宁波网站推广优化公司电话网站开发维护工作

哈医大团队利用网络药理学+PPI分析+分子对接三联策略,解码灵芝孢子调控AKI凋亡的精准机制
在当今科研前沿领域,网络药理学作为连接传统药学与现代系统生物学的关键纽带,正重塑着药物研发与疾病机制探索的版图。从多组学技术融合揭示中药复方复杂作用网络,到人工智能驱动的靶点预测加速创新药物发现,该领域成果不断涌现,引领医学研究迈向“精准化”与“系统化”新时代。在这样的学术浪潮下,一篇发表于《Journal of Ethnopharmacology》期刊的论文,凭借独特的研究视角与严谨的实验设计,为我们展示了网络药理学在阐释传统中药治疗现代疾病中的巨大潜力。接下来,让我们一同深入剖析这一研究成果。
https://doi.org/10.1016/j.jep.2025.120075

正式介绍
基本信息
-
论文标题:基于网络药理学及实验验证探究灵芝孢子通过p53/Caspase 3信号通路诱导凋亡保护急性肾损伤的机制
-
发表期刊:Journal of Ethnopharmacology,中科院医学大类分区2区,IF=4.8003
-
发表日期:2025年5月30日在线发表
研究背景
急性肾损伤(AKI)具有高发病率和死亡率,临床缺乏特效治疗药物。传统中药灵芝在《神农本草经》中记载“利水道、益肾气”,其孢子(GLS)因活性成分丰富被认为具有肾脏保护潜力,但作用机制尚不明确。网络药理学作为连接中药多成分与疾病多靶点的桥梁,可系统解析GLS干预AKI的潜在通路,而分子生物学与光谱技术的结合能为机制验证提供多维证据。
研究思路
成分鉴定:采用UPLC-Q-Tof MS分析GLS中的三萜皂苷类成分;网络构建:通过多数据库筛选GLS活性成分及AKI相关靶点,构建“GLS-化合物-靶点-AKI”网络;核心靶点筛选:利用STRING分析PPI网络,结合GO/KEGG富集确定关键通路;分子对接:通过AutoDock和