网站重新备案 需要关闭网站么jsp网站开发的参考文献
flac格式怎么转mp3?MP3格式经过压缩,相较于flac文件,显著减小了文件体积。这一特点使得音乐的存储和传输更加便捷,尤其适合移动设备以及存储空间有限的场景。由于MP3文件体积较小,分享音乐变得非常简单,无论是通过电子邮件、社交媒体还是云存储,传输MP3文件都不会占用太多带宽。
虽然现有的转换软件能够快速完成任务,但在批量转换或处理大量文件时,仍需消耗一定的时间和计算资源。尽管MP3文件较小,频繁的转换和存储可能导致质量进一步下降。随着流媒体服务的普及,许多用户希望通过转换格式来适应不同的播放需求。因此,了解如何将flac格式转换为MP3,不仅能让音乐更易分享和播放,还能让用户尽情享受他们喜爱的旋律,无需担心文件大小的限制。

将flac格式转为MP3格式的方法一:使用软件“星优音频助手”
下载地址:https://www.xingyousoft.com/softcenter/XYAudio
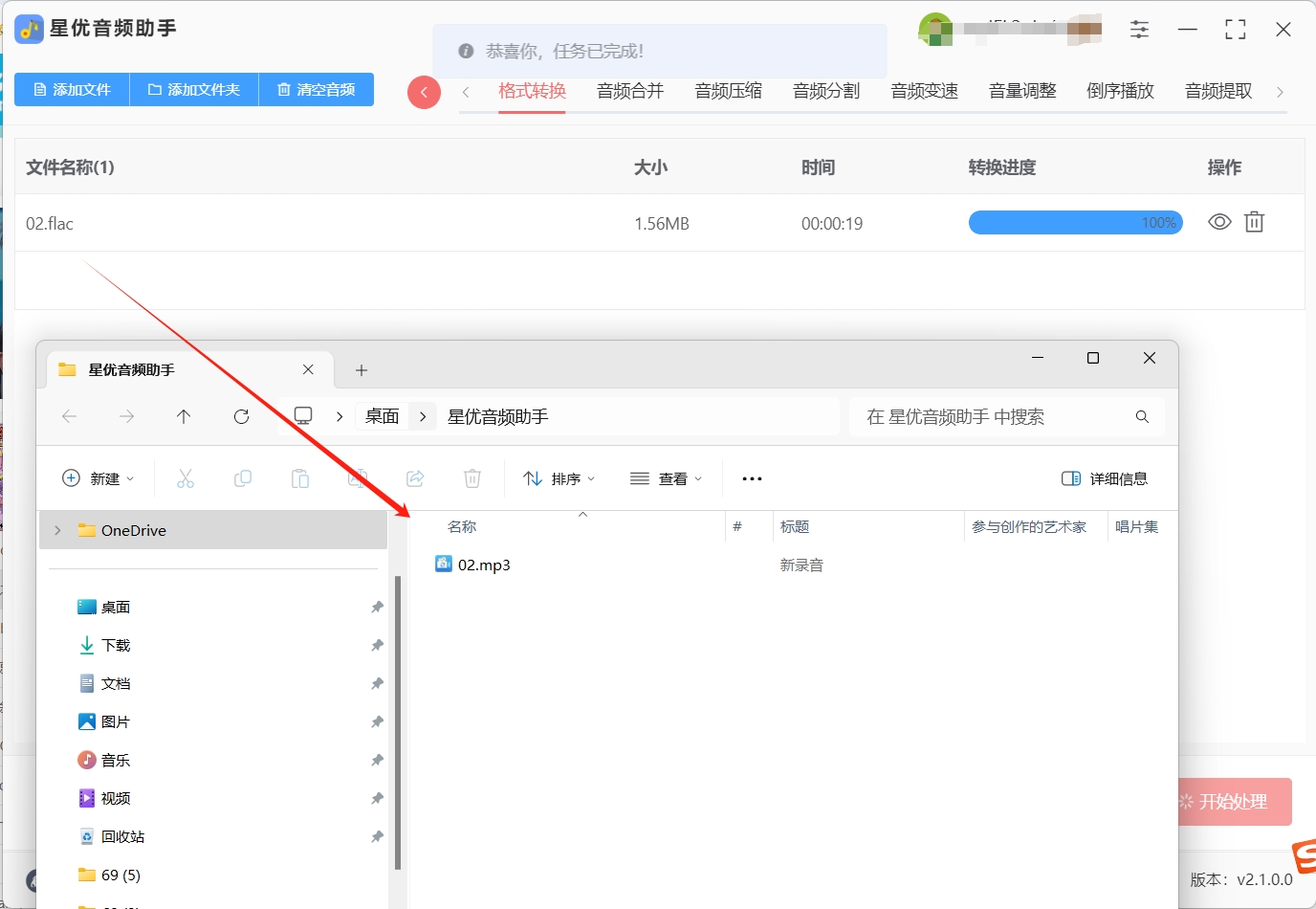
步骤一,首先,你需要在电脑上下载并安装【星优音频助手】。完成安装后,启动软件,你将看到它友好的用户界面。在这里,选择你今天要使用的【格式转换】功能,准备开始转换之旅。
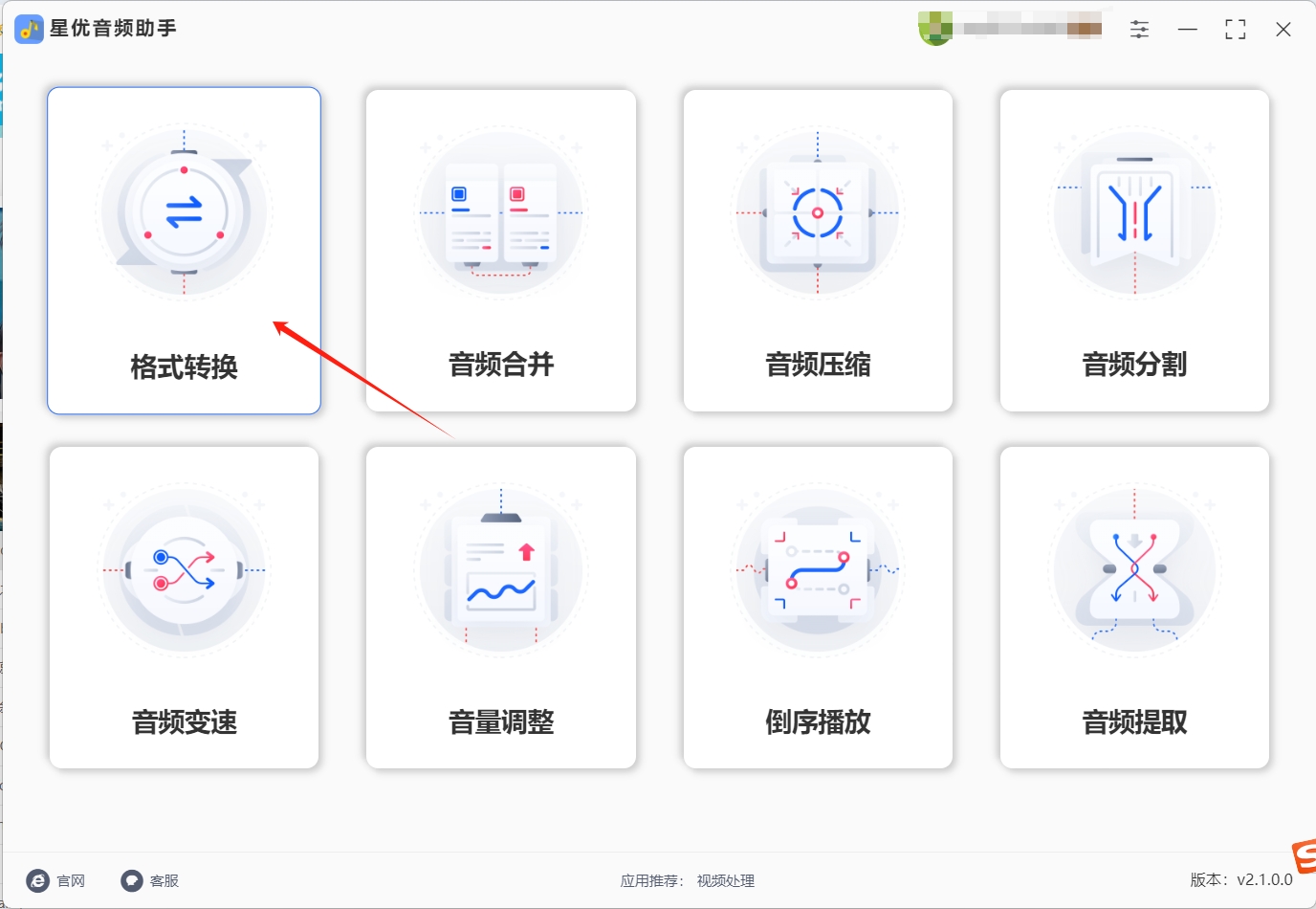
步骤二,接着,找到【添加文件】按钮。点击该按钮,将弹出文件选择窗口,你可以选取需要转换的flac文件。值得一提的是,星优音频助手支持批量上传,你可以一次性选择多个flac文件,实现快速转换,节省宝贵时间。
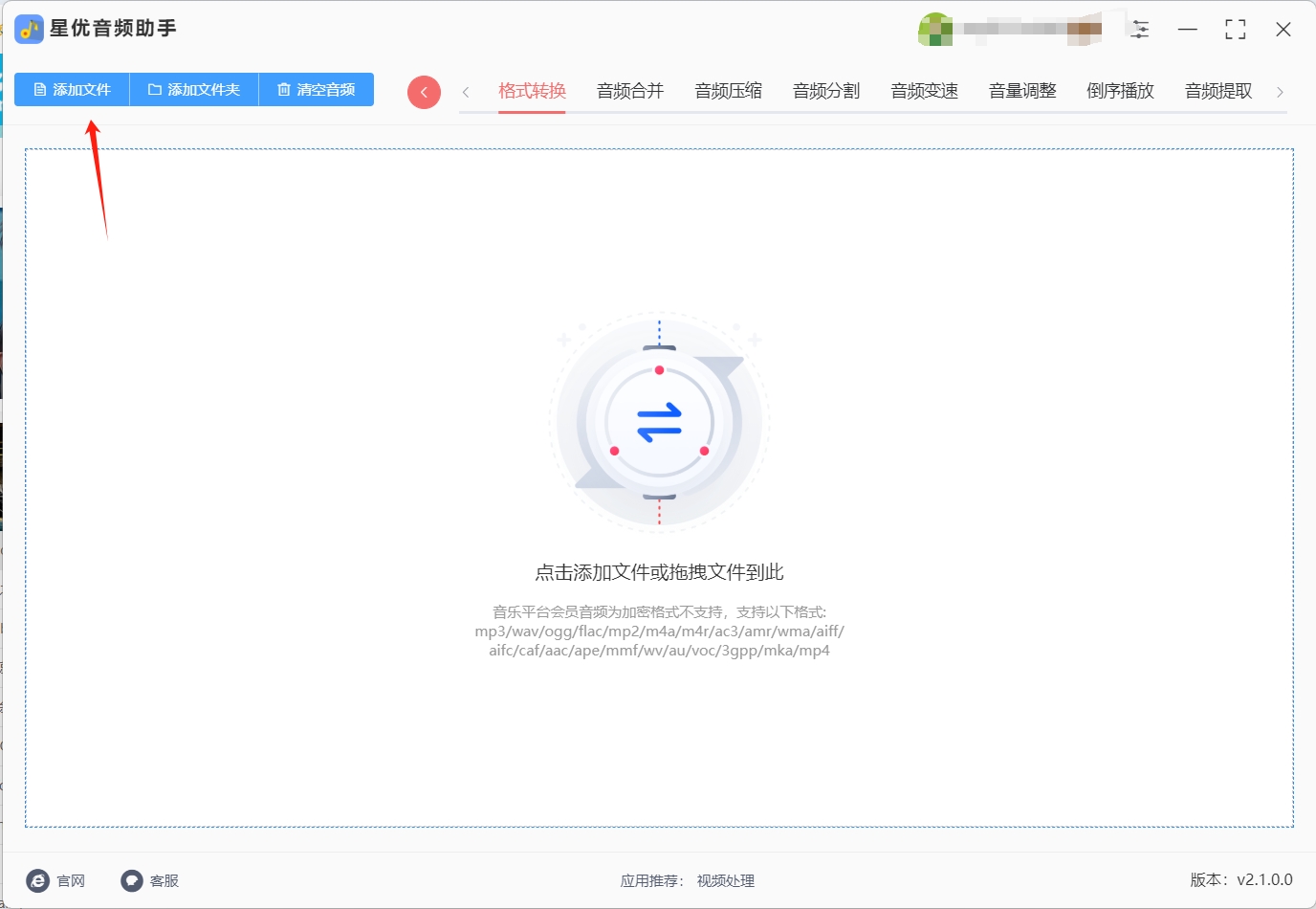
