安徽省博物馆网站建设什么外贸网站做箱包好
说明:我安装的组件架构如下:
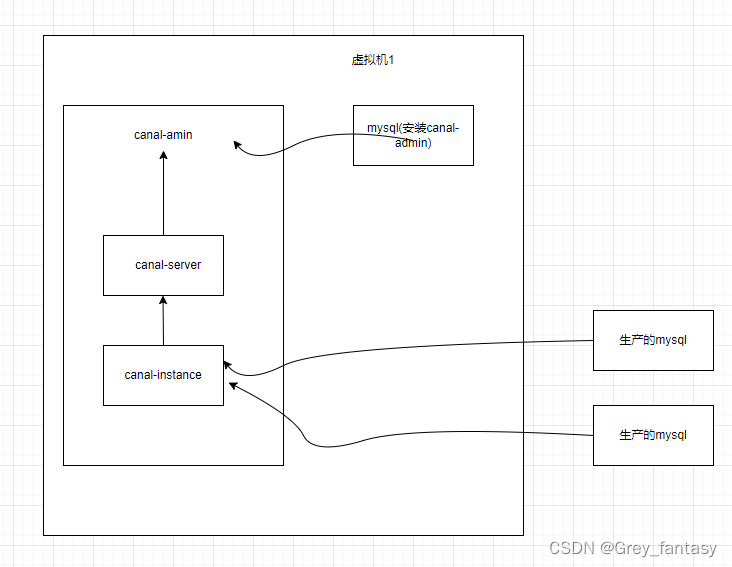
1、准备一台虚拟机,192.168.2.223,我安装的时候,docker只支持canal1.1.6版本,1.1.7无法使用docker安装.还有一点要补充,就是1.1.6好像不支持es8.0以上版本(官网说的是1.7版本才有es8.0以上.)。
2、登录数据库的主机,修改数据库的配置
#修改mysql的配置文件,在[mysqld]下添加以下内容
server_id=1
# 开启binlog
log_bin = mysql-bin
# 选择row模式
binlog_format = ROW
#查看开启命令拓展,这个用于和instance配置的数据库进行使用,安装canal-admin的数据库可以不开启blog,但是同步到数据库需要开启
show variables like 'log_bin';
show variables like 'binlog_format';
show variables like '%server_id%';
3、获取安装包和准备数据
mkdir -p /root/canal
cd /root/canal
#下载文件包
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.admin-1.1.6.tar.gz
mkdir canal-admin
tar -zxvf canal.admin-1.1.6.tar.gz -C canal-admin
#把cat的回显记录下来,拿到自己准备的mysql上去创建需要的数据表。因为容器部署不支持source命令,所以手动记录下来进行执行
cat /root/canal/conf/canal_manager.sql#去到安装mysql的主机,登录mysql
mysql -u 用户名 -p 密码
create database canal_manager;
grant all privileges on canal_manager.* to canal@'%' identified by 'canal'
flush privileges;
exit
mysql -ucanal -pcanal
use canal_manager;
#执行cat的内容
下载的cana .admin-1.1.6.tar.gz安装包太慢的话,1.1.7本部也适用的,因为我后续需要安装1.7版本,所以提供1.7版本,可以通过我百度云进行下载:
链接:https://pan.baidu.com/s/1FDAcyTiFEZEITX0gAXOnmw
提取码:70j9
4、部署安装
#执行安装,账号密码可以自定义