PyRx验证核心成分与靶点的结合能力;动物实验:构建庆大霉素诱导的AKI大鼠模型,检测GLS对肾功能、组织病理及凋亡相关蛋白的影响;光谱分析:利用SERS技术表征肾脏组织的凋亡相关分子特征。
研究亮点
方法创新:首次将SERS技术应用于AKI肾脏凋亡组织的光谱学观察,通过特征峰(如1170 cm⁻¹、1221 cm⁻¹)揭示GLS对细胞代谢的调节作用;机制创新:提出GLS通过抑制p53过表达,下调BAX、Caspase-3等凋亡蛋白,上调Bcl-2从而减轻肾脏细胞过度凋亡的新机制;技术整合:将网络药理学预测与分子对接、组织病理、光谱分析等多技术结合,形成系统的中药机制研究范式。
数据来源和生物信息方法
1、数据来源
GLS活性成分:SwissTarget Prediction、PubChem、TCMSP、Herb数据库;AKI相关靶点:OMIM、GeneCards、DrugBank数据库;蛋白互作:STRING数据库(人类来源,置信度≥0.9);富集分析:Metascape数据库(GO/KEGG)。
2、生物信息方法
网络构建:使用Cytoscape 3.9.1构建“中药-成分-靶点-疾病”网络,通过MCODE工具进行模块分析;分子对接:PyRx进行批量对接,AutoDock 1.5.7和PyMOL进行精确对接及可视化;统计分析:One-way ANOVA及非配对t检验,GraphPad Prism 8.0处理数据。
主要结果
1、GLS成分鉴定
鉴定出30种化合物,包括灵芝酸D、灵芝酸Mg、灵芝酸D‡等三萜皂苷类成分,保留时间0.5-11.4 min(图1A/B为正负离子模式色谱图)。小结:三萜类化合物为GLS干预AKI的潜在活性成分。
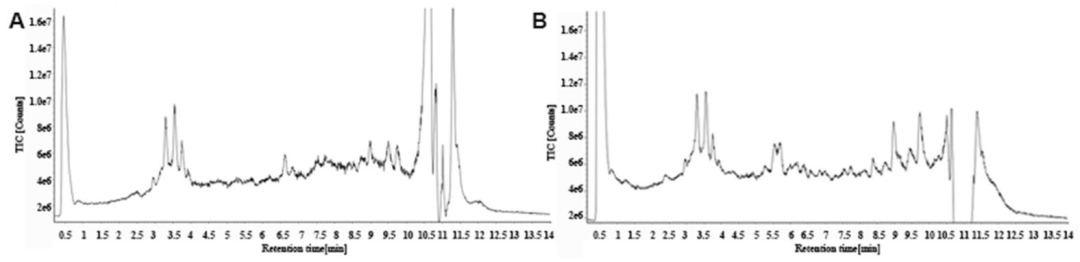
图1:GLS的UPLC-Q-Tof MS离子色谱图
2、网络药理学分析
