找人做软件网站烟台营销型网站建设
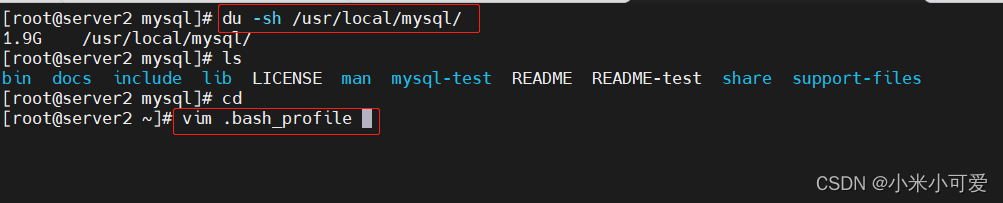
1.MySQL数据库编译


make完之后是这样的
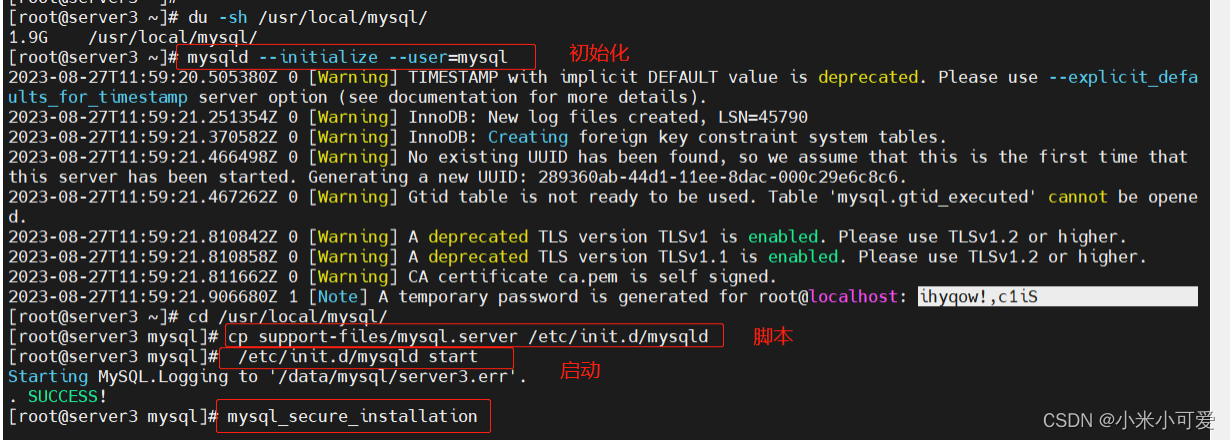
mysql 初始化
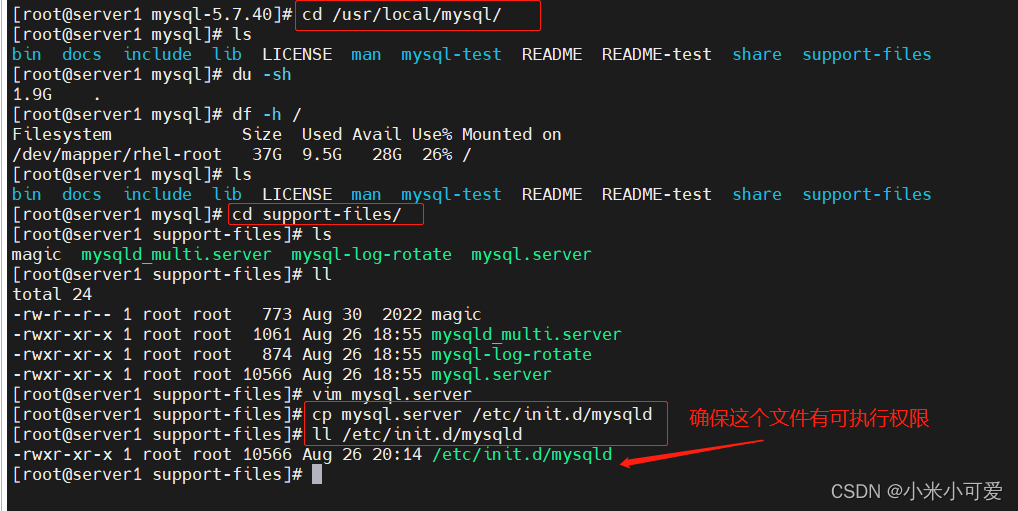