docker run --privileged -p 8089:8089 -v /opt/canal-admin/conf:/root/canal/conf -v /opt/canal-admin/logs:/root/canal/logs --name canal-admin -e spring.datasource.address="数据库的ip:端口/canal_manager?allowMultiQueries=true&useUnicod=true&charac terEncodin=utf-8&serverTimezone=CTT&allowPublicKeyRetrieval=true&useSSL= false" -e spring.datasource.username=canal -e spring.datasource.password=canal -e canal.adminPasswd=123456 -d canal/canal-admin:v1.1.7
#登录canal-admin,ip为安装主机ip,端口为8089,用户为admin,密码为123456
#注:canal_manager.sql 提供的脚本中,canal_user 表提供的默认⽤户名为: canal,密码为:6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9,也就是 SELECT PASSWORD('123456'); 的值
所以登陆 canal-admin 管理平台的⽤户名就是 admin/123456
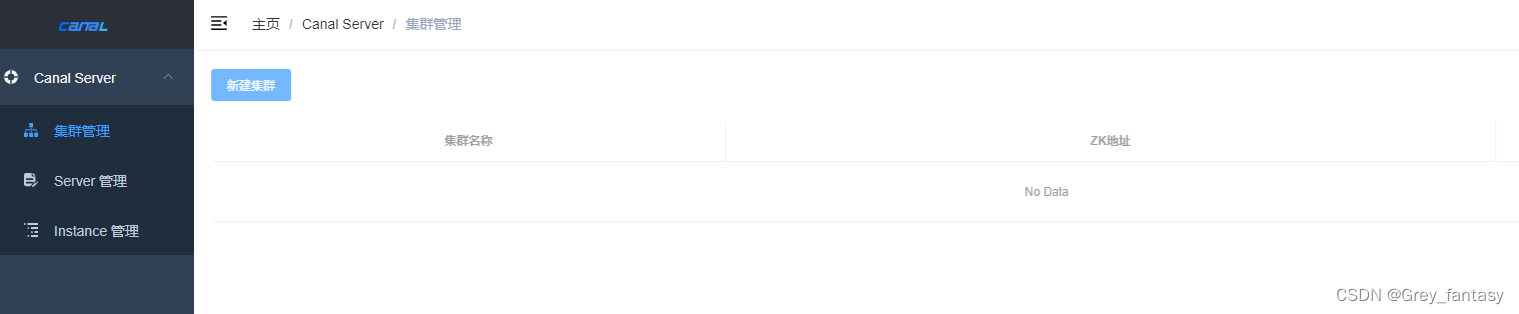
5、安装canal-server
#安装,这些账号密码可以自定义
docker run -p 11111:11111 --name canal-server01 -e canal.admin.register.auto=true -e canal.admin.register.name=canal-server01 -e canal.admin.manager=192.168.2.223:8089 -e canal.admin.port=11110 -e canal.admin.user=admin -e canal.admin.passwd=6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 -d canal/canal-server:v1.1.6
部署完成就可以看到server了,这里的serverip是容器的ip,我们不需要进行修改,修改会导致异常的。当我们需要使用的时候直接填写宿主机ip即可。

在操作配置中可以根据自己服务进行自定义和填写,这里就不说明了。
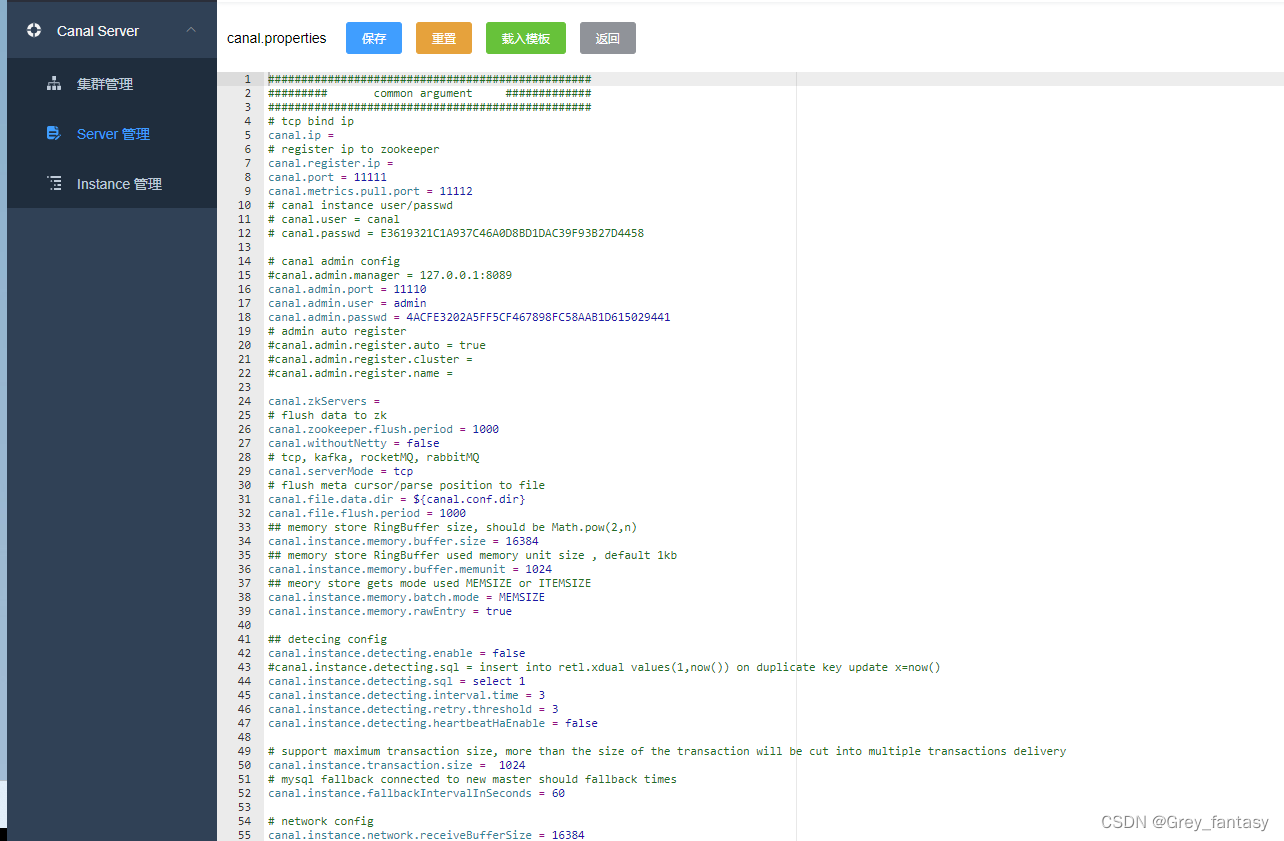
6、创建instance,在Instance 管理里点击新建,输入名称,和选择server
#输入
# mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯⼀ (v1.1.x版本之后c anal会⾃动⽣成,不需要⼿⼯指定)
# canal.instance.mysql.slaveId=0
# mysql主库链接地址
canal.instance.master.address=mysql地址:port端口
# mysql主库链接时起始的binlog⽂件
canal.instance.master.journal.name=
# mysql主库链接时起始的binlog偏移量
canal.instance.master.position=