GLS-AKI交集靶点:筛选出77个GLS成分对应136个靶点,与841个AKI靶点交集得到39个核心靶点(图2A);PPI网络:核心靶点包括TNF、IL6、PTGS2、TP53、BCL2等(图2B),GO分析显示涉及激素反应、细胞凋亡调节等生物过程(图3A),KEGG富集到癌症通路、AGE-RAGE信号等(图3B)。小结:p53/Caspase 3信号通路为GLS干预AKI的关键通路。
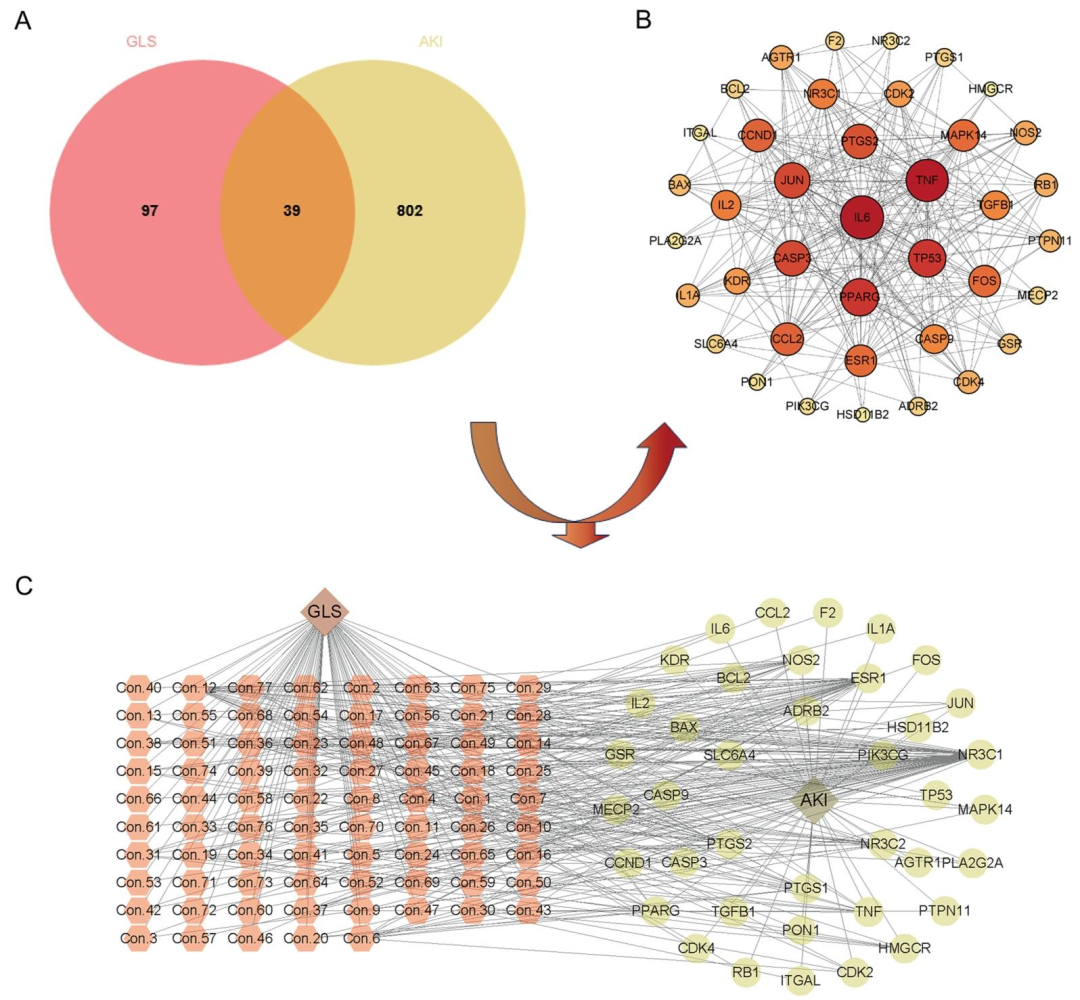
图2:GLS治疗AKI的网络分析
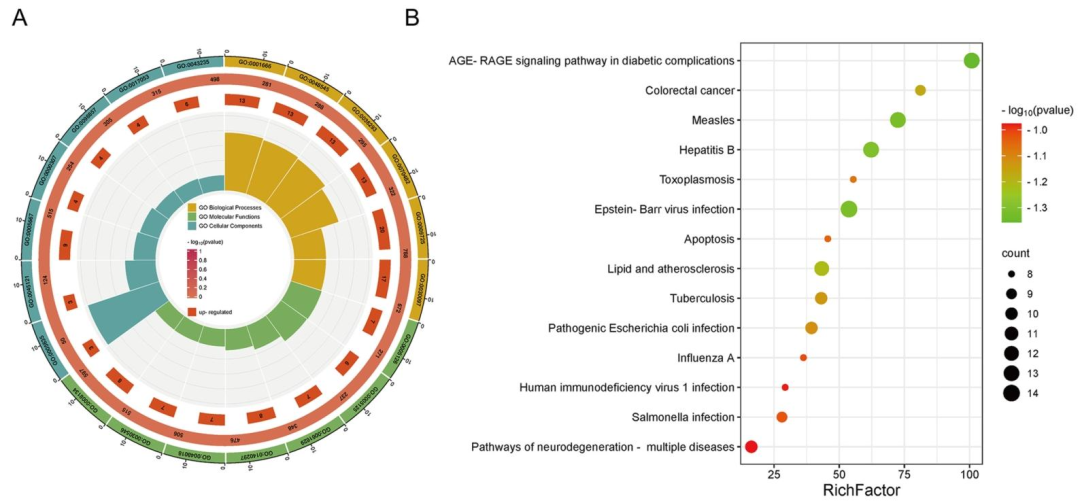
图3:核心靶点的通路与模块分析
3、分子对接
GLS成分与Caspase 3的对接能量最低(AutoDock结合能-8.86 kcal/mol,PyRx结合亲和力-9.6 kcal/mol),灵芝酸D‡与BAX、Caspase 3结合能力最强,灵芝酸Mg与细胞色素C结合紧密(图7A/B)。小结:GLS成分可通过与凋亡相关蛋白结合发挥保护作用。