步骤三,文件上传完成后,你需要指定转换后的音频格式。在界面中找到【输出格式】设置选项,点击右侧的下拉菜单,选择“MP3”作为目标格式。这一步至关重要,确保你获得所需的音频类型。
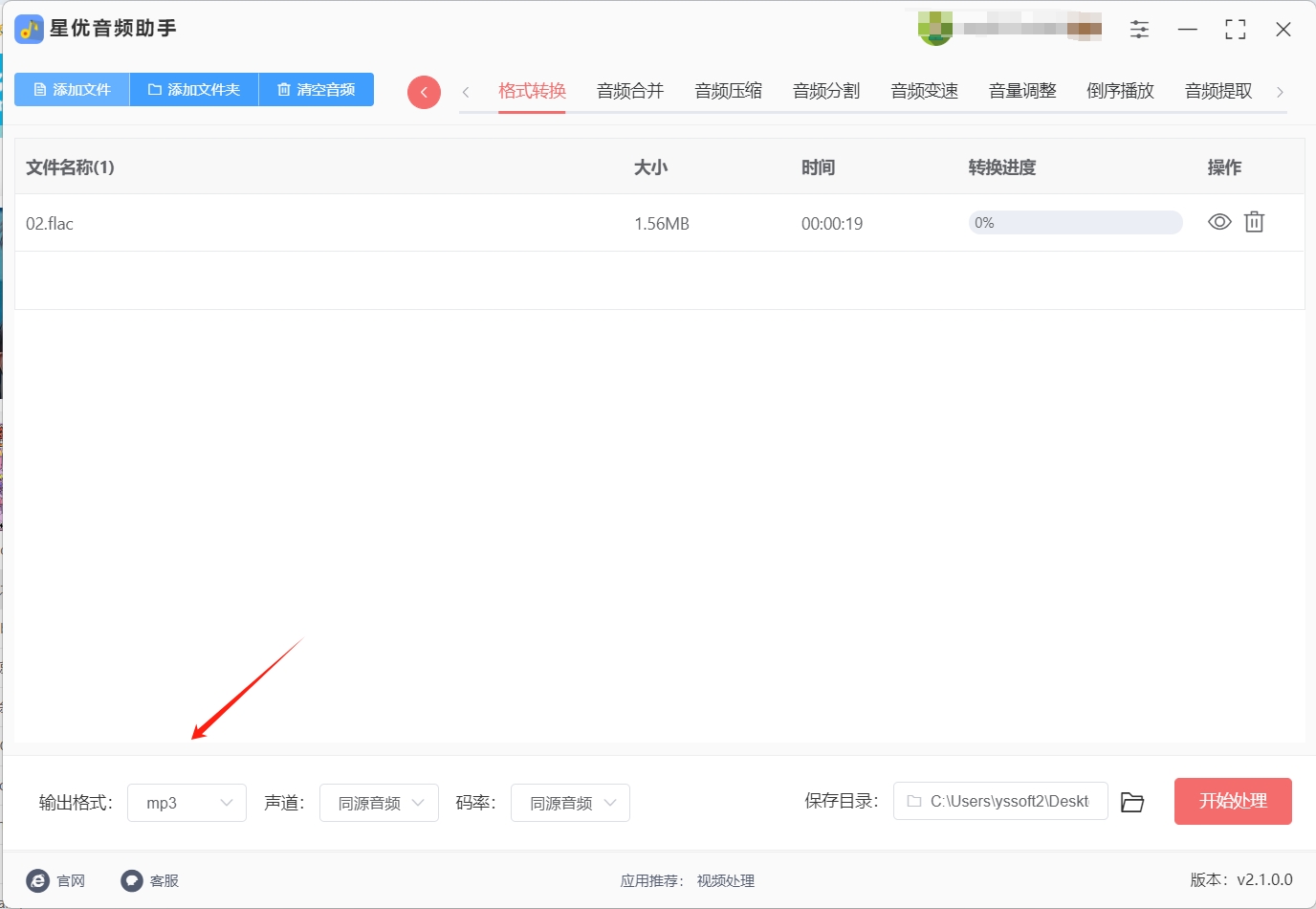
步骤四,设置完毕后,点击【开始处理】按钮,软件将自动启动转换程序。此时,你只需耐心等待,软件会在后台处理音频文件,并在完成后自动打开输出文件夹,让你轻松找到新生成的MP3文件。
步骤五,转换结束后,你可以在输出文件夹中查看已成功转换的MP3文件。为了验证转换效果,不妨将转换前后的音频文件进行对比。
将flac格式转为MP3格式的方法二:使用软件“Audacity”
首先,确保您的电脑上安装了最新版本的Audacity。这款功能强大的音频编辑工具可以从其官方网站免费下载。下载完成后,按照简单的安装指引进行安装。
导入FLAC音频文件
启动Audacity软件,您将看到一个简洁直观的用户界面。要导入FLAC文件,请依次点击屏幕顶部的"文件"菜单,选择"导入",然后点击"音频"。这时,您可以浏览电脑文件夹,选择您想要转换的FLAC文件。选中文件后,点击"打开",文件就会加载到Audacity的工作区中。
检查FLAC文件的显示
在工作区中,您应该能够看到刚刚导入的FLAC文件的波形。这是确认文件已成功导入的关键步骤。
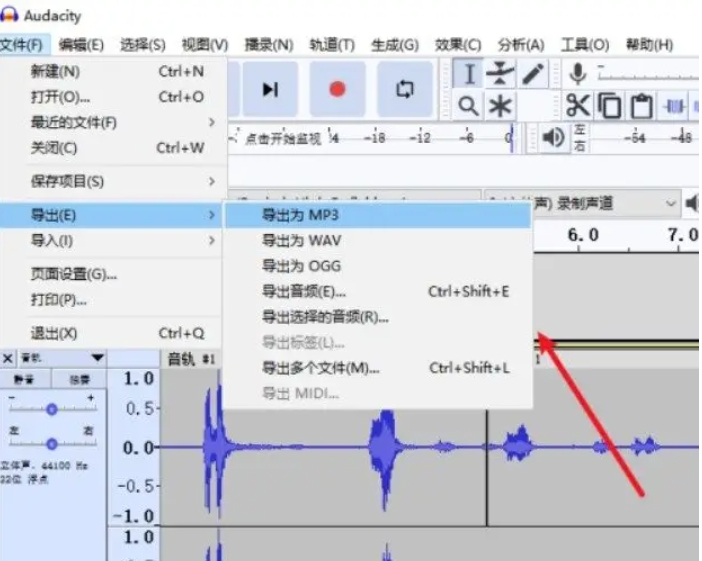
导出FLAC文件为MP3格式
当您准备好开始转换过程时,在工具栏中再次点击"文件"菜单,选择"导出",然后点击"导出为 MP3"。这时,Audacity会检查是否安装了LAME MP3编码器,这是Audacity进行MP3格式转换的必要组件。如果您的系统中尚未安装此编码器,Audacity会提示您进行下载和安装。请按照软件的指示完成安装。
