广州建站公司模板wordpress 是否添加封面
普通PDU和智能PDU有什么区别?
机架安装配电盘或机架配电单元 (PDU) 是一种配备许多插座的设备,可将电力分配给位于数据中心机架或机柜内的服务器、存储设备和网络设备。领先的分析公司 IHS 将它们分为两大类:
1) 基本 PDU 提供可靠的配电。
2) 智能 PDU 提供高级功能,如电能计量、环境监控和远程插座控制智能 PDU 可分为以下子类别:
a) 计量入口 PDU——计量入口 PDU 在 PDU 级别计量功率,并在本地和网络上显示数据。计量可帮助用户确定为机架供电的电路的用电量和可用容量,从而更容易配置设备。通过在入口级进行计量,用户可以避免电路过载并轻松计算电源使用效率 (PUE) 等效率指标。
b) 计量出口PDU——与计量入口 PDU 一样,出口计量PDU可帮助用户确定机架的用电量和可用容量,并促进配置。*重要的是使用户能够了解设备或服务器级的实际功耗,从而可以比较效率并将成本分配给特定的业务部门或客户。
c) 开关式 PDU—— 开关 式PDU 具有计量入口 PDU 的功能,还提供对单个插座或插座组的受控开/关切换。它们使授权用户能够按特定顺序远程重启设备,提供电源排序延迟以*大限度地减少浪涌电流,并防止未经授权的设备配置。它们在远程和托管设施部署中至关重要,因为它们允许您通过重启服务器来快速恢复服务。可以远程关闭不使用的设备以节省能源。
d) 带出口计量的开关式PDU——带出口计量的开关式 PDU 将开关式 PDU 的所有功能与出口计量式 PDU 的功能结合在一起。智能 PDU 的每个子类别都具有可帮助数据中心降低运营成本、增加正常运行时间/可用性、改善平均修复时间 (MTTR)、提高能源效率和管理现有容量的功能。
为什么选择合适的 PDU 很重要?
寻找更好的长期价值
由于 IT 购买者正在为较小的预算而苦苦挣扎,较低的价格往往是一个决定性因素。由于基本 PDU 的零售价较低,因此购买它们似乎更划算。其他人可能不相信智能机架 PDU 的高级功能可以提供额外的价值,或者他们的组织没有时间或资源从中受益。因此,许多购买者选择基本型 PDU,尽管从长远来看,智能型 PDU 可以提供更大的价值和成本节约。
要了解为什么智能 PDU 是更好的选择,我们需要首先检查它们可以解决的常见问题。几乎所有数据中心现在都面临的主要挑战