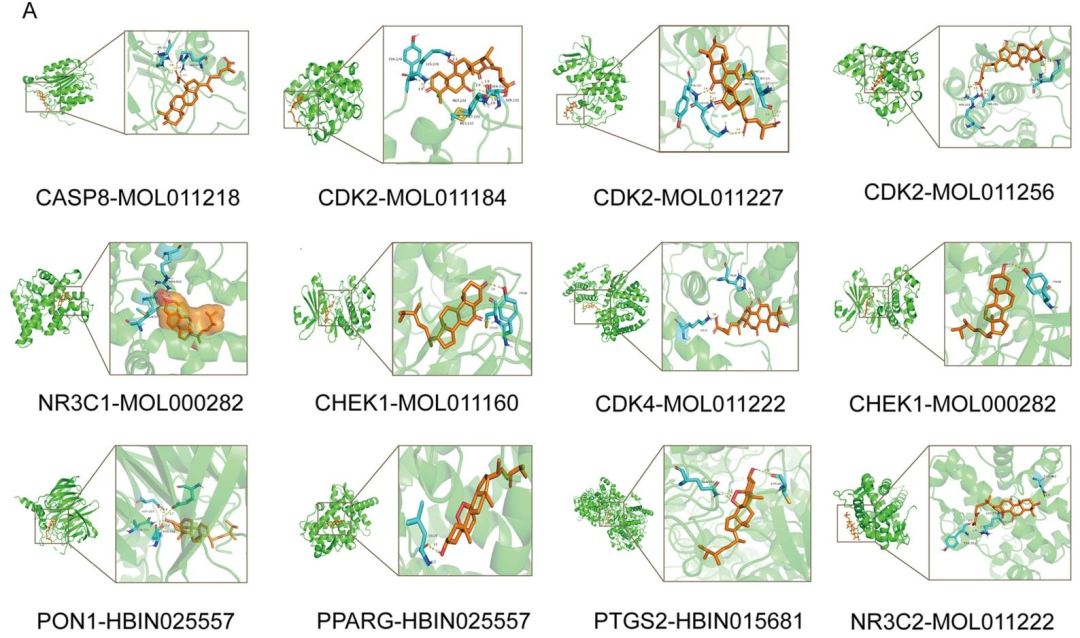
图6:第一部分网络药理学分子对接结果(77个预测化合物与蛋白)
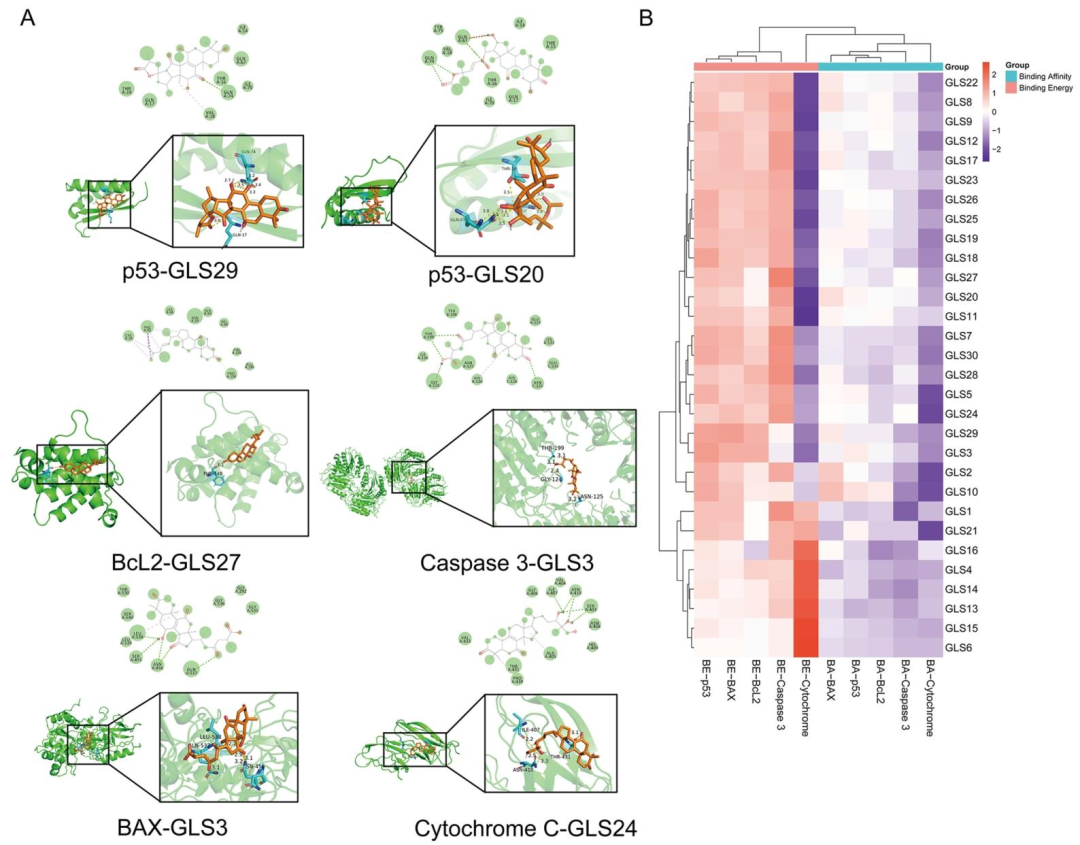
图7:第二部分分子对接结果
4、动物实验
肾功能指标:GLS显著降低AKI大鼠血清肌酐(Crea)、尿素氮(Urea)、尿酸(UA)及N-乙酰-β-葡萄糖苷酶(NAG)水平(图4D-G),肾脏系数改善(图4C);组织病理:H&E染色显示GLS减轻肾小管损伤(Paller评分降低,图4H),MASSON染色显示肾间质纤维化减轻(胶原沉积减少,图4I/5);凋亡蛋白:Western Blot表明GLS下调p53、BAX、Cleaved Caspase-3及细胞色素C表达,上调Bcl-2表达(图8),TUNEL染色显示凋亡细胞比例降低(图9)。小结:GLS通过抑制p53介导的凋亡通路减轻肾脏损伤。