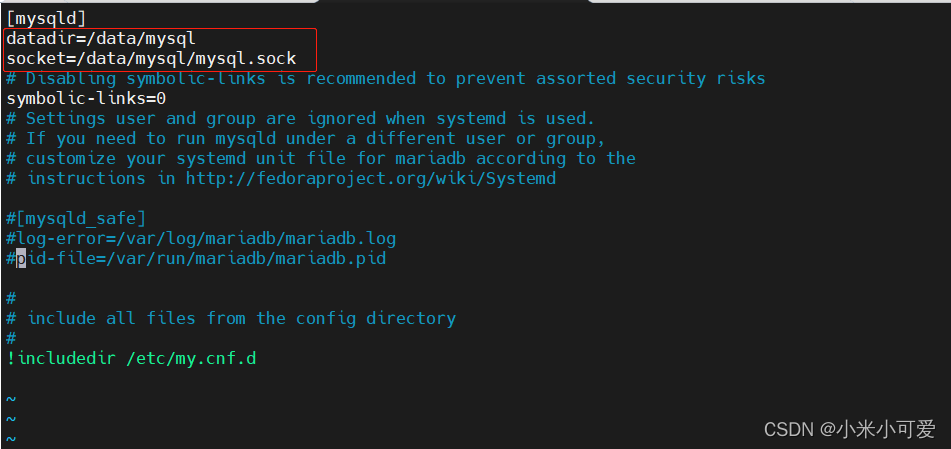
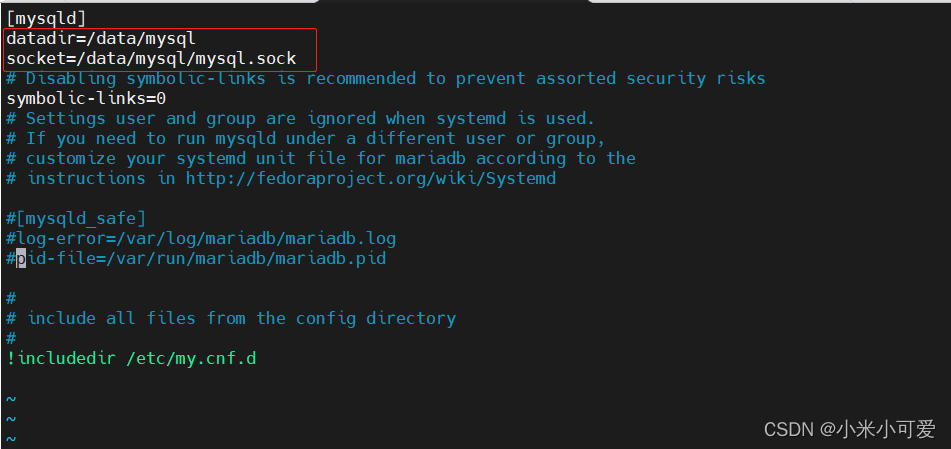
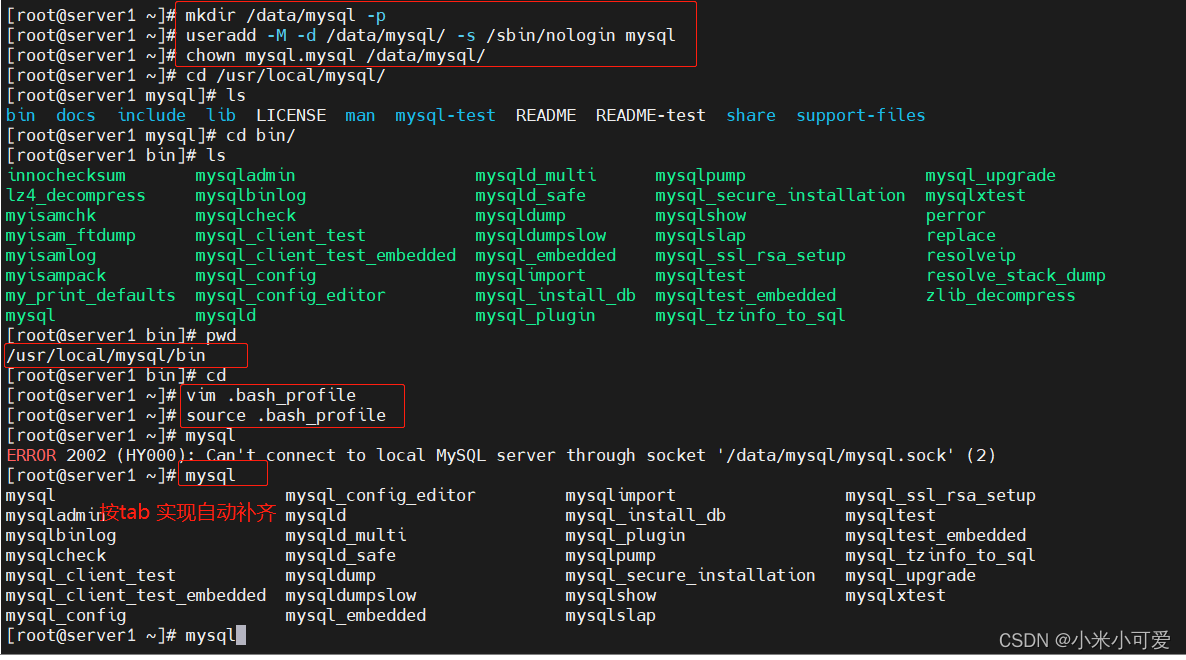
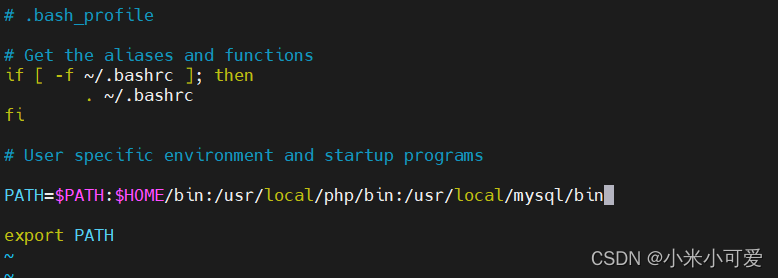
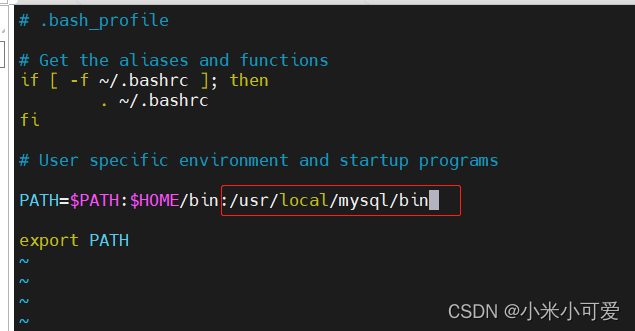
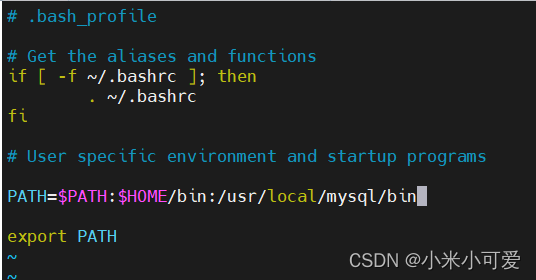
