网站设计的灵感来源重庆市卫生厅网站 查询前置审批

🌈个人主页: Aileen_0v0
🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法
💫个人格言:"没有罗马,那就自己创造罗马~"
目录
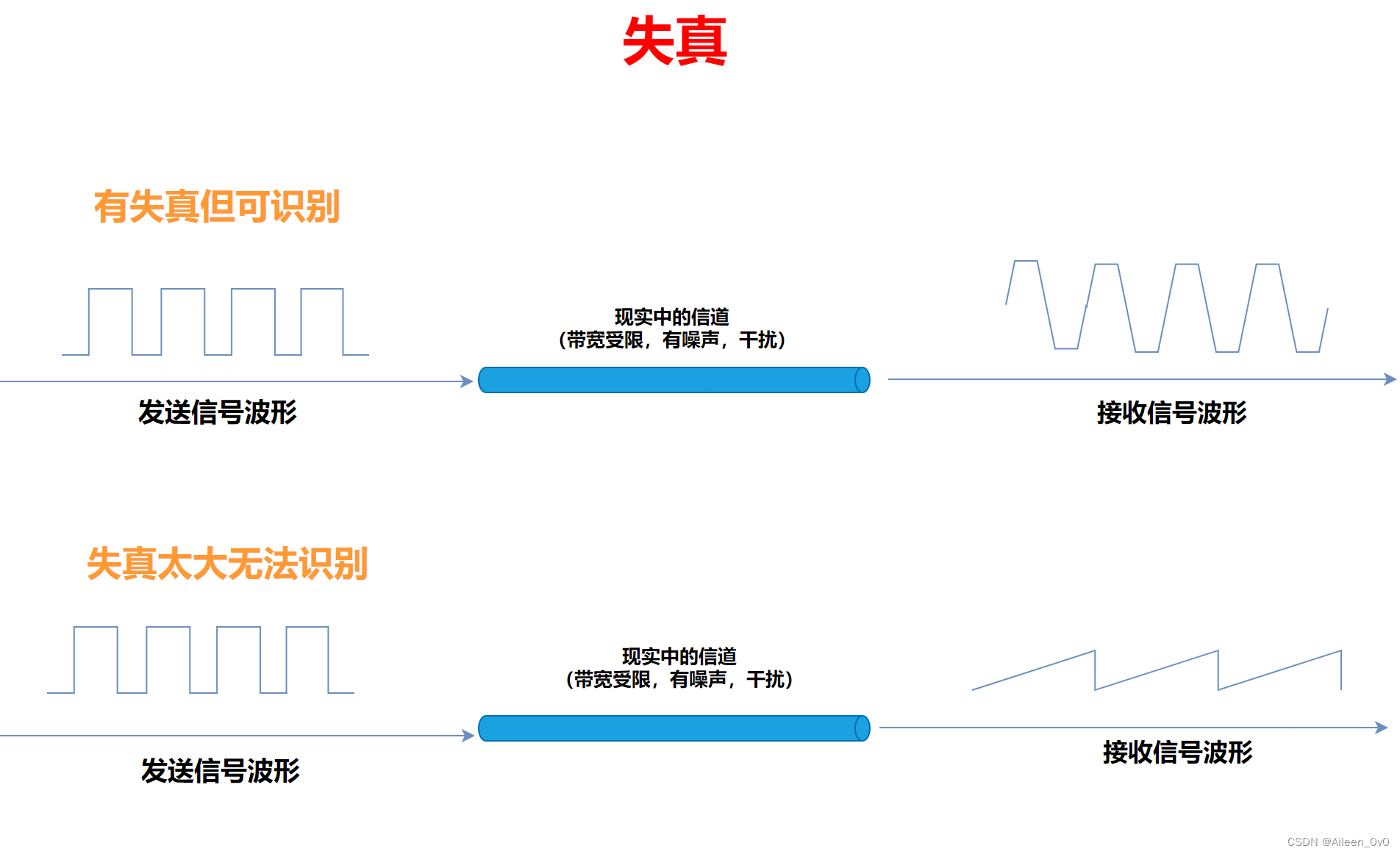
失真 - 信号的变化
影响信号失真的因素:
编辑
失真的一种现象:码间串扰
奈氏准则:
奈氏准则概念及使用条件:
奈氏准则相关例题:
奈氏准则的四条结论:
香农定理:
香农定理概念及使用条件:
香农定理相关例题:
香农定理的五条结论:
📝总结:
Practice1:
Practice2:
失真 - 信号的变化
影响信号失真的因素:
-
噪声:在信号传输过程中,环境中存在的各种噪声,如电磁干扰、热噪声等,会导致信号失真。
-
频率衰减:在信号传输过程中,信号的频率会随着传输距离的增加而衰减,导致信号失真。
-
时延失真:在信号传输时,由于信号传播速度的限制,信号的到达时间可能会有一定的延迟,导致信号失真。
-
非线性失真:在信号传输过程中,由于传输介质的非线性特性,信号的波形可能会发生变形,导致信号失真。
-
多径传播:在无线通信中,信号在传输过程中可能经过多条路径到达接收端,不同路径的传播时间和衰减程度不同,导致信号失真。
-
多普勒效应:在移动通信中,由于移动终端和基站之间的相对运动,信号的频率会发生变化,导致信号失真。
-
编码和解码误差:在数字通信中,编码和解码过程中可能发生误差,导致信号失真。
-
传输介质的损耗:传输介质(如电缆、光纤等)自身的损耗也会导致信号失真。
最重要的四个因素是: 码元传输速率,信号传输距离,噪声干扰 ,传输媒体质量前面三种影响因素是正向影响,即码元传输速率越大,影响失真的程度就越大,而最后一种是反向影响,即传输媒体质量越好,影响失真的程度就越小。
失真的一种现象:码间串扰