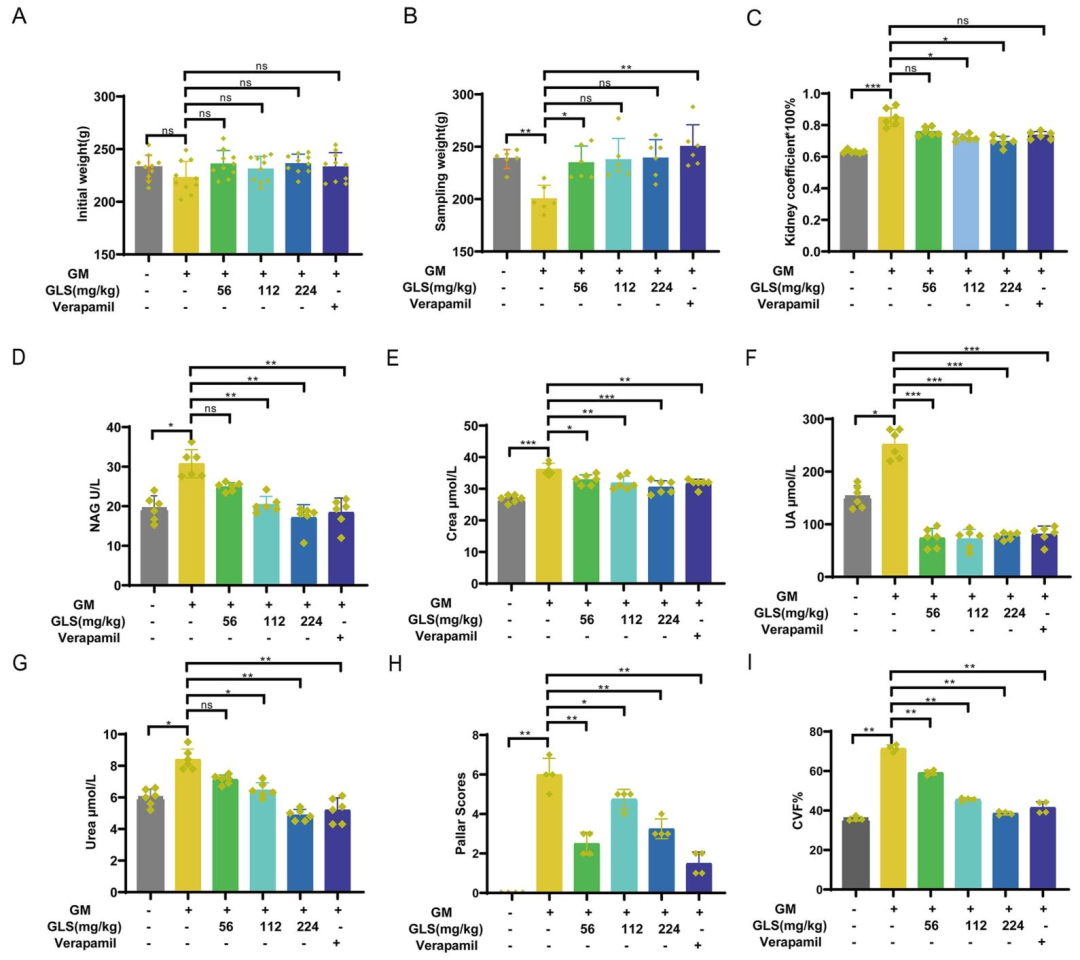
图4:GLS对AKI的影响
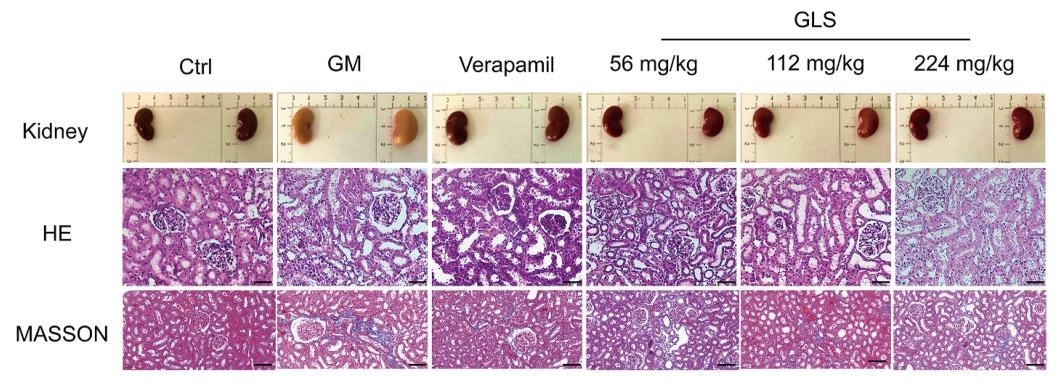
图5:AKI大鼠肾脏组织病理变化
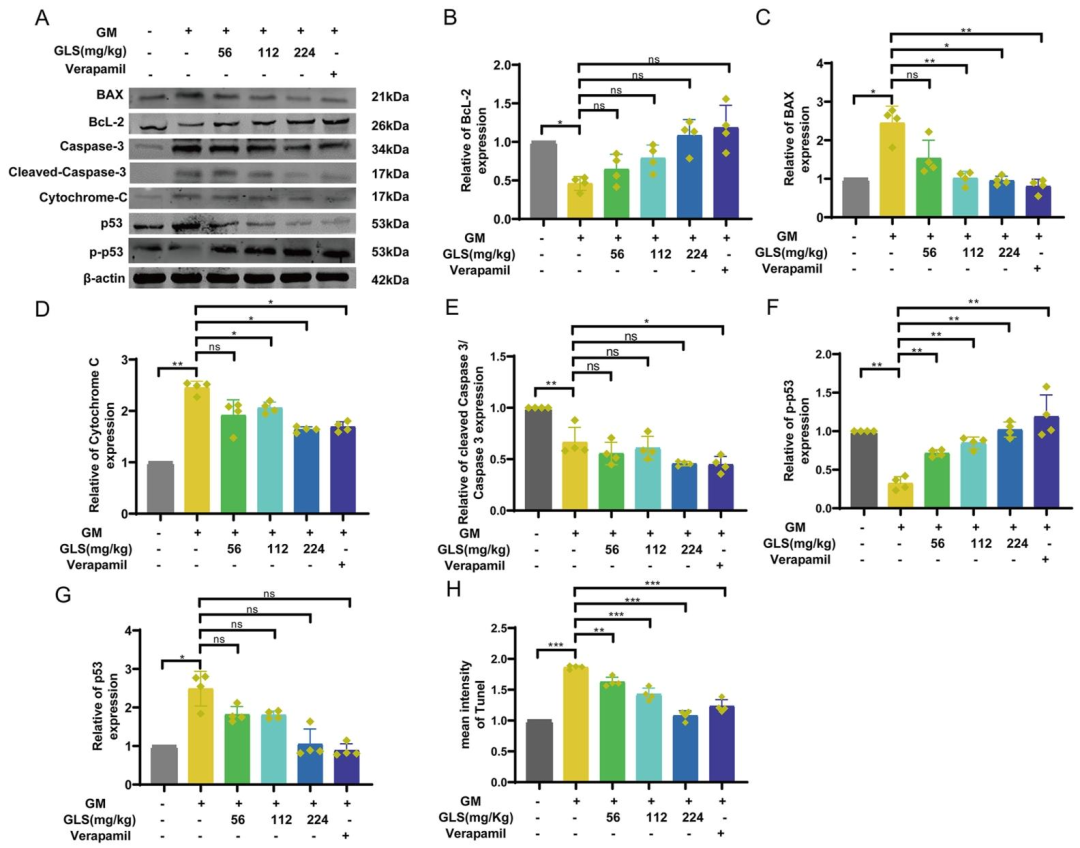
图8:GLS对AKI预测靶点表达的影响
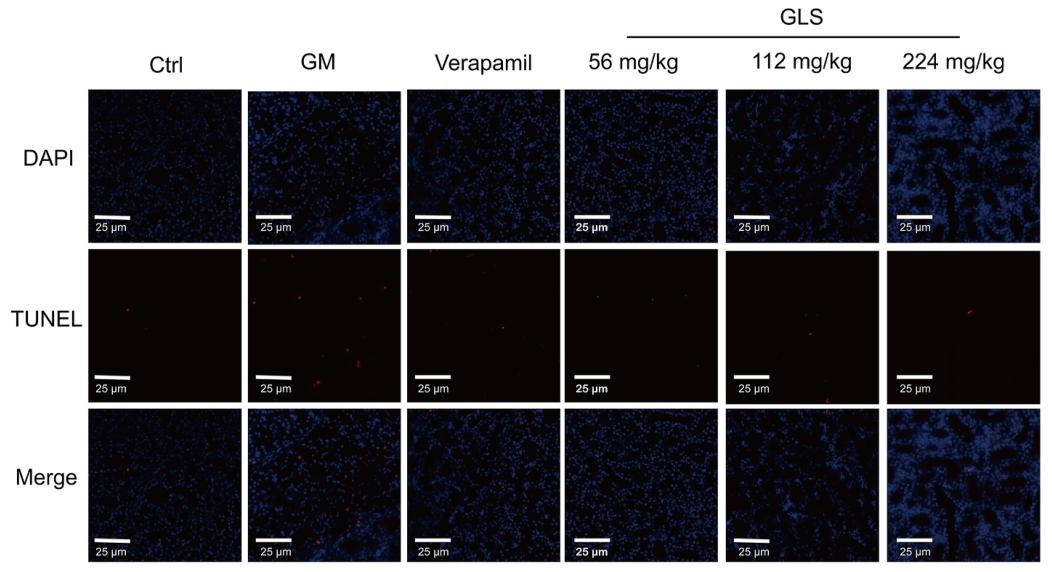
图9:GLS对AKI凋亡特征的影响
5、SERS分析
AKI组肾脏组织在1170 cm⁻¹(芳香环振动)、1221 cm⁻¹(三取代胺C-N伸缩)等峰强度异常,GLS处理后特征峰恢复接近正常(图10),拉曼成像显示凋亡相关分子分布改善。小结:SERS可作为监测肾脏凋亡的光谱学工具,GLS能调节AKI中的细胞代谢紊乱。
