猫扑网站开发的网络游戏外贸网站推广企业

TikTok在商品售卖资质和商家资质上做了很多限制,比如我们熟知的珠宝类目,今天我们结合TikTok Shop规则中心8月30号发布的《如何申请成为“定邀”卖家》和关于“定邀”商品的政策进行分析,看看如何成为“定邀”卖家。
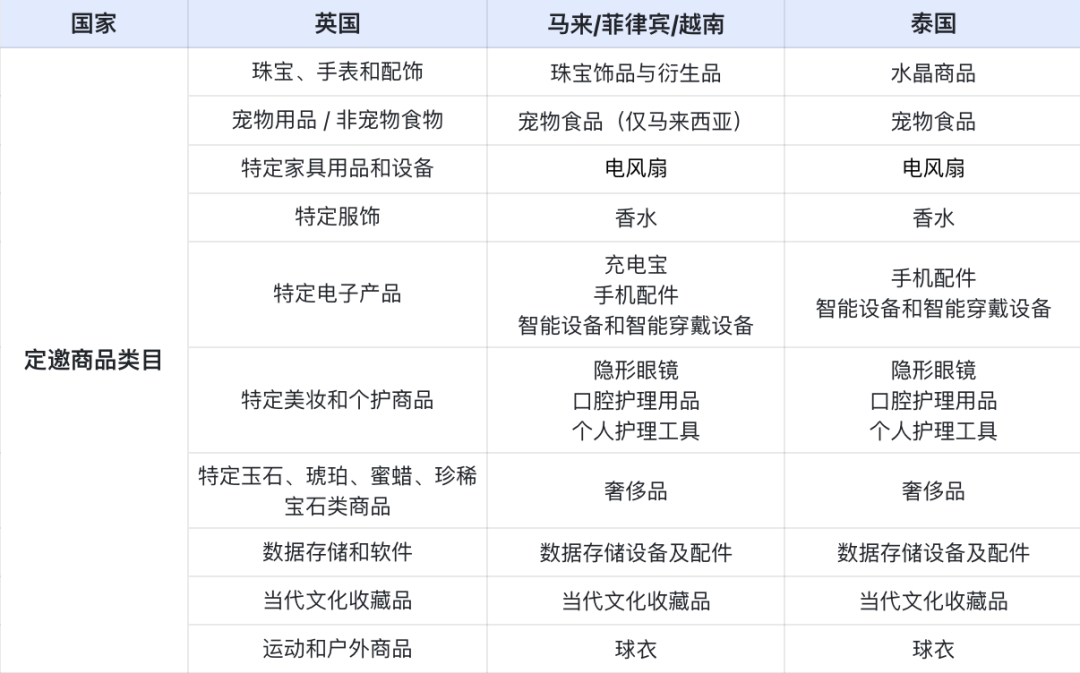
定邀商品/类目有哪些?
“定邀”商品指只有通过“定邀”流程入驻的卖家才能销售的特定商品。相关卖家需要通过卖家中心提交必要的文件进行审核,以下是目前规则中心可查询的各国TikTok跨境电商定邀类目/商品;
图片来源:TikTok
如何成为“定邀”卖家?