设置MP3参数
安装完LAME MP3编码器后,您可以设置MP3文件的输出参数。在弹出的"导出为MP3"对话框中,您可以自定义比特率、采样率等参数,以满足您对音质的需求。选择合适的设置后,点击"保存"按钮。
开始转换
最后一步是指定MP3文件的保存位置,并为文件命名。完成这些设置后,点击"保存"按钮,Audacity便开始将FLAC文件转换为MP3格式。转换过程可能需要一些时间,具体取决于文件的大小和您的计算机性能。
完成转换
转换完成后,您可以在之前指定的位置找到新的MP3文件。现在,您可以在任何支持MP3格式的设备上播放您的音乐了。
将flac格式转为MP3格式的方法三:使用软件“优速音频处理器”
第一步:获取优速音频处理器
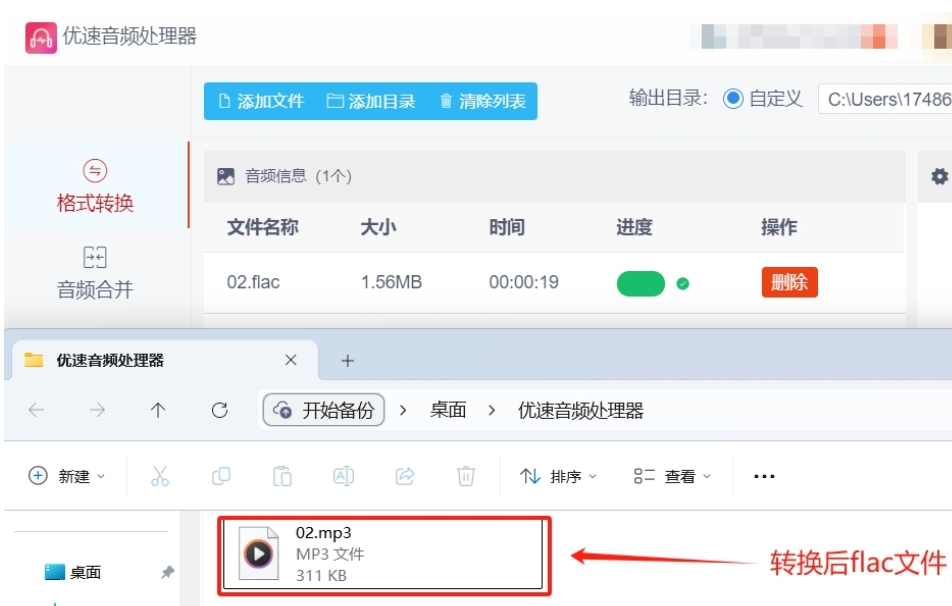
首先,您需要将优速音频处理器软件安装到您的电脑上。这款软件以其高效的音频处理能力而闻名,可以从官方网站下载最新版本。下载完成后,按照简单的安装向导进行安装,只需几个步骤,软件便可以准备就绪。
第二步:启动软件并选择功能
打开优速音频处理器,您将看到一个现代化且用户友好的界面。在界面的左侧,您会看到多个功能选项。请点击【格式转换】功能,这将使您能够将音频文件从一种格式转换为另一种格式。
第三步:导入FLAC文件
要导入您想要转换的FLAC文件,请点击软件左上角的【添加文件】按钮。这将打开一个文件浏览窗口,您可以在其中选择电脑上存储的FLAC文件。选择文件后,点击【打开】将其导入到软件中。或者,您也可以直接将FLAC文件拖拽到软件中间的空白区域,实现快速导入。