数据中心*重要的一个目标是确保业务连续性。机架 PDU 通过为插入其中的所有设备(服务器、存储和网络设备)提供稳定、可靠和充足的电力来帮助实现这一点。但是,也要考虑数据中心面临的其他一些主要挑战。
• 电源容量管理和配置
• 能源管理
• 环境管理
• 物理和网络安全
• 计算能力需求
• 资产和变更管理
电源容量管理和配置——许多数据中心以混乱和无计划的方式增长。技术人员经常将新设备插入第一个可用的插座,而对可用的电容量知之甚少。这可能会导致保险丝熔断并导致停机。据统计,在2013 年,停机的平均成本就高达到惊人的每分钟 7908 美元。
能源管理——许多数据中心支持比需要更多的基础设施。一份研究报告发现,平均服务器仅以12-18%的容量运行。因此,采用几种*佳实践可以将电力消耗减少多达 40%。
环境管理——虽然 IT 设备占能源成本的 50%,但另有 37% 用于冷却和循环空气。数据中心通常会过冷以防止设备故障,但将恒温器温度每升高华氏度,可节省高达 3% 的当前能源费用。
物理和网络安全——对机柜和过道的安全访问控制的需求正在上升。2011 年,美国*大的上市医疗保健公司之一 Health Net, Inc. 报告称,由于其管理的数据中心的多个服务器驱动器丢失,导致全国多达 190 万人的个人健康记录受到损害。
计算能力需求——尽管数据中心在不断缩小和扩张,但在可预见的未来,一个不变的趋势是对更多计算能力的需求,这种快速扩张将比数据中心过去经历过的电力需求大得多。
资产和变更管理——对于正在扩展的数据中心,手动跟踪资产可能很麻烦且成本很高。一项研究指出,库存收集、库存核对、查找错放资产、手动存储库更新和更换错放资产的过程每年花费 71.4 万美元和大约 706 个工作日。
解决这些挑战需要一种智能方法
简而言之,数据中心面临着挑战。需要解决这些挑战,以控制运营成本并满足新的业务需求。数据中心将需要优化利用电力、空间、冷却和人员。智能 PDU 是可以解决所有这些问题的平台。现在我们将讨论如何为您的数据中心选择合适的机架 PDU,如何为您的机架提供可靠的电力,以及如何为现在和未来创建一个可靠、高效且环保的数据中心。”
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
