珠海营销营网站建设网站建设大师
在AIGC技术工具快速发展的时代,对高效智能编程工具的需求和关注已达到空前的高度。本文将介绍9款免费且好用的AI编程助手工具。无论你是经验丰富的开发人员还是刚开始编程旅程的新手,这些AI代码软件都能帮助你提高项目开发的生产力、创造力和准确性,从而进行快速高效的编程开发。
GitHub Copilot
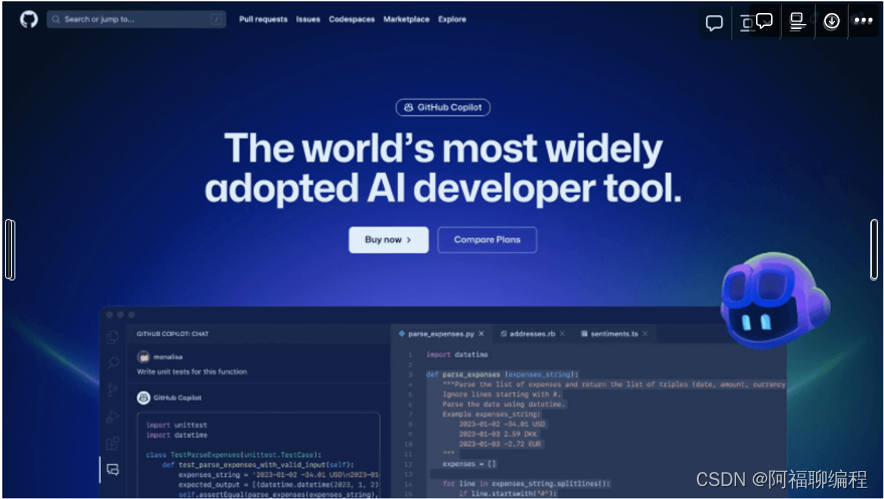
GitHub CopilotGitHub Copilot是由全球最大的程序员社区和代码托管平台 GitHub,以及 OpenAI 和微软 Azure 团队联合推出的 AI 编程助手。该工具是基于 OpenAI Codex 大模型进行改进和升级,已被数百万开发者和2万多个企业组织所使用。GitHub Copilot 支持多种语言和IDE,能为程序员快速提供代码建议,帮助开发者更快、更有效地编写代码。
⌨️ 支持的编程语言
GitHub Copilot 支持 C、C++、C#、Go、Java、JavaScript、PHP、Python、Ruby、Scala 和 TypeScript。
🛠️ 兼容的编辑器和IDE
GitHub Copilot 支持和兼容 Visual Studio、NeoVim、VS Code、Azure Data Studio 和 JetBrains 旗下的系列 IDEs 和代码编辑器。
🤑 产品价格
对于经过验证的学生、教师或流行开源项目的维护人员,GitHub Copilot 可免费使用。普通用户的话,GitHub Copilot 提供免费 30 天的试用,免费试用结束后,需要付费订阅。对于个人来说,GitHub Copilot 每月10美元(年付的话一年100美元)。若订阅商业版,每个用户每月19美元。
通义灵码
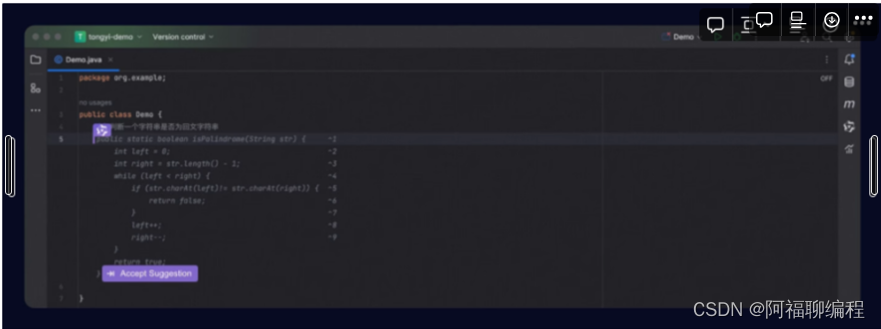
通义灵码是阿里巴巴团队推出的一款基于通义大模型的智能编程辅助工具,提供行级/函数级实时续写、自然语言生成代码、单元测试生成、代码注释生成、代码解释、研发智能问答、异常报错排查等能力,并针对阿里云 SDK/API 的使用场景调优,为开发者带来高效、流畅的编码体验。
⌨️ 支持的编程语言
通义灵码支持 Java、Python、Go、C/C++、JavaScript、TypeScript、PHP、Ruby、Rust、Scala 等主流编程语言。
🛠️ 兼容的编辑器和IDE
通义灵码兼容 Visual Studio Code、JetBrains IDEs 等主流编辑器和 IDE。
🤑 产品价格
通义灵码目前是完全免费的,用户只需前往IDE下载对应的插件即可。
CodeWhisperer
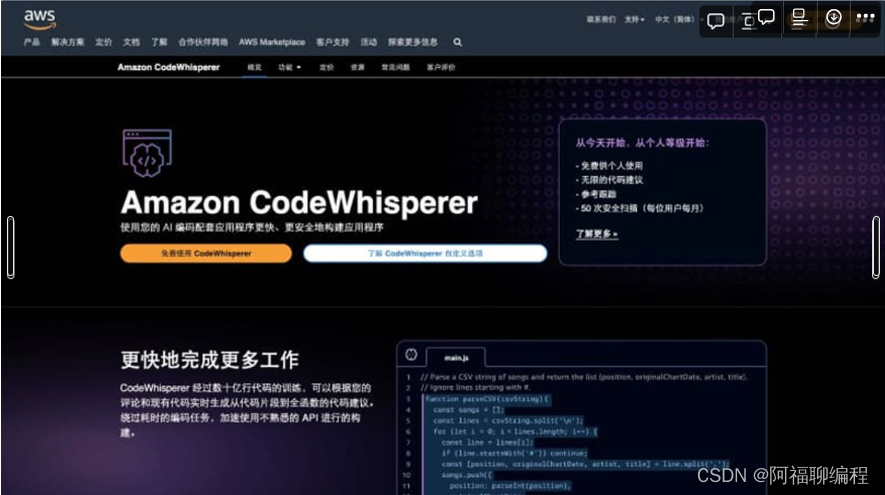
CodeWhisperer是亚马逊 AWS 团队推出的 AI 编程软件,该代码生成器由机器学习技术驱动,可为开发人员实时提供代码建议。当用户编写代码时,CodeWhisperer 会根据现有的代码和注释自动生成建议,可供个人免费使用,生成无限次数的代码建议。
⌨️ 支持的编程语言
