常平做网站wordpress后台轮播图设置
简介
在完成了龙良曲的Pytroch视频课程之后,楼主对于pytroch有了进一步的理解,比如,比之前更加深刻的了解了BP神经网络的反向传播算法,梯度、损失、优化器这些名词更加熟悉。这个博客简要介绍一下在使用Pytorch进行数据可视化的一些内容。
安装
pip install visdom
启动服务
python -m visdom.server
使用
基本上是按照先生成对象,然后追加内容的方式。
import visdomvis = visdom.Visdom()
vis.line([0.], [0.], win='jax train-loss', name="train loss", opts=dict(title='jax train loss'))
vis.line([0.0], [0.], win='jax time-consumed', name="time", opts=dict(title='jax time'))
vis.text(f"jax 进行代理模型训练", win="jax log", opts={"title": "jax log"})# jit_train_step = train_step
start_time = time.time()
s1=start_time
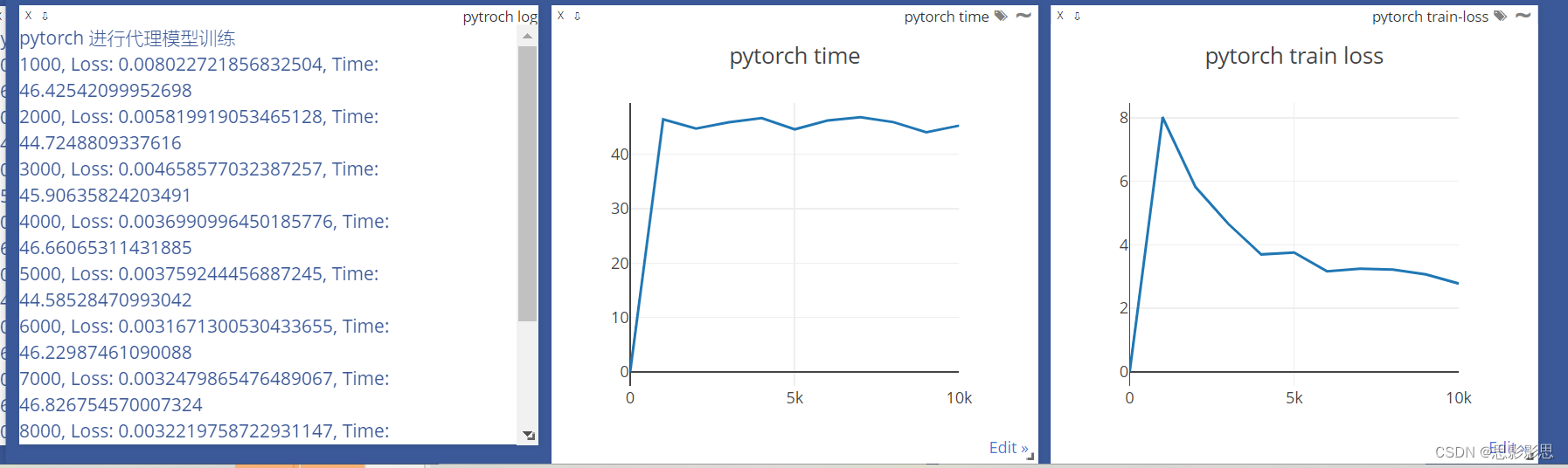
for epoch in range(iterations):vis.text(f"{epoch+1}, Loss: {loss}, Time: {duration}", win="jax log", append=True)vis.line([loss.item()*1000], [epoch+1], win="jax train-loss", update='append', name="train loss", opts={"title": "jax train loss"})
vis.line([duration], [epoch+1], win='jax time-consumed', update='append', name="time", opts={"title": 'jax time'})

下图中,则是同一个图中同时绘制两个曲线
下图演示绘制曲线

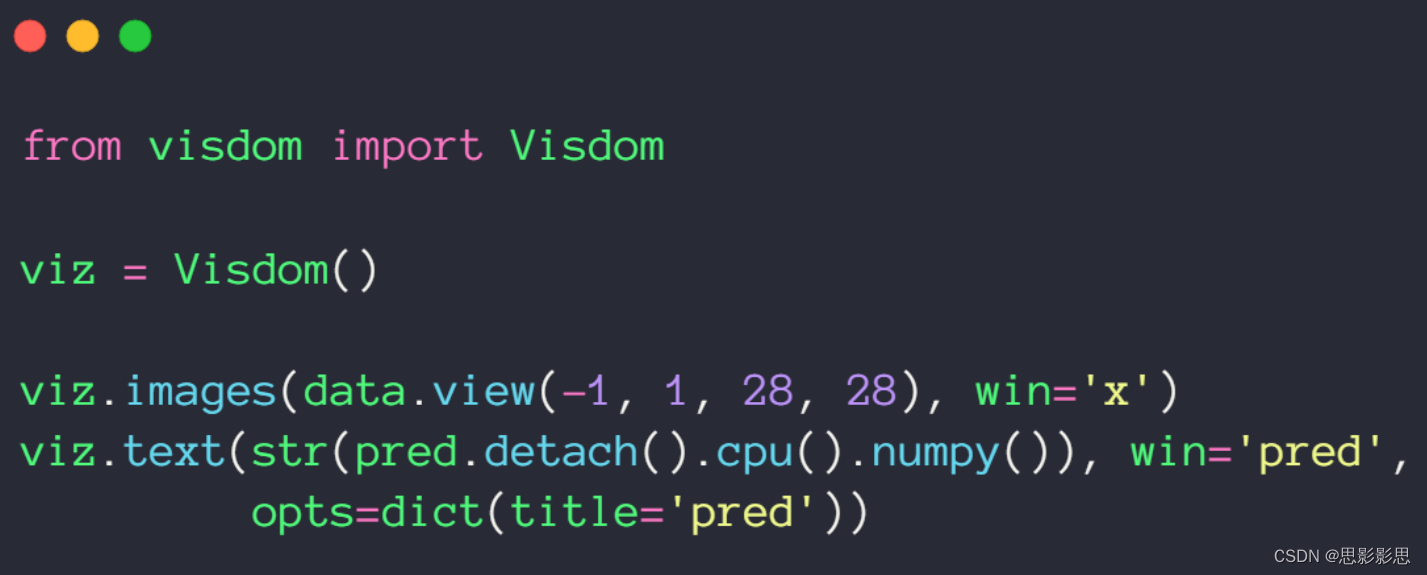
呈现效果