信号震动频率过低,信号易衰减和损耗掉。
信号震动频率过高,接收端难以识别信号波形,易发生码间串扰。
信道带宽:
最高频率和最低频率之差。 3300Hz - 300Hz = 3000Hz
码间串扰:
接收端收到的信号波形失去了码元间清晰界限的现象。(传输速率过快)
奈氏准则:
定义:
奈氏准则,是1924年奈奎斯特推导出的准则,是指在理想低通(无噪声,带宽受限【低于最高频率】)条件 下,为了避免码间串扰,码元的传输速率的上限值 ,极限码元传输速率为 2W Baud,W是信道带宽,单位是Hz。(只有奈氏准则和香农定理的公式中带宽的单位是Hz!!)
M是指离散电平数目,即共有几种码元;
W是理想低通信道①的带宽,单位为赫(Hz);
Baud是波特,是码元传输速率的单位,1波特为每秒传送1个码元.
每赫带宽的理想低通信道的最高码元传输速率是每秒2个码元.
奈氏准则概念及使用条件:
在理想低通(无噪声,带宽受限【低于最高频率】)条件下
传输速率 = 2Wlog2(V) b/s
W:带宽
V:码元个数 = 相位 X 振幅

奈氏准则相关例题:
例:在无噪声的情况下,若某通信链路的带宽为3KHz,采用4个相位,每个相位具有4种振幅的QAM调制技术,则该通信链路的最大数据传输率是多少?

奈氏准则的四条结论:
- 在任何信道中,码元传输的速率是有上限的。若传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的完全正确识别成为不可能。
- 信道的频带越宽(即能通过的信号高频分量越多),就可以用更高的速率进行码元的有效传输。
- 奈氏准则给出了码元传输速率的限制,但并没有对信息传输速率给出限制。
- 由于码元的传输速率受奈氏准则的制约,所以要提高数据的传输速率,就必须设法使每个码元能携带更多个比特的信息量,这就需要采用多元制的调制方法。

香农定理:
香农定理概念及使用条件:
定义:
香农定律是关于信道容量的计算的一个经典定律,可以说是信息论的基础。在高斯白噪声背景下的连续信道的容量.
噪声存在于所有的电子设备和通信信道中。由于噪声随机产生,它的瞬时值有时会很大,因此噪声会使接收端对码元的判决产生错误。
但是噪声的影响是相对的,若信号较强,那么噪声影响相对较小。因此,信噪比就很重要。
信噪比(dB)=信号的平均功率/噪声的平均功率,常记为S/N,并用分贝 (dB)作为度量单位,
若题目给的条件信噪比含有单位---dB 则需要利用下面这个公式将它转换成(S/N)即:
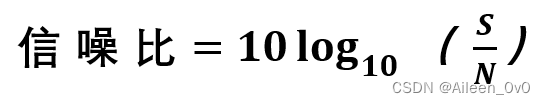
(有噪声,带宽受限【低于最高频率】)条件下 --- 用香农定理

香农定理相关例题:
例:电话系统的典型参数是信道带宽为3000Hz,信噪比为30dB,则该系统最大数据传输速率是多少?

香农定理的五条结论:
- 信道的带宽或信道中的信噪比越大,则信息的极限传输速率就越高。
- 对一定的传输带宽和一定的信噪比,信息传输速率的上限就确定了。
- 只要信息的传输速率低于信道的极限传输速率,就一定能找到某种方法来实现无差错的传输。
- 香农定理得出的为极限信息传输速率,实际信道能达到的传输速率要比它低不少。
- 从香农定理可以看出,若信道带宽W或信噪比S/N没有上限(不可能),那么信道的极限信息传输速率也就没有上限.

📝总结:
若条件里面,即含数据传输的进制(一个码元携带的bit信息量),又含信噪比,则两个准则都要计算一遍它的数据传输速率,然后选择最小的那个数据传输速率(才是实际可达到的最大值)。
Practice1:
二进制信号在信噪比为1023:1的4kHz信道上传输,最大的数据速率可达到多少?

Practice2:
二进制信号在信噪比为127:1的4kHz信道上传输,最大的数据速率可达到多少?