CodeWhisperer 支持 15 种编程语言,包括 Java、Python、JavaScript、TypeScript、C#、Go、PHP、Rust、Kotlin、SQL、Ruby、C++、C、Shell、Scala。
🛠️ 兼容的编辑器和IDE
CodeWhisperer 支持的代码编辑器或IDE包括Amazon Sagemaker Studio、JupyterLab、Visual Studio Code、JetBrains 旗下的IDEs、AWS Cloud9、AWS Lambda、AWS Glue Studio。
🤑 产品价格
对于个人开发人员可以免费使用 CodeWhisperer,支持不限次数地生成代码建议并免费使用引用跟踪器,且每月可免费进行 50 次代码扫描。对于企业组织来说,专业版本的价格是每人每月19美元,提供500次代码安全扫描。
CodeGeeX
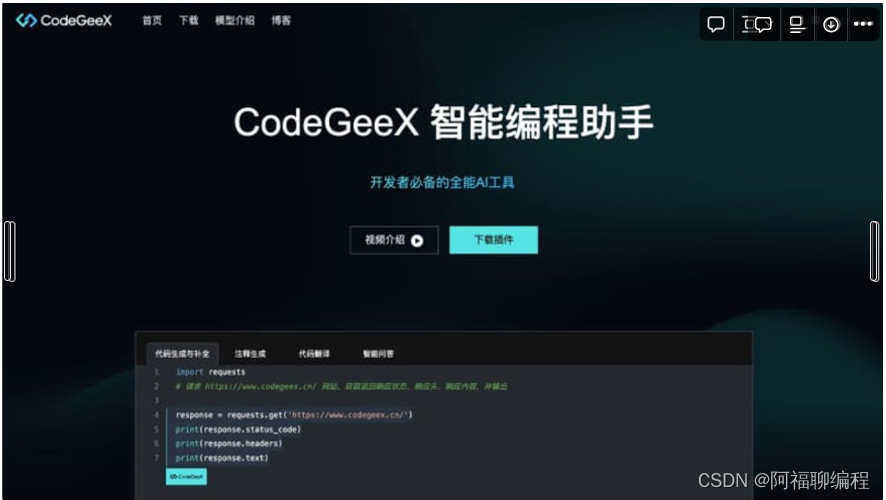
CodeGeeX是智谱AI推出的开源的免费AI编程助手,该工具基于130亿参数的预训练大模型,可以快速生成代码,帮助开发者提升开发效率。CodeGeeX 支持多种IDE与编程语言,提供代码自动生成和补全、代码翻译、自动添加注释、智能问答等AI功能。
⌨️ 支持的编程语言
CodeGeeX 支持Python、Java、C++、C、C#、JavaScript、Go、PHP、TypeScript 等多种编程语言。
🛠️ 兼容的编辑器和IDE
CodeGeeX 支持的代码编辑器和IDE包括 Visual Studio Code、IntelliJ IDEA、PyCharm、WebStorm、HBuilderX、GoLand、Android Studio、PhpStorm。
🤑 产品价格
CodeGeeX 插件对个人用户完全免费,并且其代码模型已开源。
Cody
Cody是代码搜索平台Sourcegraph推出的一款AI代码编写助手,该工具借助Sourcegraph强大的代码语义索引和分析能力,可以了解开发者的整个代码库,不止是代码片段。Cody人工智能编程助手可以回答开发者的技术问题并直接在IDE中编写和补全代码,还可以使用代码图来保持上下文和准确性。
⌨️ 支持的编程语言
Cody 基于广泛的训练数据,理论上支持所有的编程语言,对于Python、Go、JavaScript 和 TypeScript的表现更好。
🛠️ 兼容的编辑器和IDE
Cody 目前支持 VS Code、Neovim 和 JetBrains 旗下的 IDE,并即将推出 Emacs 版。
🤑 产品价格
Cody 对于个人用户来说是永久免费的,若要使用企业版则需要联系他们的产品专家。
CodeFuse
CodeFuse是蚂蚁集团支付宝团队为国内开发者提供智能研发服务的免费AI代码助手,该产品是基于蚂蚁集团自研的基础大模型进行微调的代码大模型。CodeFuse 具备代码补全、添加注释、解释代码、生成单测,以及代码优化功能,以帮助开发者更快、更轻松地编写代码。
⌨️ 支持的编程语言
CodeFuse 支持 40 多种编程语言,包括 C++、Java、Python、JavaScript 等。
🛠️ 兼容的编辑器和IDE