申请成为“定邀”类目的卖家,必须针对您希望运营的每个市场分别提交一份申请,一共可以分为6步;重要提示:目前,TikTok资质中心仅适用于桌面端。
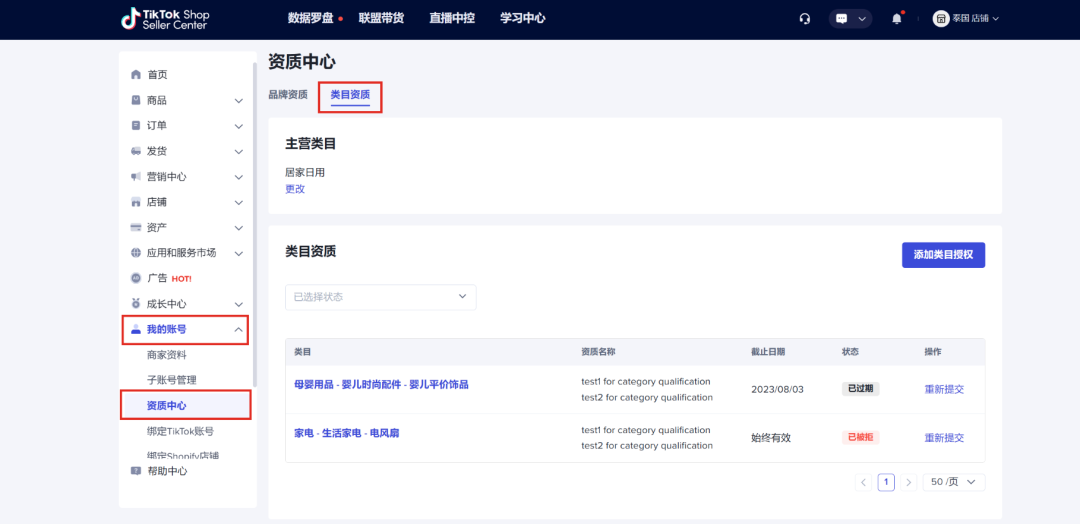
第1步:在电脑端打开“TikTok Shop Seller Center”,进入“我的账号” > “账号设置” > “资质中心”。
图片来源:TikTok
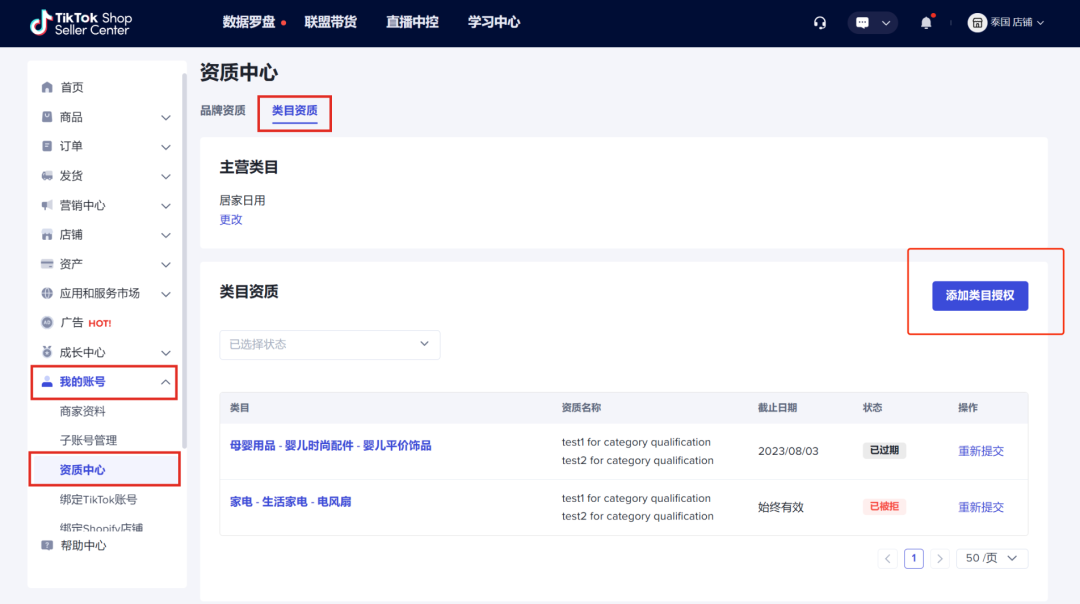
第2步:选择“添加类目授权”。
图片来源:TikTok