摘要:数据中心*重要的目标之一是确保业务连续性。数据中心的供电上从高压电源入口到末端配电采用了很多高可靠性的设计,比如多路独立高压市电电源、大容量中压柴油发电机组,UPS的冗余配置等等,这往往意味着高昂的成本,都是为了提高供配电系统容错能力。精密配电柜(也称列头柜)或母线槽承担为数据中心服务器、存储和网络等IT设备提供稳定可靠的电源的末端配电环节,其运行稳定性也尤为重要。在这个环节,几乎所有的数据中心都面临着一些共性的挑战,包括电源容量管理和配置、数据中心能源管理、环境管理、安全管理、计算能力需求扩张、资产和变更管理等等,本文通过数据中心末端配电的数字化解决方案,配合数据中心能效管理系统来探讨如何应对这些挑战。
1 数据中心末端配电面临的挑战
电源容量管理和配置:许多数据中心缺乏有计划的增长扩容,工程师经常将新设备接入看似可用的回路,而对回路可用的负荷容量知之甚少。这可能会导致回路过负荷保险丝熔断并导致停机并导致很大的经济损失,服务中断的损失是以秒来计算的。
能源管理:数据中心*重要的能效指标PUE的计算涉及到所有IT设备的耗能,而IT设备的耗能计量都集中在末端配电,所以在末端需要具备正确的能源计量和管理。
环境管理:虽然IT设备耗能占能源成本的50%以上,但另有36%用于冷却和循环空气。数据中心通常会将机房温度调到过冷以防止设备故障,但将机房温度升高1摄氏度,*多可节省高达7%的冷却耗能成本,所以需要在温度控制和能耗之间找到*佳平衡点。
安全管理:不管供配电前端在可靠性上做了多少冗余,如果忽视了末端的配电安全管理都是无用功,对末端的电源插接点接触以及温升情况也需要重点关注。
计算能力需求:在可预见的未来,一个不变的趋势是对更多计算能力的需求,这种快速扩张将导致数据中对的电力需求越来越大。
资产和变更管理:对于正在扩展的数据中心,手动跟踪资产可能很繁琐且成本很高。研究指出,库存收集、库存核对、查找错放资产、手动存储库更新和更换错放资产的过程每年花费的人力和资金成本巨大。
2 数据中心末端配电的数字化方案
需要解决这些挑战,提高业务连续性、控制运营成本并满足新的业务发展需求,数据中心将需要对末端配电环节有更全面的监测和管理。智能化的精密配电柜和智慧小母线系统可以提供解决方案。接下来将讨论如何为数据中心选择合适的末端配电数字化解决方案,创建可靠、高效且环保的数据中心。
2.1 精密配电柜数字化方案
精密配电柜是为数据中心的IT设备机柜提供电源的末端配电设备,一般采用双回路供电,电源分别来自两台冗余的UPS,分为交流和直流供电,一般放置在机柜阵列的两端,也称列头柜,如图1所示。

图1 ANDPF精密配电柜
