相应的队列的插入、获取、查找操作。
Queue接口有若干实现类:LinkedList(链表)、PriorityQueue(优先队列)、Deque(双向队列)。
(1)Queue
Queue接口的方法:

注意:Queue不能作为实例对象,不要创建Queue对象,只能创建Queue的子类对象。
Queue <String>q=new PriorityQueue<>(); //可以
Queue <String>q=new Queue<>(); //不可以(2)Deque
Deque是Queue的子接口,支持两端插入和移除元素。
Deque接口的方法:

(3)LinkedList
LinkedList链表是Deque和List两个接口的实现类,兼具队列和列表两种特性,但LinkedList不是线程安全的,当出现多线程访问同一实例时,必须手动同步。
对链表进行相应操作的代码:
import java.util.LinkedList;
public class linkedlistdemo {public static void main(String[] args){LinkedList<String> books=new LinkedList();books.offer("数据库");books.push("Java");books.offerFirst("C++");books.offerLast("操作系统");for(String i:books) //遍历元素System.out.println(i);System.out.println("链表第一个元素:"+books.peekFirst()); System.out.println("链表最后一个元素:"+books.peekLast());System.out.println("链表弹出栈顶元素:"+books.pop());System.out.println("链表弹出栈底元素:"+books.pollLast());System.out.println("链表第二个元素:"+books.get(1));}
}(4)ArrayDeque
ArrayDeque(数组双端队列),是Deque实现类,不继承于List,所以不能用add、remove进行添加、删除,但上面的链表在作为List子类情况下,还是改写了add和remove方法,使用offerfirst、pollfirst这一类栈相关的方法,其实更好理解一些。
ArrayDeque没有容量限制,不是线程安全的,禁止添加null元素,在作为堆栈时快于Stack,作为队列时快于LinkedList。
ArrayDeque的入队、出队、选择可以参考链表的操作,都是依赖于Deque的父类方法。
(5)PriorityQueue
PriorityQueue是Queue接口的实现类,优先级队列,可以按照自然排序、或者定制排序(就是修改compareTo),优先级队列不允许使用null元素,在自然顺序下也不允许插入不可比较对象,定制排序可以改compareTo的。
PriorityQueue要使用Queue接口内的方法,所以注意使用poll弹出,offer入栈。
import java.util.PriorityQueue;
import java.util.Queue;public class QueueDemo {public static void main(String[] args){Queue <String>q=new PriorityQueue<>();q.offer("张三");q.offer("李四");q.offer("王五");System.out.println("队列第一个元素,并移除"+q.poll());for(String i:q)System.out.println(i);}
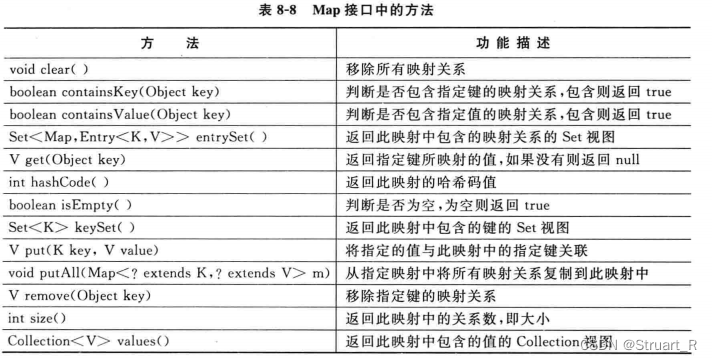
}5、Map接口
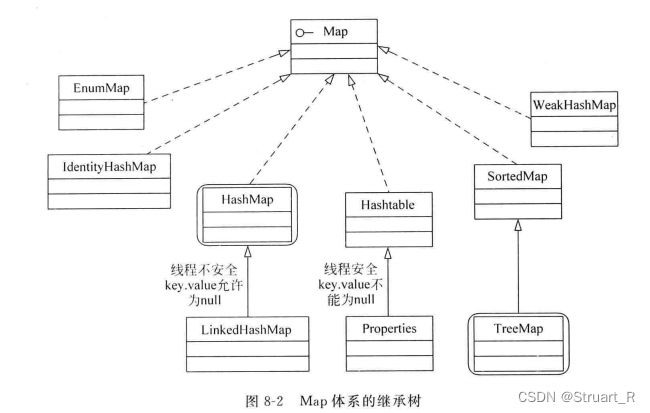
Map接口作为与Collection并列的一个接口,使用key-value键值对映射关系进行存储。
Map常用方法:
Map类有两个实现类,分别为HashMap和TreeMap,类似HashSet和TreeSet的区别,HashMap是无序的映射集合,允许使用null作为键或值,TreeMap可以进行自然排序或定制排序。
四、集合转换
集合转换方法:
(1)entrySet():返回一个包含了Map中元素的集合,每个元素都包括键和值
(2)keySet():返回Map中所有键的集合
(3)values():返回Map中所有值的集合 (注意不是valueSet)
HashMap<Integer,String>hm=new HashMap(); //创建哈希集合
/*省略若干增删操作
*/
Set<Entry<Integer,String>>set=hm.entrySet(); //返回键值对
set<Integer>keyset=hm.keySet(); //返回键
set<String>=hm.values(); //返回值五、集合工具类
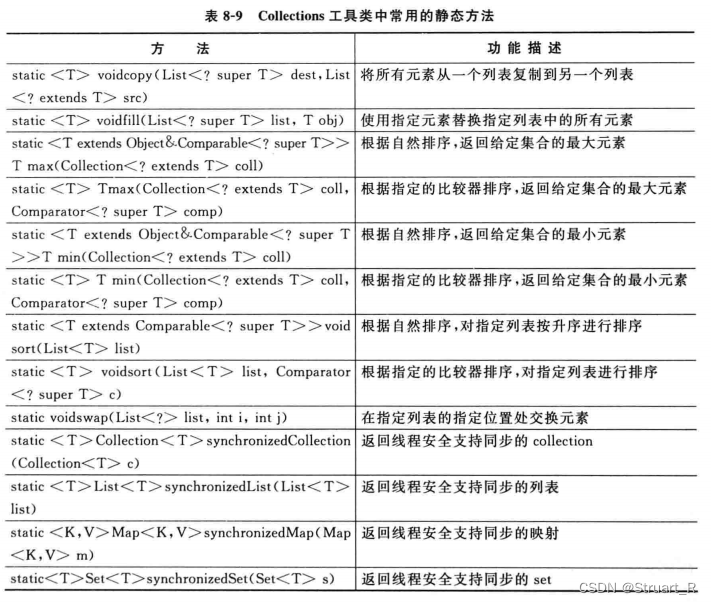
集合工具类(辅助工具类)有两个:Collections和Arrays。
Collections提供对集合的常用静态方法,而Arrays工具类提供对数组的常用静态方法。
Collections工具类方法:
Arrays工具类方法:

参考书籍:《Java 8 基础应用与开发》QST青软实训编