第四步:设置转换参数
导入FLAC文件后,您需要设置转换后的音频格式。在软件的右侧,选择输出格式为“MP3”。此时,您可以选择使用软件提供的默认参数,或者根据您的音质需求,手动调整比特率、采样率等其他参数。
第五步:开始转换
当您对设置感到满意后,点击界面右上角的【开始转换】按钮。这将启动音频格式的转换程序。转换过程可能需要一些时间,具体取决于文件的大小和您的计算机性能。
第六步:查找转换后的MP3文件
转换完成后,软件会自动将您带到输出目录,您可以在这里找到转换好的MP3文件。现在,您可以轻松地在任何支持MP3格式的设备上播放这些文件,享受高质量的音乐体验。
通过优速音频处理器,您可以快速、轻松地将FLAC文件转换为MP3格式,无论是为了节省存储空间还是为了提高兼容性,这款软件都是您的理想选择。
将flac格式转为MP3格式的方法四:使用在线转换工具 可云转换器
第一步:访问可云转换器网站
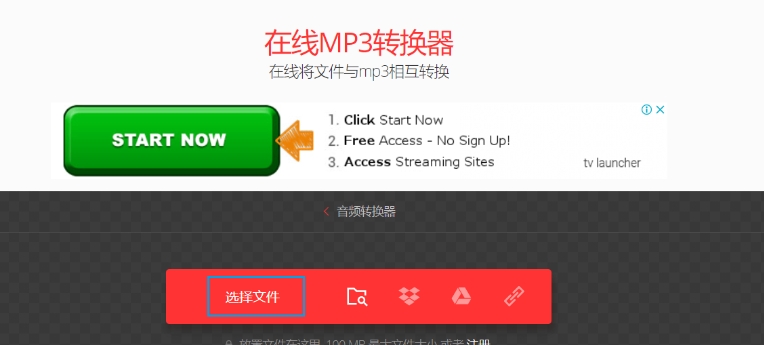
启动您的网络浏览器,直接访问可云转换器网站。可云转换器是一个功能强大的在线文件转换工具,它提供了一个简单易用的界面,让您无需安装任何软件即可完成文件格式转换。
第二步:上传FLAC文件
在可云转换器网站的主页上,您会看到一个“选择文件”按钮。点击此按钮,您可以从电脑中选择想要转换的FLAC文件。此外,可云转换器还支持从谷歌云端硬盘、Dropbox或直接通过URL上传文件。如果您觉得点击按钮太麻烦,也可以直接将文件拖放到页面上的指定区域,实现快速上传。
第三步:选择输出格式
文件上传后,您需要指定转换后的输出格式。在页面上提供的输出格式选项中,选择“MP3”。可云转换器支持多种音频和视频格式的转换,但在这里我们的目标是将FLAC转换为MP3。