所有这种默认不在系统环境中的路径里 就这样加
这样就可以直接调用 不用输入路径调用
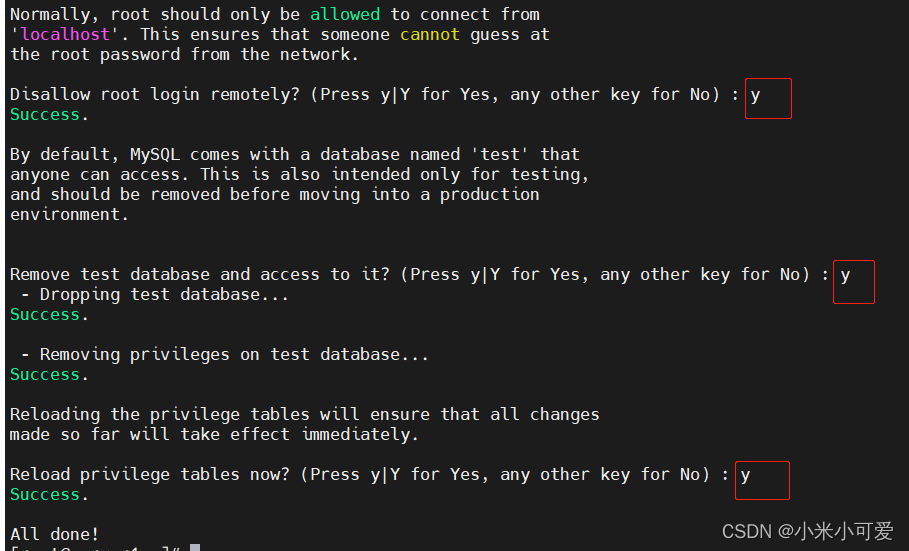
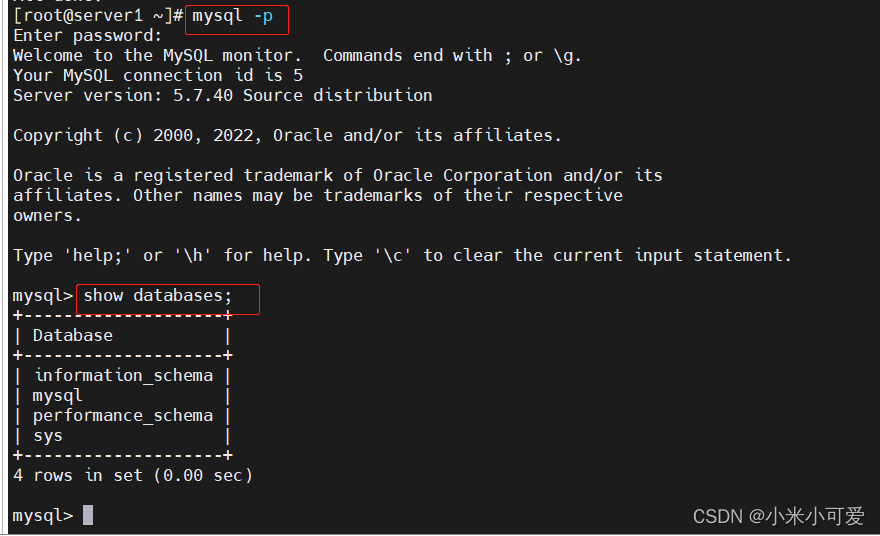
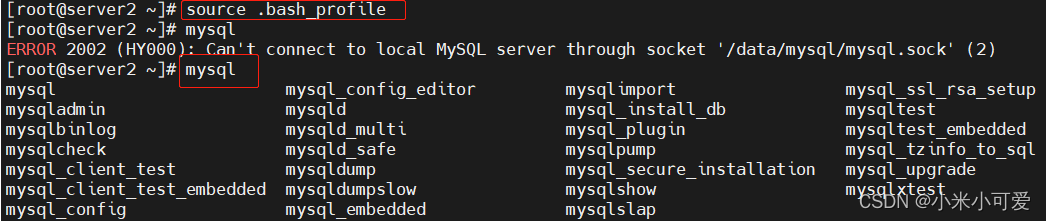
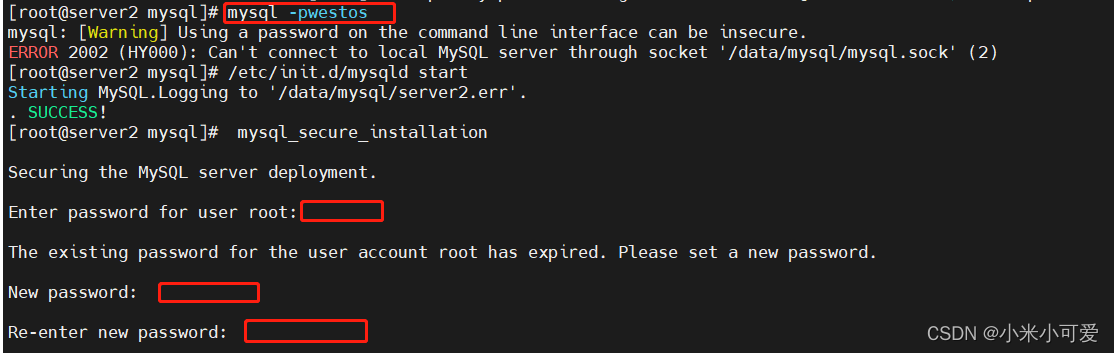
2.初始化
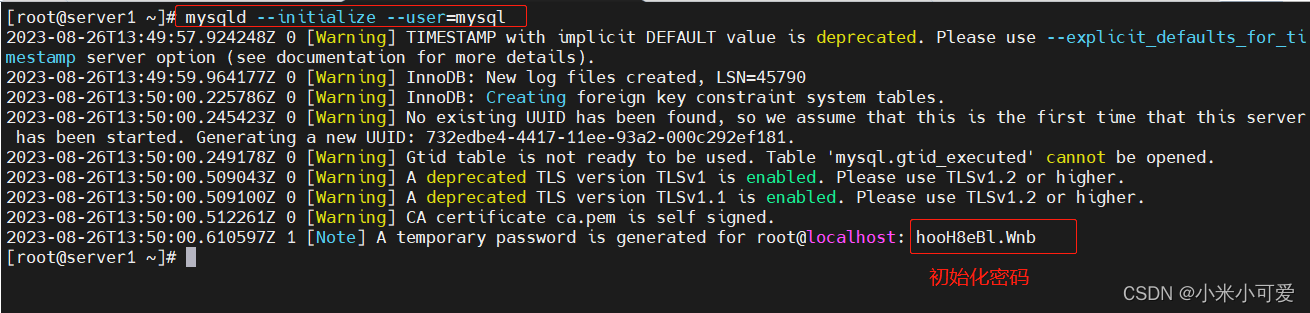