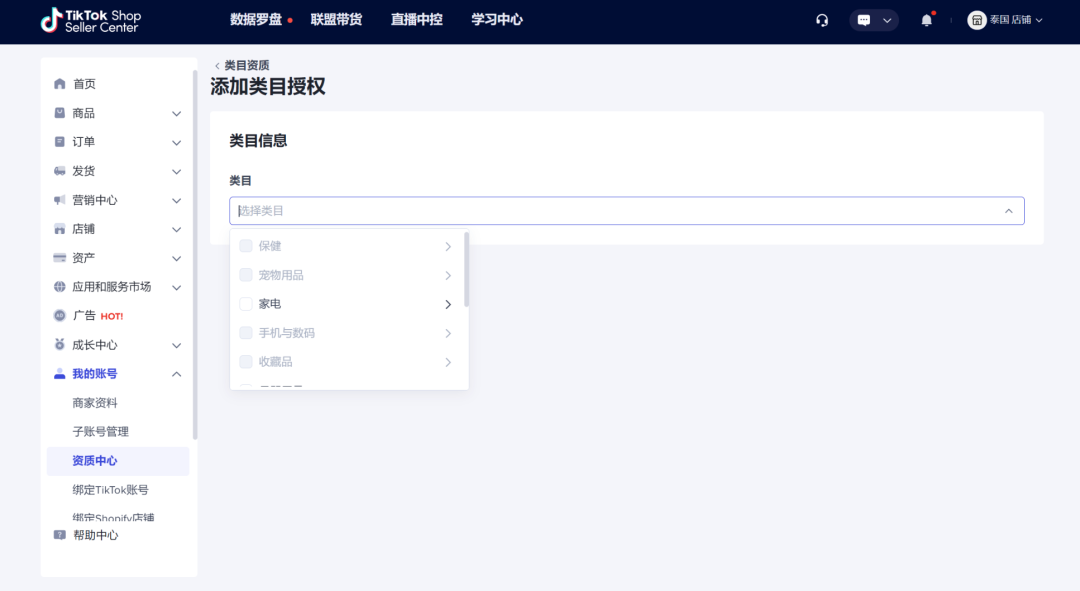
第3步:选择您想要申请的类目,您可以选择多个类目(如需要)。
图片来源:TikTok
第4步:提交必要的相关文件;如果涉及有效期,那么请提供有效的文件;仔细核对需要手动输入的任何信息是否与提供的文件相匹配;确保提交的所有材料都是真实的,以免申请被驳回,虚假记录可能会导致处罚。
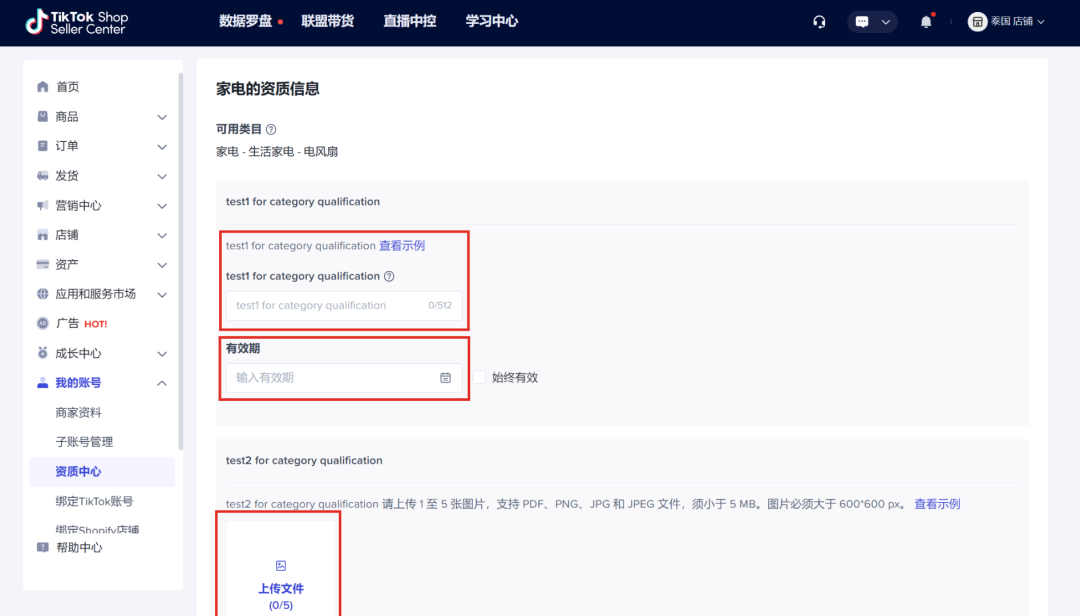
图片来源:TikTok
第5步:提交请求;确保所有提交的信息准确无误,在提交后的申请等待处理期间,无法申请/编辑类目。

