栖霞建设采购网站怎么制作网站来赚钱
目录
- 认识Redis
- 分布式系统
- Redis的特性
- Redis的应用场景
- Redis客户端
- Redis命令
认识Redis

上面一段话是官网给出的对Redis的介绍,in-memory data store表明Redis是在内存中存储数据的,这和我们接触的其他数据库就有很大的不同,比如MySQL,它是将数据存储在磁盘中的,但由于MySQL需要与磁盘交互,访问速度就比较慢,而很多互联网产品,又对性能要求比较高,这时,Redis就可以发挥出它的作用了,因为是在内存中存储数据,就意味着访问速度远比在磁盘中快,极大地提高了程序的性能。
Redis也不是各方面领先于MySQL,比如在存储空间上,是远小于MySQL的,毕竟磁盘的空间要远大于内存!
要想存储的数据多,访问速度也快,就可以考虑将MySQL和Redis结合起来使用,因为20%的热点数据能满足80%的访问需求,但带来的问题是:系统的复杂程度大大提升了,而且数据发生修改时,还涉及到Redis和MySQL之间的数据同步问题,此时,Redis被作为cache
Redis的初心,就是用来作为一个"消息中间件"的(消息队列),然而,当前很少会直接使用Redis作为消息中间件,因为业界有更多更专业的消息中间件使用
为什么要有Redis,直接用变量存储不行?
在单机程序,Redis相对于变量存储数据,没有优势可言,但在分布式系统中,才能发挥威力,基于网络,可以把自己内存中的变量给别的进程,甚至别的主机的进程进行使用
分布式系统
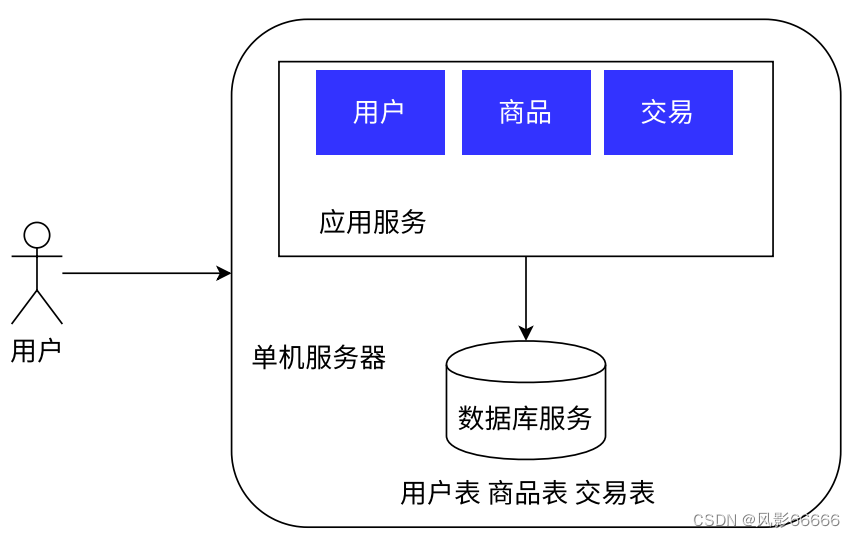
单机架构
如下图,是一个单机架构,只有一台服务器,它负责所有的工作,虽然只有一台服务器,但现在的硬件非常nice,也就意味着一台服务器的性能也很高,可以支持非常高的并发和非常大的数据存储,所以,绝大部分的公司的产品,就是这种单机架构!
分布式系统的引入
业务进一步增长,用户量和数据量都水涨船高,一台服务器难以应付,如果同一时刻处理的请求多了,可能会导致某个硬件资源不够用了,即导致服务器处理请求的时间变长,甚至于处理出错!
而要想解决这个问题,无非两种方式,第一个是节流,在软件上优化,但对程序员的水平要求就比较高;另一种方式就是引入更多的主机、更多的硬件资源,但一台主机的硬件资源是有限的,比如就4个内存插槽,你也就只能插4条内存条,所以就需要引入多台主机,此时的系统就可以称为是"分布式系统"
分布式系统的引入,会使得系统的复杂程度会大大提高,出现bug的概率也越高,则使用的人力成本上也就会越高,所以,引入分布式,是一种无奈之举!
应用服务和数据库服务分离
如下图, 将应用服务和数据库服务部署在不同的服务器,就可以给他们搭配不同的服务器,比如应用服务器,里面可能会包含很多的业务逻辑,可能会吃CPU和内存,就采用CPU和内存好的主机;而数据服务器,需要更大的硬盘空间,更快的访问速度,就可以配置更大硬盘的主机,甚至是SSD硬盘,这样就能达到更高的性价比!!!