第四步:等待转换
选择好输出格式后,可云转换器将自动开始转换过程。转换时间会根据文件的大小和网站的服务器负载而有所不同。请耐心等待,不要关闭浏览器或导航至其他页面,直到转换完成。
第五步:下载MP3文件
一旦转换完成,页面上会出现一个“下载”按钮。点击此按钮,您的浏览器会开始下载转换后的MP3文件。选择一个您希望保存文件的本地文件夹,然后点击“保存”或“确定”。
第六步:享受您的MP3文件
下载完成后,您可以在任何支持MP3格式的播放器或设备上播放这些文件。无论是在您的智能手机、平板电脑还是电脑上,都能享受到高质量的音频体验。
将flac格式转为MP3格式的方法五:使用软件“VLC Media Player”
第一步:启动VLC Media Player
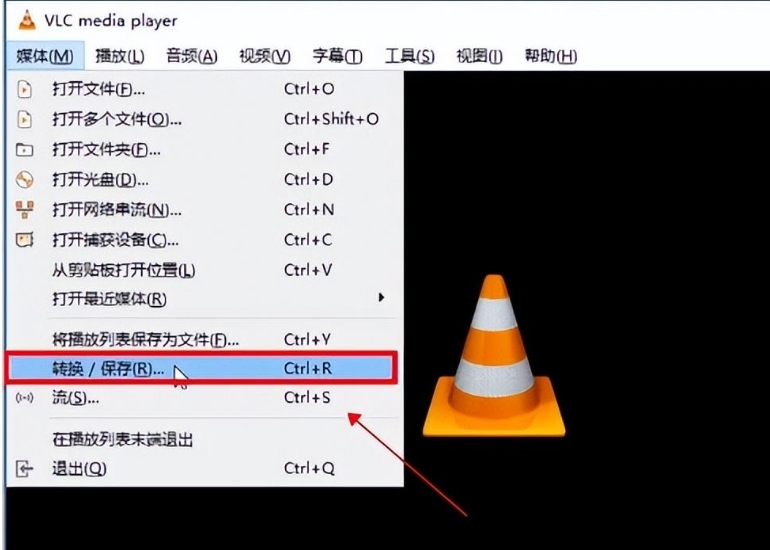
首先,启动您电脑上的VLC Media Player。这款广泛使用的开源多媒体播放器不仅能够播放各种格式的音频和视频文件,还提供了实用的文件转换功能。
第二步:选择转换功能
在VLC的主界面上,点击顶部菜单栏中的“媒体”选项卡。在下拉菜单中,选择“转换/保存”。这个选项会打开一个新的窗口,让您准备文件转换过程。
第三步:添加FLAC文件
在“转换”窗口中,点击“添加”按钮,这将打开一个文件浏览对话框。在您的电脑上找到并选择您想要转换的FLAC文件。选择文件后,点击“打开”将其添加到转换列表中。
第四步:选择MP3作为输出格式
添加FLAC文件后,您需要指定输出格式。在“转换”窗口的“转换到”下拉菜单中,选择“音频 - MP3”选项。这将设置VLC将文件转换为MP3格式。
第五步:调整音频参数