图片来源:TikTok
第6步:审核结果;TikTok将通过电子邮件和“消息中心”向您告知申请状态;一申请获得批准,就可以在指定的类目下发布商品。
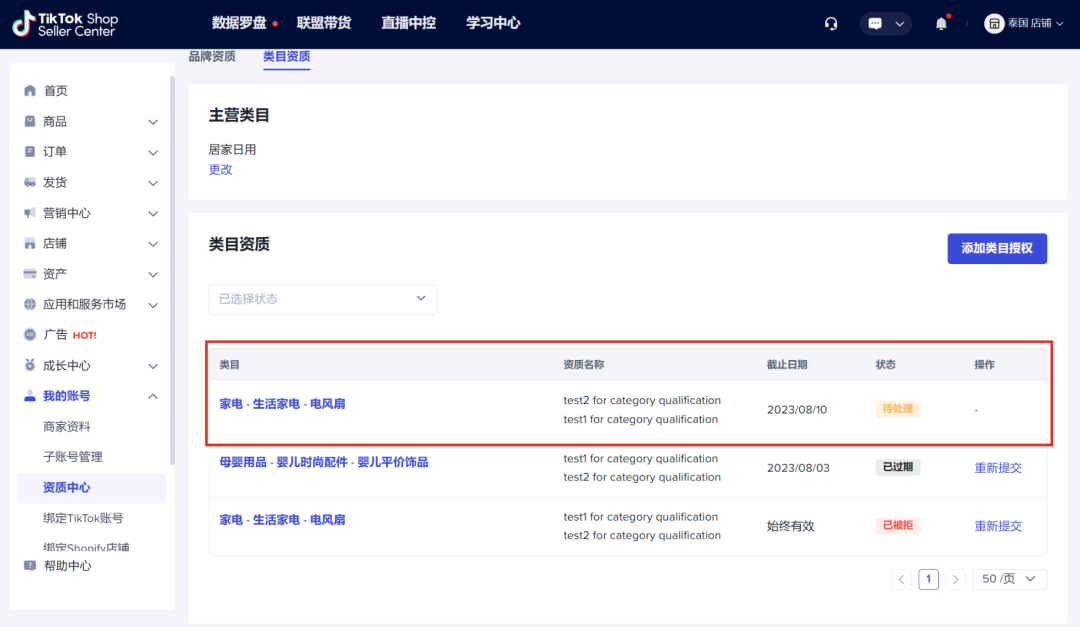
图片来源:TikTok
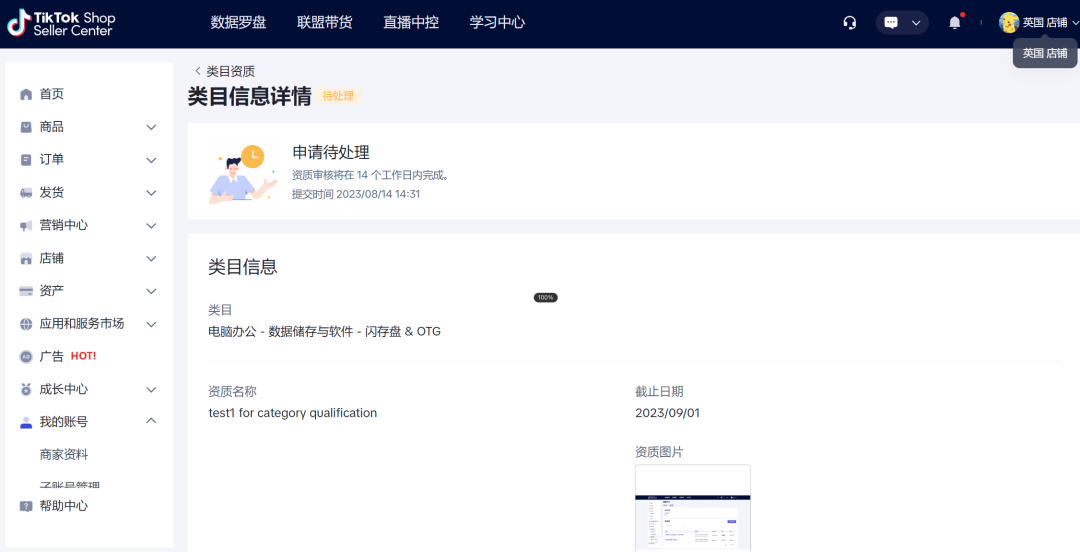
图片来源:TikTok
如果申请被驳回,该如何申诉?
查看被驳回的原因,并按照官方建议的步骤重新提交申请。如果需要进一步的帮助,可以通过提交帮助工单,与官方取得联系。