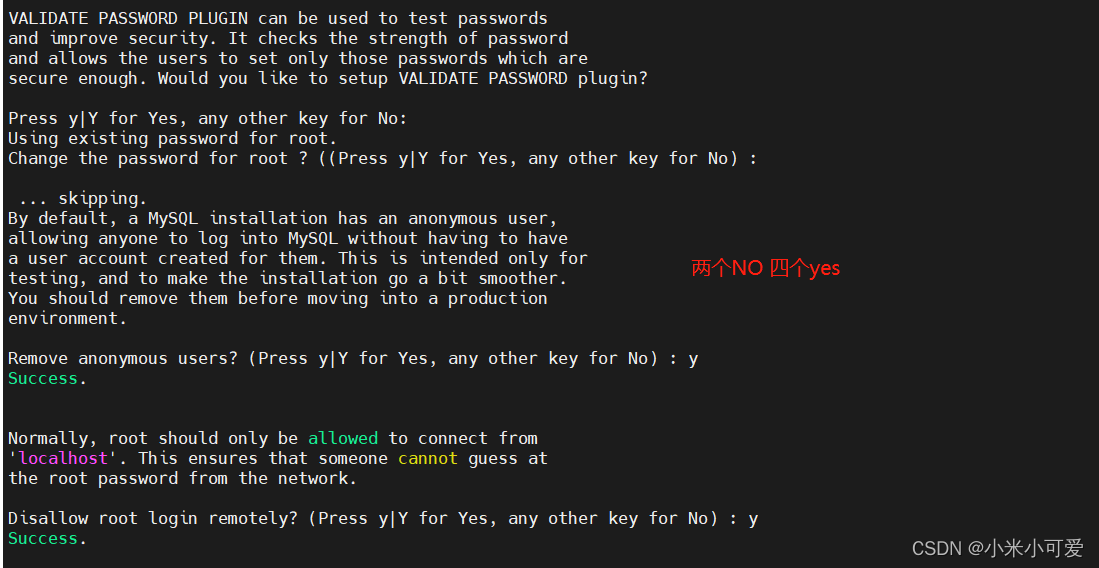
重置密码
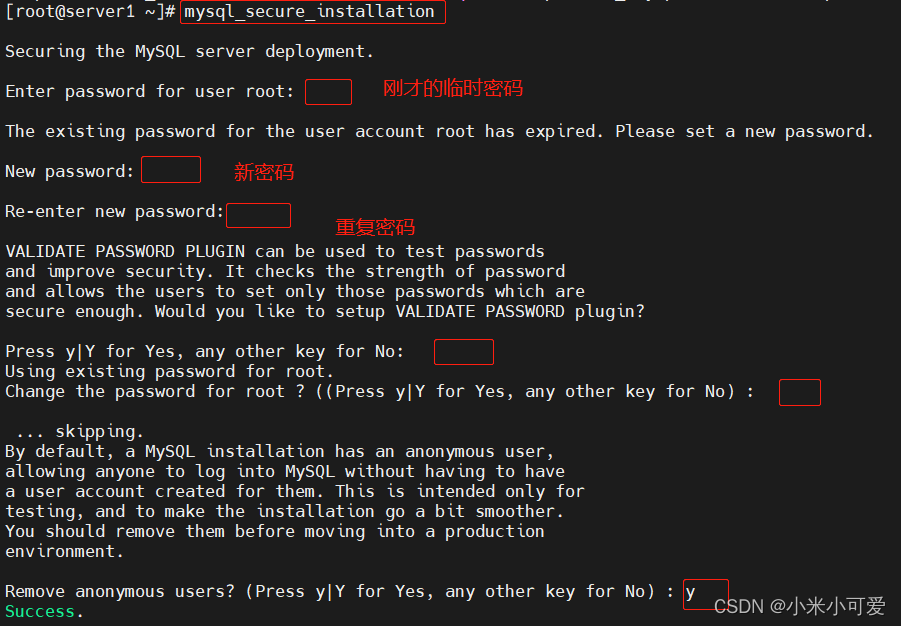
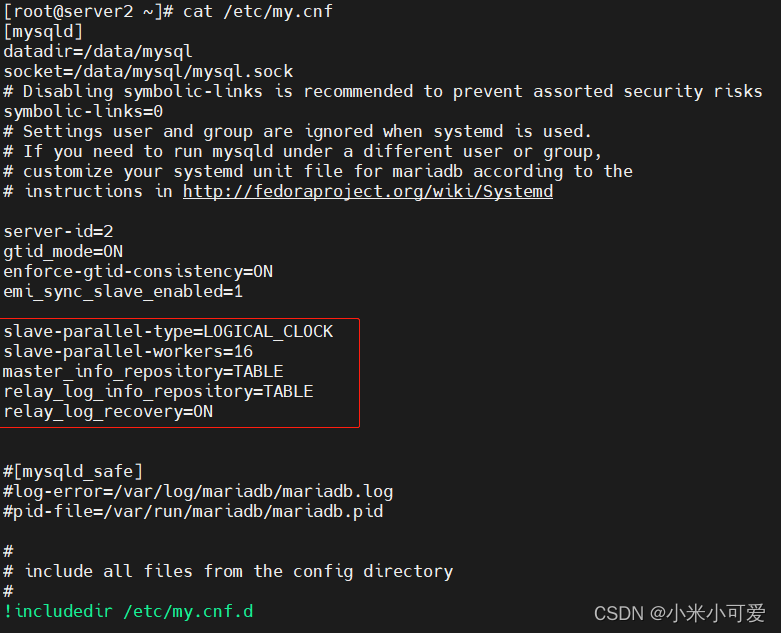
3.mysql主从复制
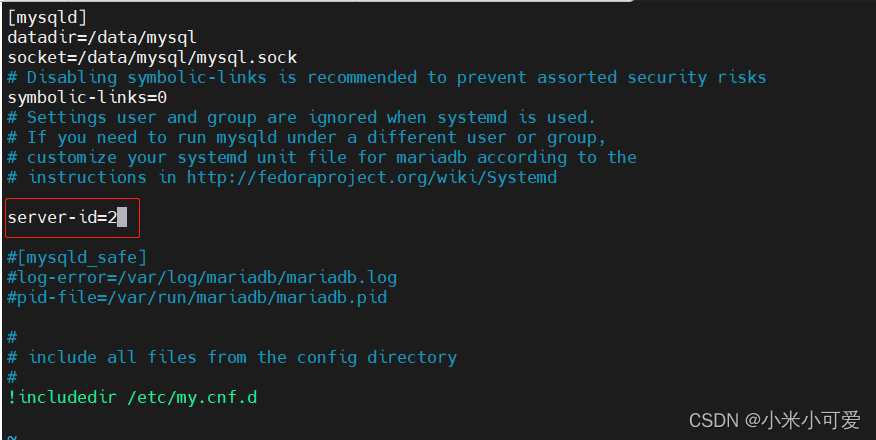
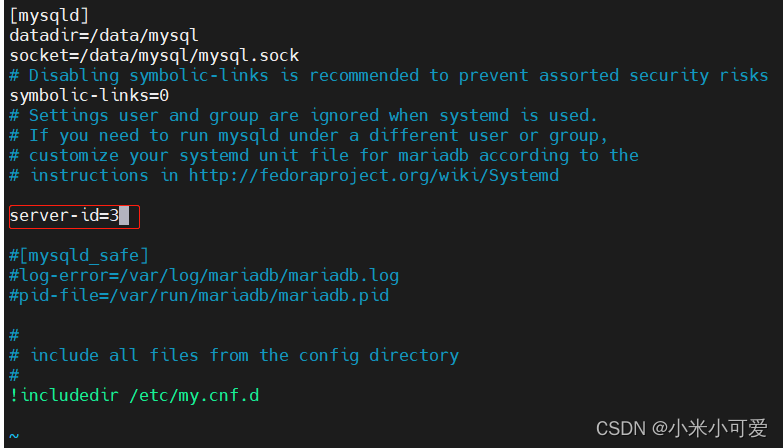
配置master