安科瑞精密配电监控解决方案针对精密配电柜监控数字化要求,方案包括交流(AC220V)、直流(DC-48V/240V/336V)系统。由触摸式液晶显示屏、综合信息处理主机模块、开关状态采集模块、电流互感器(交流)或霍尔传感器(直流)采集单元模块等组成。监测两路主进线和A+B双面馈线回路电量参数、开关状态、谐波含量、柜内温湿度等数据,可以在本地触摸屏显示,同时可以上传AcrelEMS-IDC数据中心能效管理系统显示和报警。产品方案见表1。
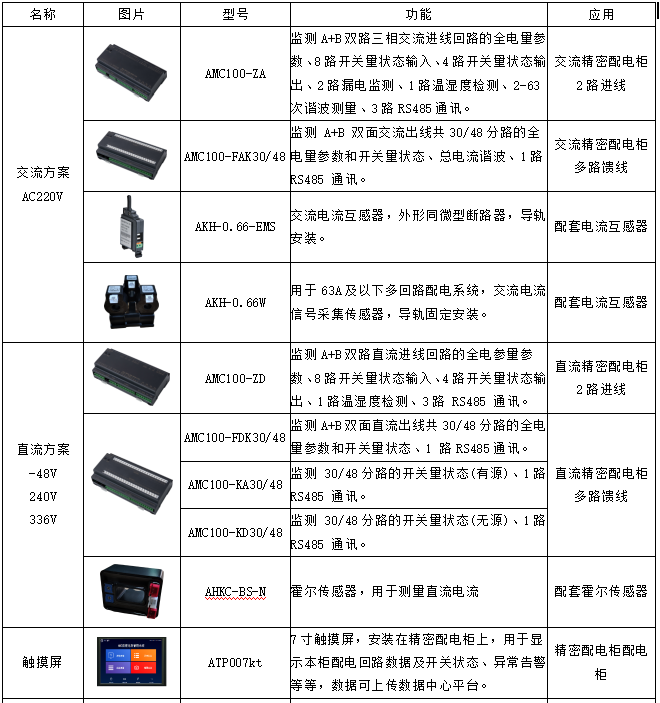

表1 安科瑞精密配电柜数字化方案产品选型
2.2 母线槽数字化方案
近年来,随着数据中心建设的快速发展,智能母线槽的方案运用越来越多。相比传统精密配电柜,数据中心母线槽架空铺设,具有安装检修方便、不占地、散热快、易增容等优势。母线槽通过始端箱从前端UPS取电,以母排系统组成输电结构,采用即插即用的方式,通过插接箱给各个IT机柜内的PDU供电。
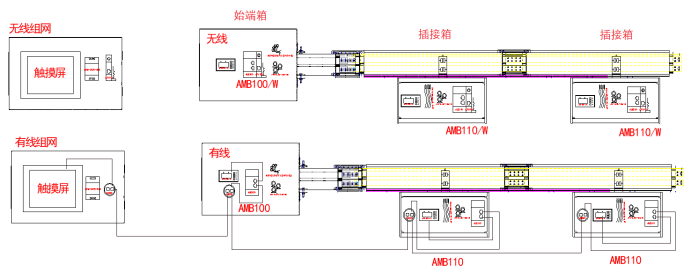
图2 智能母线槽数据采集方案示意图
安科瑞智能母线槽方案在始端箱和插接箱内配置AMB100/AMB110监测单元,测量始端箱、插接箱电压、电流、频率、有功功率、无功功率、功率因数、有功电能、无功电能、谐波畸变、温湿度、漏电电流等数据,可以通过有线或无线方式传输数据,在本地触摸屏显示,同时可以上传数据中心能效管理系统,实现母线槽的数据展示和异常预警。
另外由于母线槽是由铜制母排搭接而成,接头部位可能会由于接触不良而异常发热,所以需要对母线槽接头温度进行实时监测,安科瑞AMB200母线接头温度监测装置进行接触式测温,AMB300通过红外非接触式测温方式监测母线温度,数据通过有线或无线方式传输本地触摸屏显示,同时可以上传数据中心能效管理系统,实现母线槽温度的实时预警,设备选型如表2所示。
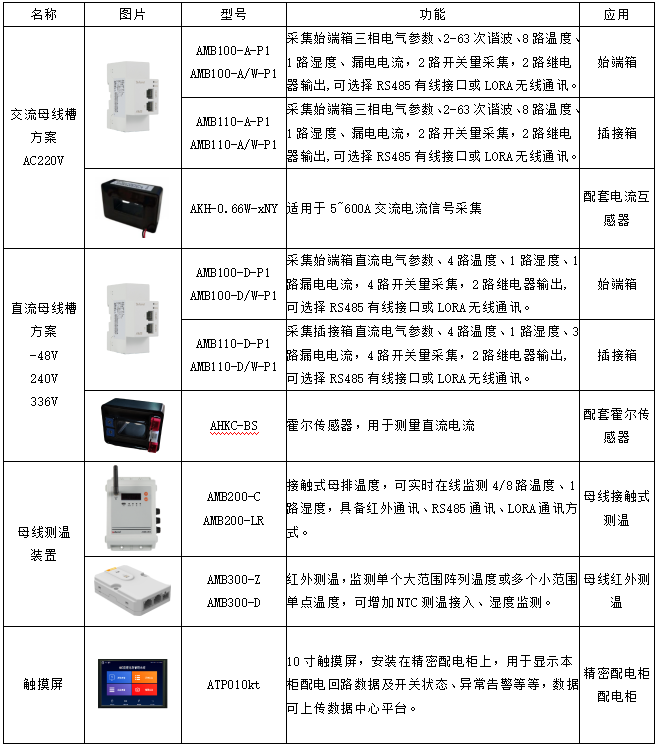
表2 智能母线槽解决方案选型表
3 AcrelEMS-IDC数据中心能效管理系统
AcrelEMS-IDC数据中心能效管理系统搭建基于高、中、低压配电系统、柴油发电机、UPS的实时监控和末端配电系统数据采集的电力监控、PUE分析以及动环监测,帮助数据中心管理者全面了解数据中心能源运行情况,并关注消防和电气安全,及时预警异常情况,保障数据中心稳定可靠运行。除了变电站、柴油发电机和UPS运行监控以外,特别是针对数据中心的末端配电环节,系统数据跟踪到每一个回路的电气参数和开关状态、温湿度数据等。