为了获得最佳的音质,您可以调整输出MP3文件的音频参数。点击“音频编解码器”按钮,然后选择“MP3”。在这里,您可以设置音频输出的比特率和采样率。比特率越高,音质越好,但文件大小也越大。采样率决定了音频的频率范围,通常44.1kHz是CD品质的标准。
第六步:设置输出目录
一切设置妥当后,点击“保存”按钮。这将打开一个对话框,让您选择转换后的MP3文件的存储位置。浏览到您希望保存MP3文件的文件夹,或者在对话框中创建一个新的文件夹。
第七步:开始转换
设置好输出目录后,返回到“转换”窗口,点击“开始”按钮。VLC Media Player现在将开始将您的FLAC文件转换为MP3格式。转换过程可能需要一些时间,具体取决于文件的大小和您的计算机性能。
第八步:享受您的MP3文件
转换完成后,您可以在之前指定的文件夹中找到新的MP3文件。现在,您可以将这些文件复制到任何MP3播放器或便携式设备上,随时随地享受您的音乐。
将flac格式转为MP3格式的方法六:使用野兽转换大师
步骤 1:首先,打开浏览器,在地址栏中输入 野兽转换大师 的网址,然后按下回车键进行访问。进入 野兽转换大师 网站后,你会看到简洁明了的界面。此时,你可以通过点击 “选择文件” 按钮或者直接将 FLAC 文件拖拽到指定区域来选择要转换的 FLAC 文件。无论是从电脑本地存储中选取,还是从其他外部存储设备导入,都十分方便快捷。

步骤 2:在成功选择了要转换的 FLAC 文件后,接下来需要在众多的输出格式选项中进行筛选。仔细查找并精准地选择 “MP3” 这一输出格式。这一步骤至关重要,因为它决定了最终转换后的文件格式。确保选择正确后,为后续的转换工作奠定了基础。