配置slave
当master 端中还没有插入数据时
在server2 上配slave
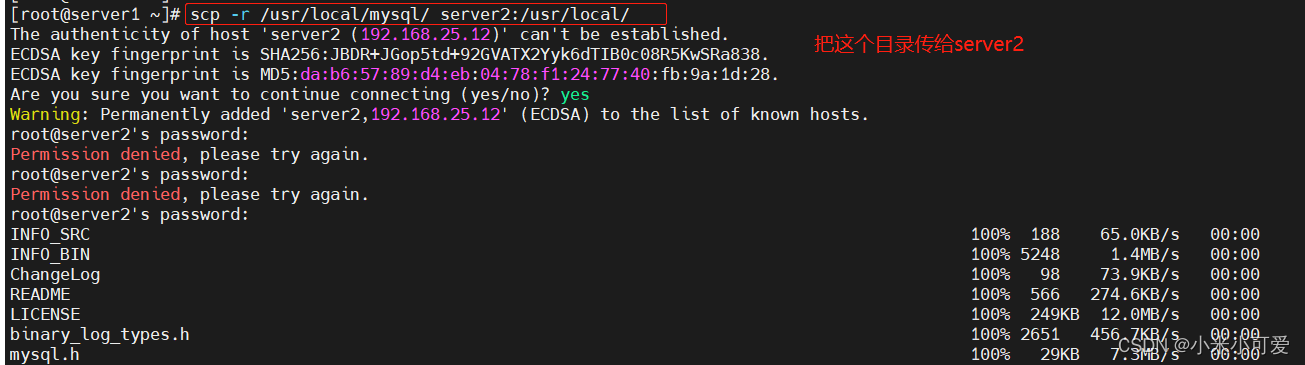