3.1 电源容量管理和配置
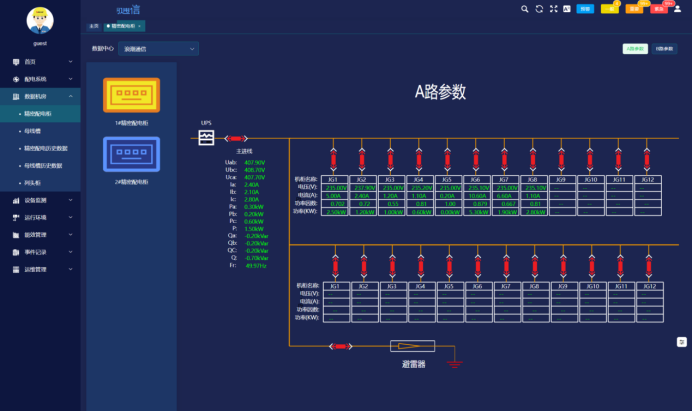
系统监测每路馈线回路的电流、功率、开关状态和用电量,还可以配置温度、湿度传感器用于监测线路接点温度和柜内湿度,设置参数高低越限告警,避免回路超负荷运行而导致意外断电。
3.2 能源管理
数据中心*重要的能效指标PUE的计算涉及到所有IT设备的耗能,系统从高压到末端采集数据中心用电量,并按照IT设备、制冷系统(冷冻水机组、空调末端、新风等)、供电系统(变压器、UPS、发电机、开关)、照明及办公用能进行分类,计算数据中心PUE值、制冷负载系数CLF、供电负载系数PLF等,为数据中心能效诊断提供数据支持。
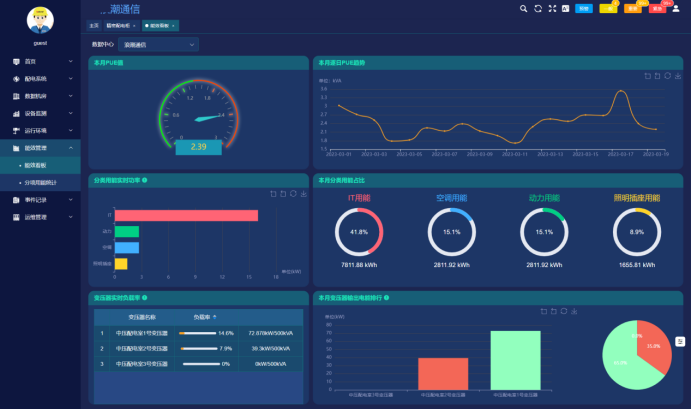
3.3 环境管理
系统根据数据中心不同温度数据下计算数据中心PUE和CLF值的变化,来协助管理者寻找*佳运行温度,在温度控制和能耗之间找到*佳平衡点。同时系统监测数据中心温湿度、浸水、烟雾等影响数据中心正常运行的因素,并及时提供预警。
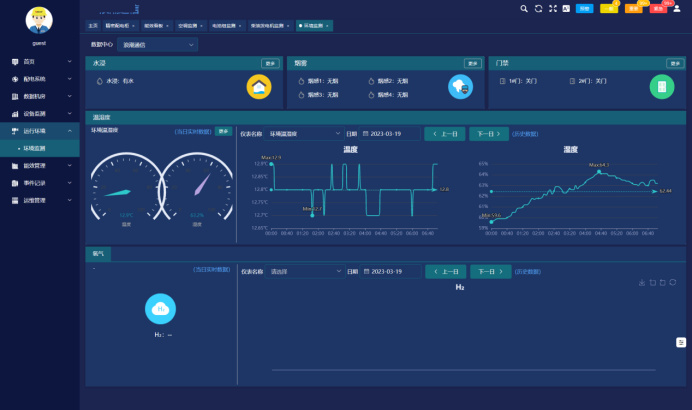
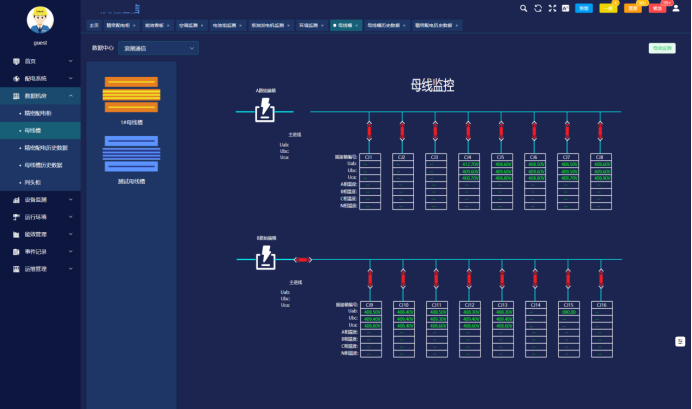
3.4 安全管理
系统监测精密配电柜或母线槽系统电气接点温度以及漏电电流,并设置温度、漏电越限告警,及时消除系统隐患。同时针对数据中心大量的UPS蓄电池内阻、温度、可燃气体含量也进行实时在线监测预警,保障数据中心运行安全。
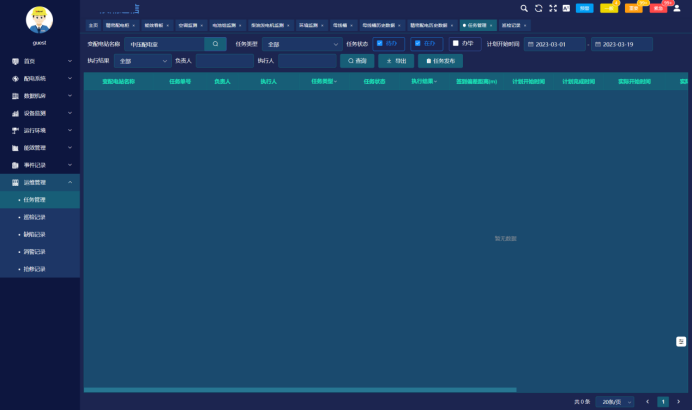
3.5 资产和变更管理
系统为数据中心提供设备管理和运维管理功能,包括设备台账、设备保养、工单管理、巡检记录、缺陷管理、抢修记录等功能,告别依靠手工记账,降低人力和时间成本。
4 结束语
随着对算力的需求增长,数据中心也将加速发展。为了保障数据中心稳定可靠运行,除了在电源和前端变配电系统上下功夫外,数据中心的末端配电系统数字化管理更为重要。安科瑞AcrelEMS-IDC数据中心能效管理系统配合安科瑞精密配电柜系统、智能母线槽系统为数据中心的末端配电提供负荷监测、能效管理、安全预警和设备运维管理,为数据中心连续稳定运行提供全方位保驾护航。