步骤 3:当输出格式确定为 MP3 后,此时,你可以看到页面上一个醒目的 “立即转换” 按钮。毫不犹豫地点击这个按钮,系统便会立即开始进行文件的转换工作。在转换过程中,请耐心等待,转换的时间长短会受到文件大小、网络状况等多种因素的影响。一旦转换完成,页面上会出现相应的提示信息。这时,你只需点击下载链接或者按钮,就可以将转换后的 MP3 文件保存到本地电脑的指定位置,方便你随时进行播放和使用。
将flac格式转为MP3格式的方法七:使用软件“酷狗播放器”
一、打开酷狗播放器并找到应用工具
首先,打开酷狗播放器。在播放器界面上方,可以看到三条横杆,点击这三条横杆会出现下拉菜单。在下拉菜单中,仔细查找 “应用工具” 选项。如果你的酷狗播放器有格式转换功能,那么此时应点击 “应用工具” 进入下一步操作。
二、选择保存位置
进入应用工具界面后,找到格式转换工具并点击进入。接下来,需要选择一个保存位置来存放转换后的文件。为了便于管理,你可以新建一个文件夹专门用于保存转换的文件。选择好保存位置后,继续下一步操作。
三、添加 FLAC 格式歌曲
在格式转换工具界面,找到添加文件的选项,将需要转换的 FLAC 格式的歌曲添加进来。确保添加的歌曲是你想要转换的目标文件,以免出现错误。
四、开始转换并查找转换后的文件
当歌曲添加完成且确认无误后,点击下方的 “转换文件” 按钮,酷狗播放器便开始进行格式转换。转换过程可能需要一些时间,具体取决于文件大小和电脑性能。转换完成后,在你之前指定的保存位置,即新建的文件夹中,就可以找到转换好的 MP3 文件了。
将flac格式转为MP3格式的方法八:使用软件“AnyRec Video Converter”
步骤 1:开启软件并添加文件