# mysql主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
# mysql数据库帐号(此处的⽤户名和密码为 安装canal#mysql配置相关#创建canal⽤户 这⼀步 创建的⽤户名和密码)
canal.instance.dbUsername=root
# mysql数据库密码
canal.instance.dbPassword=123456
# mysql 数据解析编码
canal.instance.connectionCharset=UTF-8
# mysql 数据解析关注的表,Perl正则表达式,即我们需要关注那些库和那些表的binlog数据, 也可以在canal client api中⼿动覆盖
canal.instance.filter.regex=.*\\..*
# table black regex
# mysql 数据解析表的⿊名单,表达式规则⻅⽩名单的规则 ,这里我过滤掉了BASE TABLE,不然启动会报错
canal.instance.filter.black.regex=mysql\\.slave_.*,.*BASE TABLE

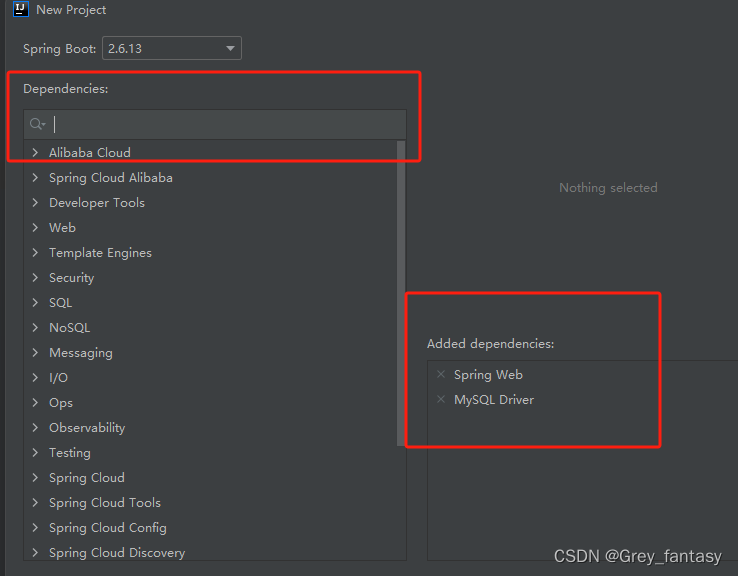
7、新建sringboot项目,idea默认创建的是高版本,我调整了配置如下,然后下一步,下一步进行添加搜索和添加一些必要的依赖。熟悉的也可以通过pom文件自定义添加
https://start.aliyun.com/

8、创建和启动验证,具体业务需要自己去自定义
在pom文件中添加依赖
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.0</version></dependency>
创建测试类SimpleCanalClientExample
package com.example.demo;import java.net.InetSocketAddress;
import java.util.List;import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
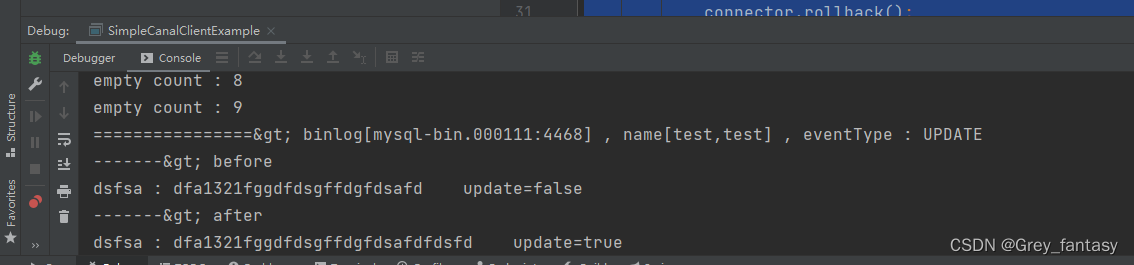
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;public class SimpleCanalClientExample {public static void main(String args[]) {// 创建链接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.2.223",11111), "test", "", "");int batchSize = 1000;int emptyCount = 0;try {connector.connect();connector.subscribe(".*\\..*");connector.rollback();int totalEmptyCount = 120;while (emptyCount < totalEmptyCount) {Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {emptyCount++;System.out.println("empty count : " + emptyCount);try {Thread.sleep(1000);} catch (InterruptedException e) {}} else {emptyCount = 0;// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);printEntry(message.getEntries());}connector.ack(batchId); // 提交确认// connector.rollback(batchId); // 处理失败, 回滚数据}System.out.println("empty too many times, exit");} finally {connector.disconnect();}}private static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}RowChange rowChage = null;try {rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),e);}EventType eventType = rowChage.getEventType();System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));for (RowData rowData : rowChage.getRowDatasList()) {if (eventType == EventType.DELETE) {printColumn(rowData.getBeforeColumnsList());} else if (eventType == EventType.INSERT) {printColumn(rowData.getAfterColumnsList());} else {System.out.println("-------> before");printColumn(rowData.getBeforeColumnsList());System.out.println("-------> after");printColumn(rowData.getAfterColumnsList());}}}}private static void printColumn(List<Column> columns) {for (Column column : columns) {System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());}}}9、随便去instance配置的数据库修改数据,查看控制台输出
10,有问题可以去官网找找处理方法
https://github.com/alibaba/canal/issues