宿迁网站建设公司排名中国加盟网
文章目录
- 前言
- 一、huggingface的trainer的self.state与self.control初始化调用
- 二、TrainerState源码解读(self.state)
- 1、huggingface中self.state初始化参数
- 2、TrainerState类的Demo
- 三、TrainerControl源码解读(self.control)
- 总结
前言
在 Hugging Face 中,self.state 和 self.control 这两个对象分别来源于 TrainerState 和 TrainerControl,它们提供了对训练过程中状态和控制流的访问和管理。通过这些对象,用户可以在训练过程中监视和调整模型的状态,以及控制一些重要的决策点。
一、huggingface的trainer的self.state与self.control初始化调用
trainer函数初始化调用代码如下:
# 定义Trainer对象
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,)在Trainer()类的初始化的self.state与self.control初始化调用,其代码如下:
class Trainer:def __init__(self,model: Union[PreTrainedModel, nn.Module] = None,args: TrainingArguments = None,data_collator: Optional[DataCollator] = None,train_dataset: Optional[Dataset] = None,eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,tokenizer: Optional[PreTrainedTokenizerBase] = None,model_init: Optional[Callable[[], PreTrainedModel]] = None,compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,callbacks: Optional[List[TrainerCallback]] = None,optimizers: Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),preprocess_logits_for_metrics: Optional[Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None,):...self.state = TrainerState(is_local_process_zero=self.is_local_process_zero(),is_world_process_zero=self.is_world_process_zero(),)self.control = TrainerControl()...
二、TrainerState源码解读(self.state)
1、huggingface中self.state初始化参数
这里多解读一点huggingface的self.state初始化调用参数方法,
self.state = TrainerState(is_local_process_zero=self.is_local_process_zero(),is_world_process_zero=self.is_world_process_zero(),)
而TrainerState的内部参数由trainer的以下2个函数提供,可知道这里通过self.args.local_process_index与self.args.process_index的值来确定TrainerState方法的参数。
def is_local_process_zero(self) -> bool:"""Whether or not this process is the local (e.g., on one machine if training in a distributed fashion on severalmachines) main process.这个过程是否是本地主进程(例如,如果在多台机器上以分布式方式进行训练,则是在一台机器上)。"""return self.args.local_process_index == 0def is_world_process_zero(self) -> bool:"""Whether or not this process is the global main process (when training in a distributed fashion on severalmachines, this is only going to be `True` for one process).这个过程是否是全局主进程(在多台机器上以分布式方式进行训练时,只有一个进程会返回True)。"""# Special case for SageMaker ModelParallel since there process_index is dp_process_index, not the global# process index.if is_sagemaker_mp_enabled():return smp.rank() == 0else:return self.args.process_index == 0
self.args.local_process_index与self.args.process_index来源self.args
2、TrainerState类的Demo
介于研究state,我写了一个Demo来探讨使用方法,class TrainerState来源huggingface。该类实际就是一个存储变量的方式,变量包含epoch: Optional[float] = None, global_step: int = 0, max_steps: int = 0等内容,也进行了默认参数赋值,其Demo如下:
from dataclasses import dataclass
import dataclasses
import json
from typing import Dict, List, Optional, Union
@dataclass
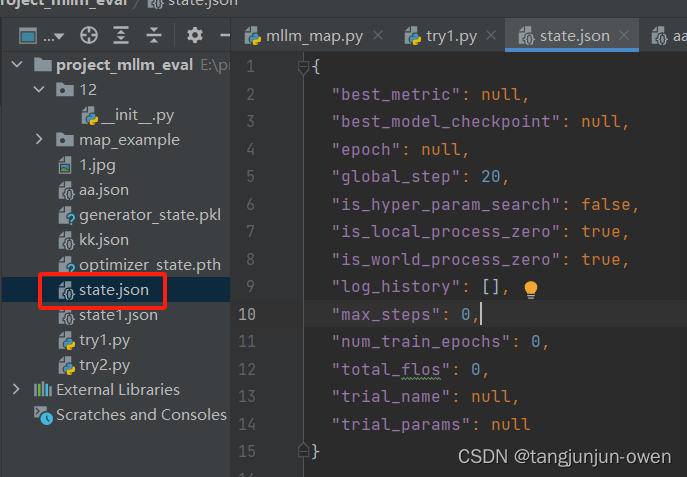
class TrainerState:epoch: Optional[float] = Noneglobal_step: int = 0max_steps: int = 0num_train_epochs: int = 0total_flos: float = 0log_history: List[Dict[str, float]] = Nonebest_metric: Optional[float] = Nonebest_model_checkpoint: Optional[str] = Noneis_local_process_zero: bool = Trueis_world_process_zero: bool = Trueis_hyper_param_search: bool = Falsetrial_name: str = Nonetrial_params: Dict[str, Union[str, float, int, bool]] = Nonedef __post_init__(self):if self.log_history is None:self.log_history = []def save_to_json(self, json_path: str):"""Save the content of this instance in JSON format inside `json_path`."""json_string = json.dumps(dataclasses.asdict(self), indent=2, sort_keys=True) + "\n"with open(json_path, "w", encoding="utf-8") as f:f.write(json_string)@classmethoddef load_from_json(cls, json_path: str):"""Create an instance from the content of `json_path`."""with open(json_path, "r", encoding="utf-8") as f:text = f.read()return cls(**json.loads(text))if __name__ == '__main__':state = TrainerState()state.save_to_json('state.json')state_new = state.load_from_json('state.json')我这里使用state = TrainerState()方法对TrainerState()类实例化,使用state.save_to_json('state.json')进行json文件保存(如下图),若修改里面参数,使用state_new = state.load_from_json('state.json')方式载入会得到新的state_new实例化。
三、TrainerControl源码解读(self.control)
该类实际就是一个存储变量的方式,变量包含 should_training_stop: bool = False, should_epoch_stop: bool = False, should_save: bool = False, should_evaluate: bool = False, should_log: bool = False内容,也进行了默认参数赋值,其源码如下:
@dataclass
class TrainerControl:"""A class that handles the [`Trainer`] control flow. This class is used by the [`TrainerCallback`] to activate someswitches in the training loop.Args:should_training_stop (`bool`, *optional*, defaults to `False`):Whether or not the training should be interrupted.If `True`, this variable will not be set back to `False`. The training will just stop.should_epoch_stop (`bool`, *optional*, defaults to `False`):Whether or not the current epoch should be interrupted.If `True`, this variable will be set back to `False` at the beginning of the next epoch.should_save (`bool`, *optional*, defaults to `False`):Whether or not the model should be saved at this step.If `True`, this variable will be set back to `False` at the beginning of the next step.should_evaluate (`bool`, *optional*, defaults to `False`):Whether or not the model should be evaluated at this step.If `True`, this variable will be set back to `False` at the beginning of the next step.should_log (`bool`, *optional*, defaults to `False`):Whether or not the logs should be reported at this step.If `True`, this variable will be set back to `False` at the beginning of the next step."""should_training_stop: bool = Falseshould_epoch_stop: bool = Falseshould_save: bool = Falseshould_evaluate: bool = Falseshould_log: bool = Falsedef _new_training(self):"""Internal method that resets the variable for a new training."""self.should_training_stop = Falsedef _new_epoch(self):"""Internal method that resets the variable for a new epoch."""self.should_epoch_stop = Falsedef _new_step(self):"""Internal method that resets the variable for a new step."""self.should_save = Falseself.should_evaluate = Falseself.should_log = False
总结
本文主要介绍huggingface的trainer中的self.control与self.state的来源。