支持在支付宝小程序云云端研发、Visual Studio Code,以及 JetBrains 旗下的8款IDE中使用。
🤑 产品价格
CodeFuse目前是完全免费的,用户只需申请体验,然后下载插件使用即可。
Codeium
Codeium是一个由 AI 驱动的编程助手工具,旨在通过提供代码建议、重构提示和代码解释来帮助软件开发人员,以提高编程效率和准确性。Codeium 与主流的开发环境集成,并支持多种编程语言,可以理解代码上下文,自动进行代码补全、错误检测,甚至生成样板代码,可以高效加快开发过程,并减少代码错误的可能性。
⌨️ 支持的编程语言
Codeium 支持70多种编程语言:如 C、C++、C#、 Java、JavaScript、Python、PHP等主流编程语言。
🛠️ 兼容的编辑器和IDE
Codeium 兼容40多个编辑器:支持 VSCode、JetBrains IDEs、Visual Studio、Eclipse等常用编辑器和集成开发环境。
🤑 产品价格
Codeium 的个人版是完全免费的,团队版每个用户每月12美元
CodiumAI
CodiumAI是一款AI代码测试和分析工具,可以智能分析开发者编写代码、文档字符串和注释,并且可以与人聊天互动,在编程时生成测试建议和提示。该工具智能创建全面的测试套件,包括自动生成单元测试、智能分析代码、代码修改建议、查找代码错误、自动添加文档字符串等,以便在软件发布前发现Bug或错误,确保软件的可靠性和准确性。
⌨️ 支持的编程语言
CodiumAI 支持几乎所有编程语言,不过,某些高级功能(例如单元测试运行和修复)仅支持 Python、JavaScript、TypeScript 和 Java。
🛠️ 兼容的编辑器和IDE
CodiumAI 目前支持 VS Code 和 JetBrains 旗下的 IntelliJ、WebStore、CLion、PyCharm 等IDE。
🤑 产品价格
CodiumAI 针对个人开发者是完全免费的,团队版每个用户每月19美元。
AskCodi
AskCodi是一个基于 OpenAI GPT 大模型技术的 AI 自动编程工具,可以帮助开发人员更快、更省力地编写代码。该AI编程工具提供了代码生成、单元测试创建、文档编写、代码转换等功能,并与主流的IDE扩展/插件无缝集成,帮助开发者提高生产力,减少手动编码的过程,专注于逻辑和更高层次的创造力上。
⌨️ 支持的编程语言
AskCodi 支持流行的编程语言和框架,包括如HTML、Python、JavaScript、Java、C++、React、Vue框架等。
🛠️ 兼容的编辑器和IDE
AskCodi 目前支持通过 Visual Studio Code、Sublime Text 和 JetBrains 旗下系列 IDEs 的扩展或插件使用。
🤑 产品价格
- Basic 免费版,每月提供50个积分,访问基本模型和AI聊天机器人(1积分约等于3000 token)
- Premium 高级版,每月9.99美元,每月提供500个积分,访问基本模型、GPT-3.5-Turbo、自动补全
- Ultimate 旗舰版,每月29.99美元,每月3000积分,访问基本模型、GPT-3.5-Turbo和GPT-4和所有功能