首先,打开 AnyRec Video Converter 这款软件。在软件界面中,可以清晰地看到 “添加文件” 按钮。轻轻点击这个按钮后,系统会弹出一个文件选择窗口。在众多文件中,仔细挑选你要转换的 FLAC 文件,选中后点击 “确定”,此时该 FLAC 文件便成功添加到软件中,等待着进行下一步的格式转换操作。
步骤 2:选择目标格式
完成文件添加后,找到并点击 “格式” 按钮。点击之后,会出现一个格式选择列表。在这个列表中,认真查找并选择 “MP3” 格式。这一步骤非常关键,它决定了最终转换后的文件格式,确保你准确地选择了 MP3 格式,为后续的转换过程奠定正确的基础。
步骤 3:启动转换过程
当格式选择完毕后,一切准备就绪。此时,点击 “全部转换” 按钮,软件便会立即开始转换过程。这个过程可能会花费一些时间,具体取决于文件的大小以及你的电脑性能。在转换过程中,你可以耐心等待,或者进行其他不影响转换的操作。一旦转换完成,你就可以在指定的输出位置找到转换好的 MP3 文件,享受高质量的音频体验。
在选择软件时,请确保其具备良好的用户评价和稳定性,以避免转换过程中出现问题。尽管MP3格式通常比flac占用更少的存储空间,但音质可能会受到影响。因此,转换后建议你仔细聆听,以确认音质符合你的期望。在进行转换之前,最好先备份原始的flac文件,以防意外。如果转换后的MP3文件出现问题,你仍能访问原始文件。设置MP3格式时,你可以选择不同的比特率。较高的比特率能够提供更优的音质,但文件大小也会相应增加。根据你的需求,选择合适的比特率,以在音质与存储空间之间找到最佳平衡。这种转换不仅能节省存储空间,还能方便你在各种设备上播放音乐。通过这些步骤和建议,你可以轻松将flac文件转换为MP3格式,享受便捷的音乐体验。快来尝试,开启你的新音乐之旅吧!