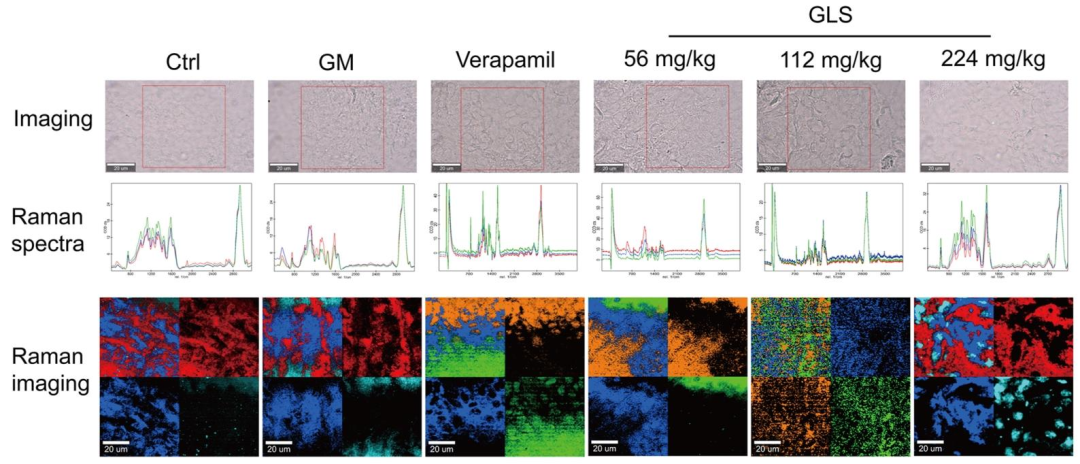
图10:GLS对AKI凋亡状态下SERS检测的影响
研究结论
本研究证实灵芝孢子(GLS)通过抑制p53/Caspase 3信号通路,下调肾脏细胞过度凋亡,从而保护急性肾损伤。网络药理学预测与多维度实验验证(分子对接、组织病理、SERS)共同支持这一机制,为GLS的临床应用及AKI治疗提供了理论依据。
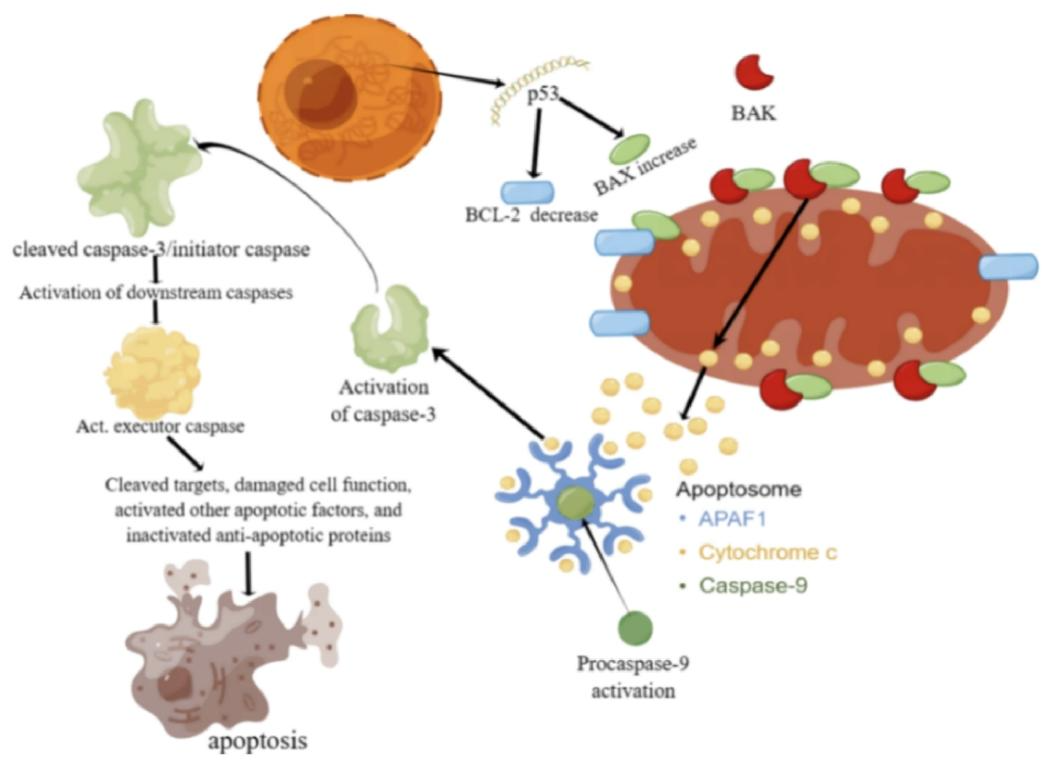
图11:p53介导的凋亡通路机制图
研究的局限性和未来方向
局限性:未深入探究GLS成分与p53的直接结合机制,缺乏单细胞水平的靶点分布分析;
未来方向: 通过冷冻电镜解析GLS活性成分与p53的复合物结构;利用单细胞测序技术分析GLS对肾脏不同细胞类型的调控差异;开展GLS在不同AKI模型(如缺血-再灌注)中的疗效验证。
感谢您的阅读,欢迎关注“生信学术纵览”。谢谢您的分享、点赞+在看!