此时master 还没进行任何增删改查动作
在 server2上
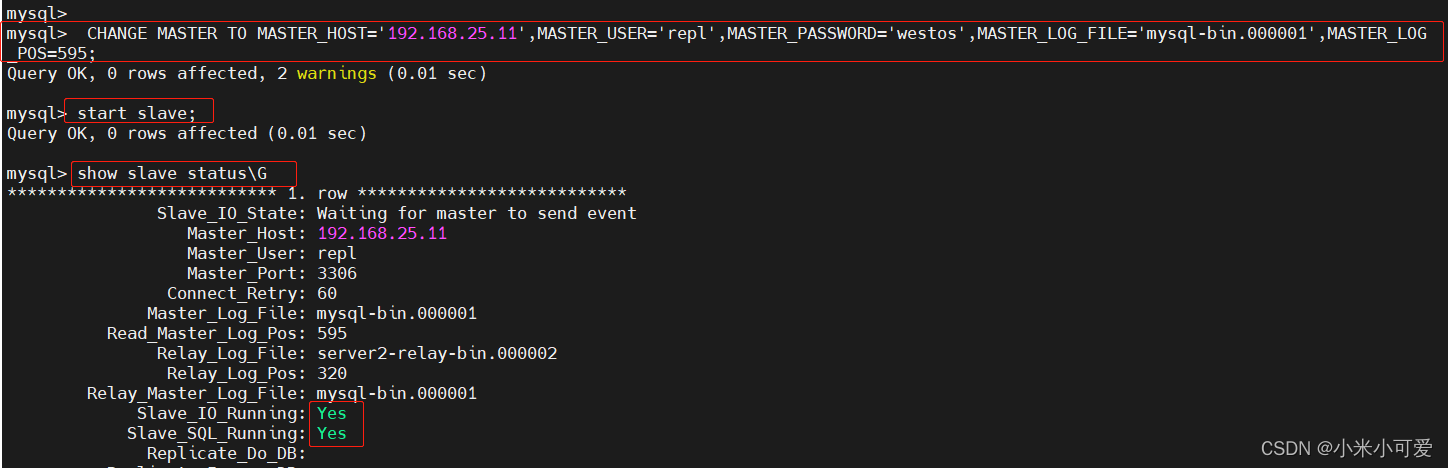
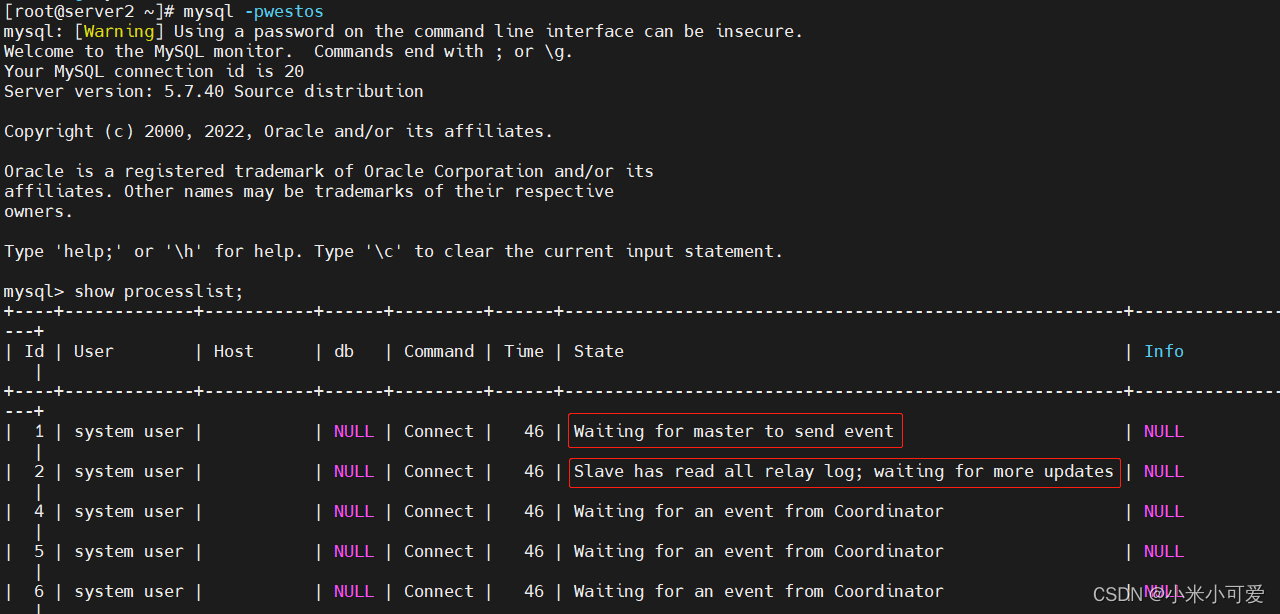
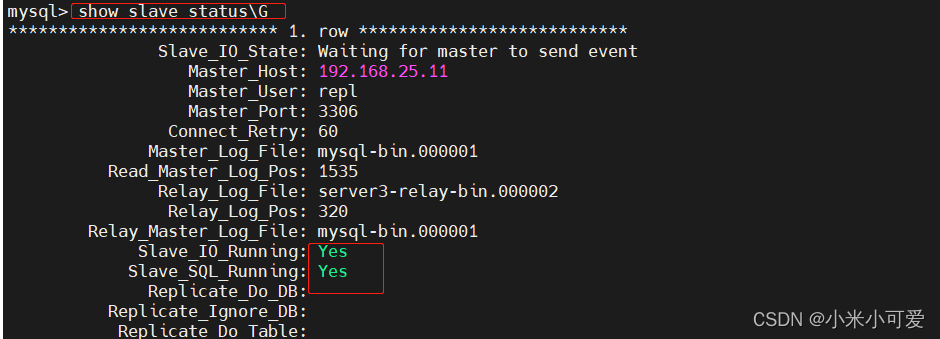
测试
在master 上
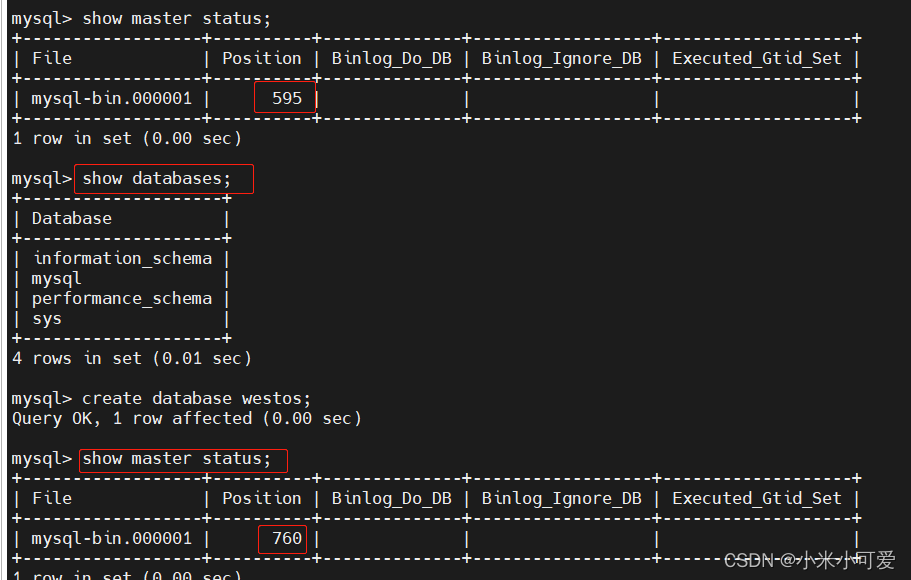

