网上做网站的用excel 做网站
背景
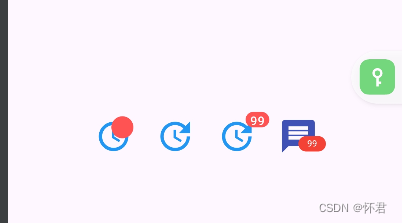
主要常用于组件叠加上圆点提示;
使用场景,消息数量提示,消息红点提示
| 属性 | 作用 |
|---|---|
| backgroundColor | 红点背景色 |
| smallSize | 设置红点大小 |
| isLabelVisible | 是否显示 |
| offset | 设置红点位置 |
| alignment | 设置红点位置 |
| child | 设置底部组件 |
代码块
class BadgePage extends StatelessWidget {const BadgePage({Key? key}) : super(key: key);Widget build(BuildContext context) {return const Wrap(spacing: 20,children: [Badge(backgroundColor: Colors.redAccent,smallSize: 10,child: Icon(Icons.update,size: 36,color: Colors.blue,),),Badge(backgroundColor: Colors.redAccent,smallSize: 10,label: Text('99'),isLabelVisible: false,largeSize: 14,child: Icon(Icons.update,size: 36,color: Colors.blue,),),Badge(backgroundColor: Colors.redAccent,smallSize: 10,label: Text('99'),largeSize: 14,child: Icon(Icons.update,size: 36,color: Colors.blue,),),Badge(backgroundColor: Colors.red,label: const Text('99'),smallSize: 20,textStyle: const TextStyle(fontSize: 8, color: Colors.red),padding: const EdgeInsets.symmetric(horizontal: 8, vertical: 2),largeSize: 14,offset: Offset(-4, -4),alignment: Alignment.bottomRight,child: const Icon(Icons.message, size: 36, color: Colors.indigo),),],);}
}
效果图