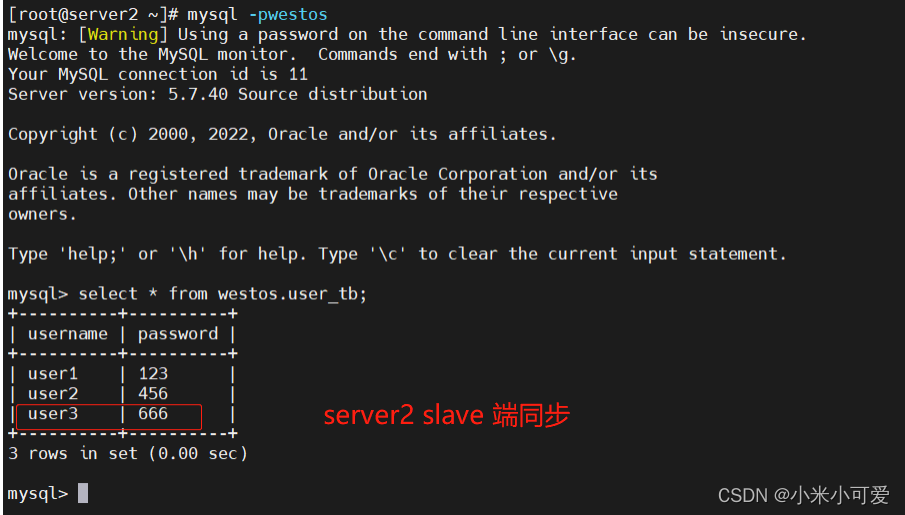
在server2 上会实现同步

当master 端有数据的时候 怎么同步呢
在server1 上

在server2 上

在server3 上


在server1 master 上
注意:
生产环境中备份时需要锁表,保证备份前后的数据一致
mysql> FLUSH TABLES WITH READ LOCK;
备份后再解锁
mysql> UNLOCK TABLES;
注意:
mysqldump命令备份的数据文件,在还原时先DROP TABLE,需要合并数据时需要删除此语句

在server3 上

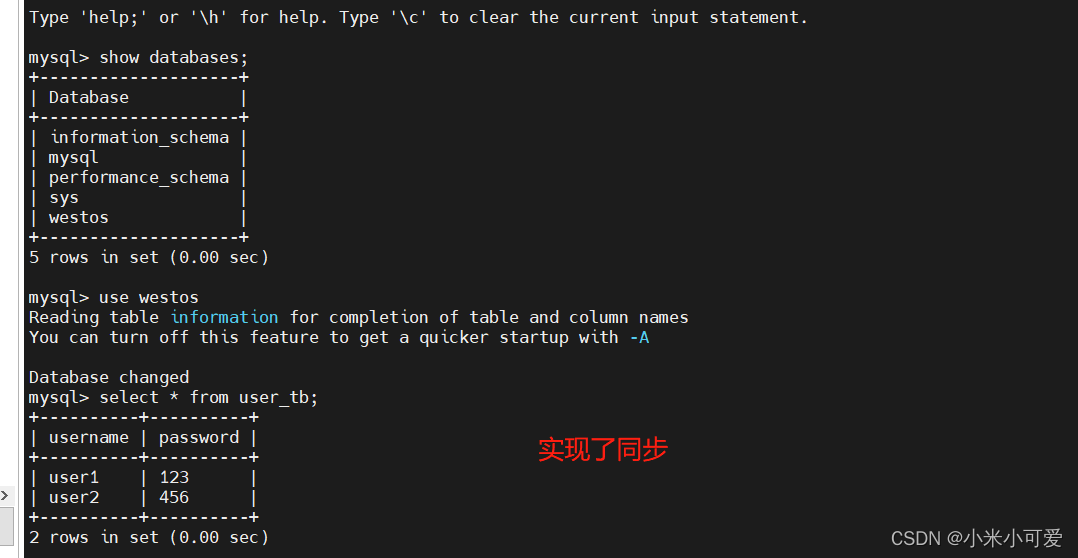
实现主从同步

测试

只有读的操作 远远多于写的操作 时 才会用一主多从
数据库的外部需要接入高可用负载均衡
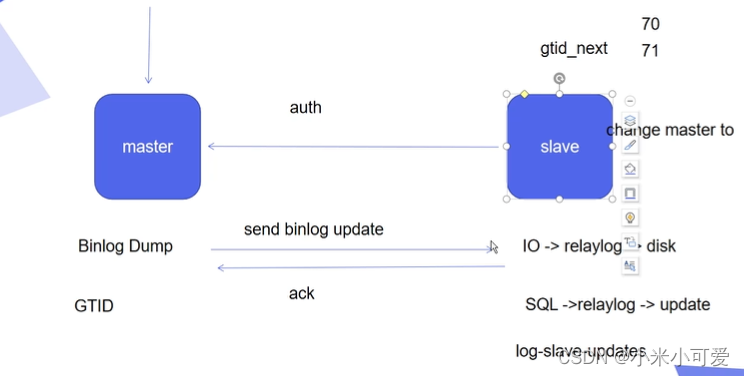
这套传统的主从 缺陷: master 端Binlog是直接考给slave的 是异步操作 什么是异步 master 端更新完了之后 直接发给slave master 不需要知道slave端是否接收到 这样就会导致比如master 端到slave端网络出现问题 意思就是 master可以成功运作 也把日志发给slave 但是由于网络的问题 这个数据没有真正发送给slave端 那么这时候master down掉之后 slave端开始接管的时候 数据就会丢失
在IO这边 有个内置的半同步模式

 在IO这边 有个内置的半 gtid模式
在IO这边 有个内置的半 gtid模式
master配置

slave配置
在server2上
首先停止slave
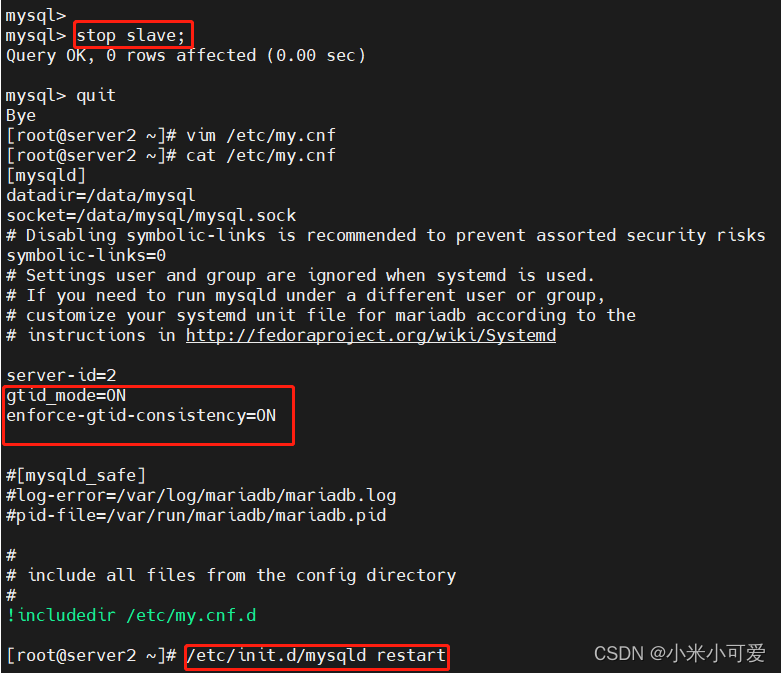
重新配置+重新启动

其他节点以此内推

在gtid模式下 当master 有问题的时候 就会挑离它id最近的slave 作为master 供给下面的slave 以此内推
异步方式 得知道接管的那个master 上的日志文件和那个号 这样很复杂 异步的 虽然很快 但是 无法保证无损()
通过设置gtid 大大降低复杂度 通过全局的方式 不用关心它的日志文件和binlog号 gtid 只关心它的下一跳是谁就行 就是 gtid next
半同步模式
首先解决IO
给master 端安装半同步模块
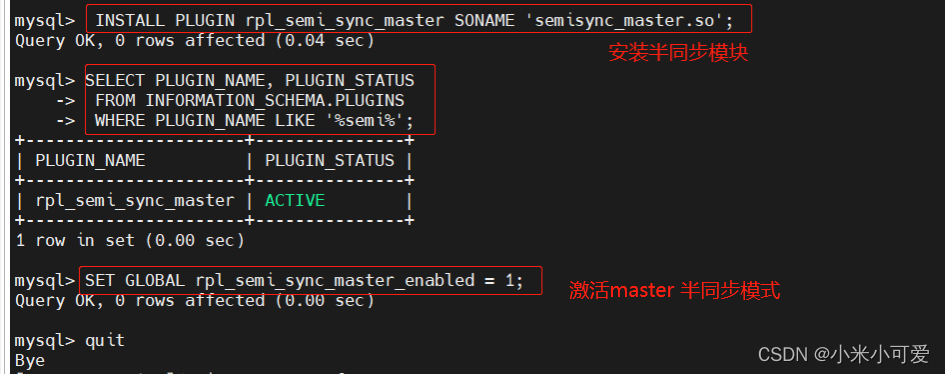
半同步参数写入配置文件,确保重启后依然生效 master 和salve都要设置

给slave端安装slave的半同步模块

![]()
需要重启IO线程,slave端的半同步才生效


半同步参数写入配置文件,确保重启后依然生效 master 和salve都要设置
测试
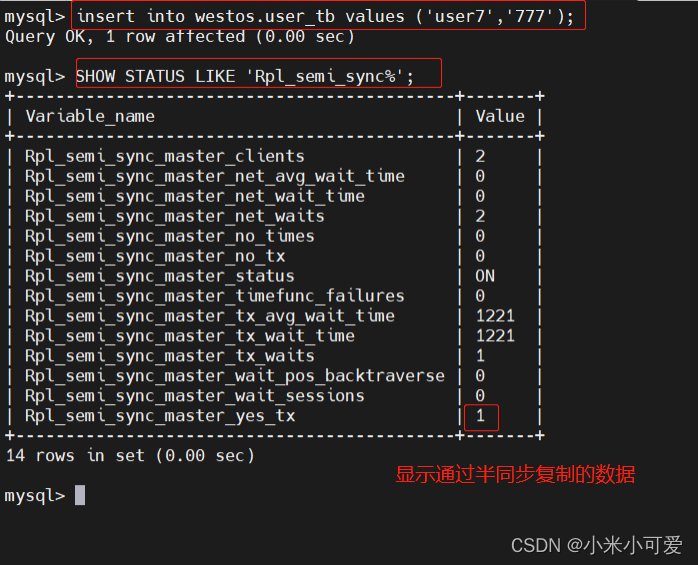
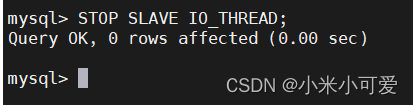
当停止所有slave节点的IO线程:
在master 端插入数据
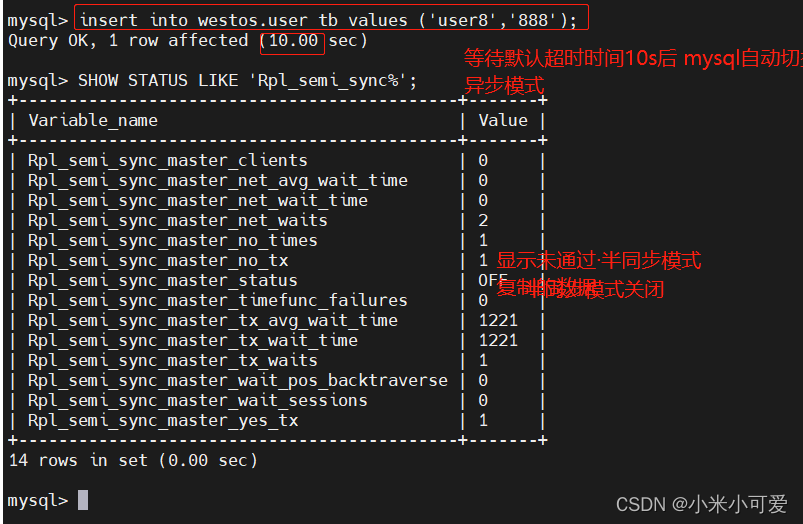
所有slave节点再次启动IO线程,mysql会自动切回半同步模式
mysql> START SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
解决sql 线程的问题
并行复制 提高效率
默认slave节点sql单线程回放,会造成数据同步延时较高
slave节点添加以下参数
在salve端 不需要在master 端 因为sql 线程在 slave端