引入更多的应用服务器节点
如下图,应用服务器可能会比较吃CPU和内存,如果把CPU和内存吃没了,此时应用服务器就顶不住了,就需要引入更多的应用服务器,来解决上述问题,同时也需要引入负载均衡器,用户的请求会先到达负载均衡器/网关服务器,然后根据负载情况,将请求分配给负载相对小的应用服务器,尽可能保证每台应用服务器处理的用户请求是均衡的,当然,这里就会用到负载均衡的相关算法
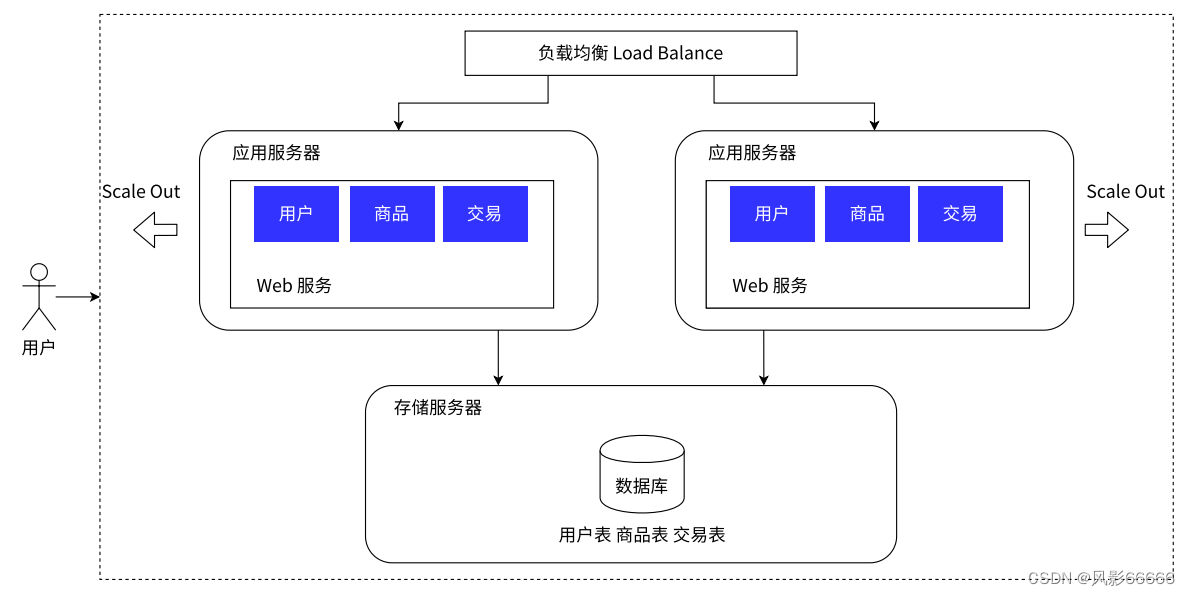
负载均衡器,对于请求量的承担能力,是远超过应用服务器的,因为负载均衡器就相当于领导,负责派发任务,而应用服务器则相当于职员,负责执行任务。如果出现请求量大到负载均衡器也扛不住了的时候,就可以引入更多的负载均衡器,即引入多个机房
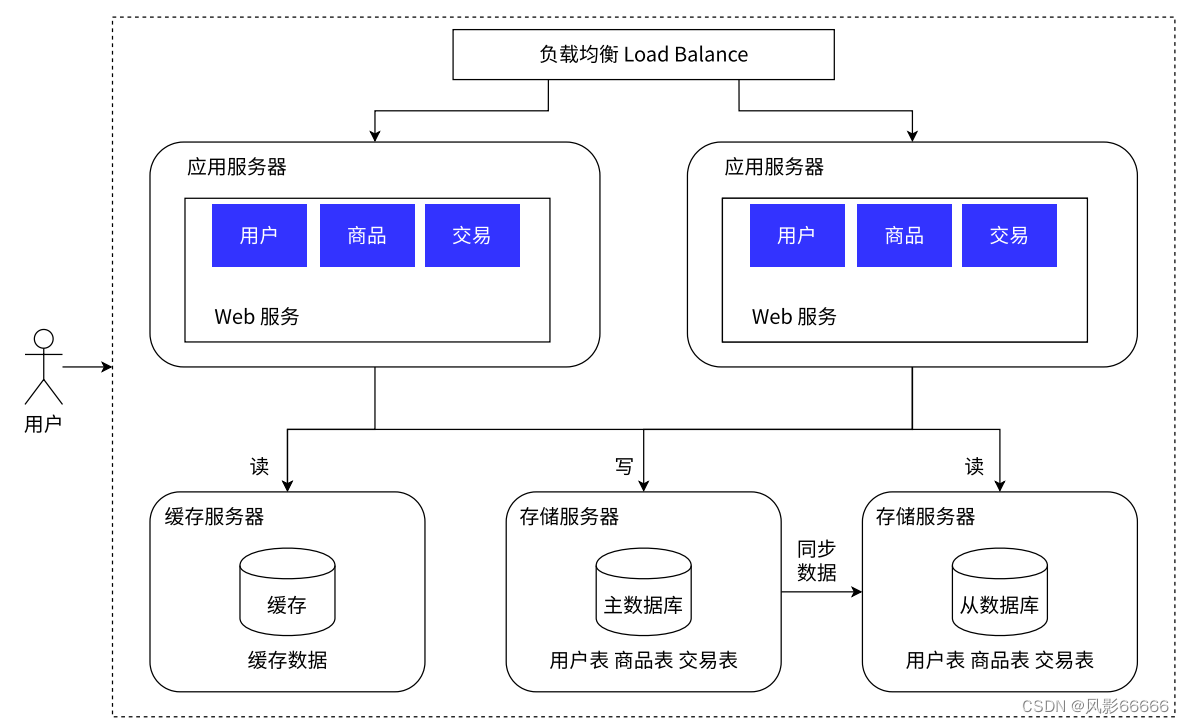
引入更多的数据库服务器(读写分离)
如下图,当数据量太多,一台数据库服务器难以支撑时,就需要引入更多的服务器来存储数据,而实际的应用场景中,读的频率是比写要高的,所以一般是一台主服务器,多台从服务器,主服务器负责写,读服务器负责读,同时从服务器通过负载均衡的方式,让应用服务器进行访问

引入缓存
数据库天然有个问题,那就是响应速度是更慢的!所以就需要把数据区分“冷热”,热点数据存放到缓存中,而缓存的访问速度往往比数据要快很多!如下图所示
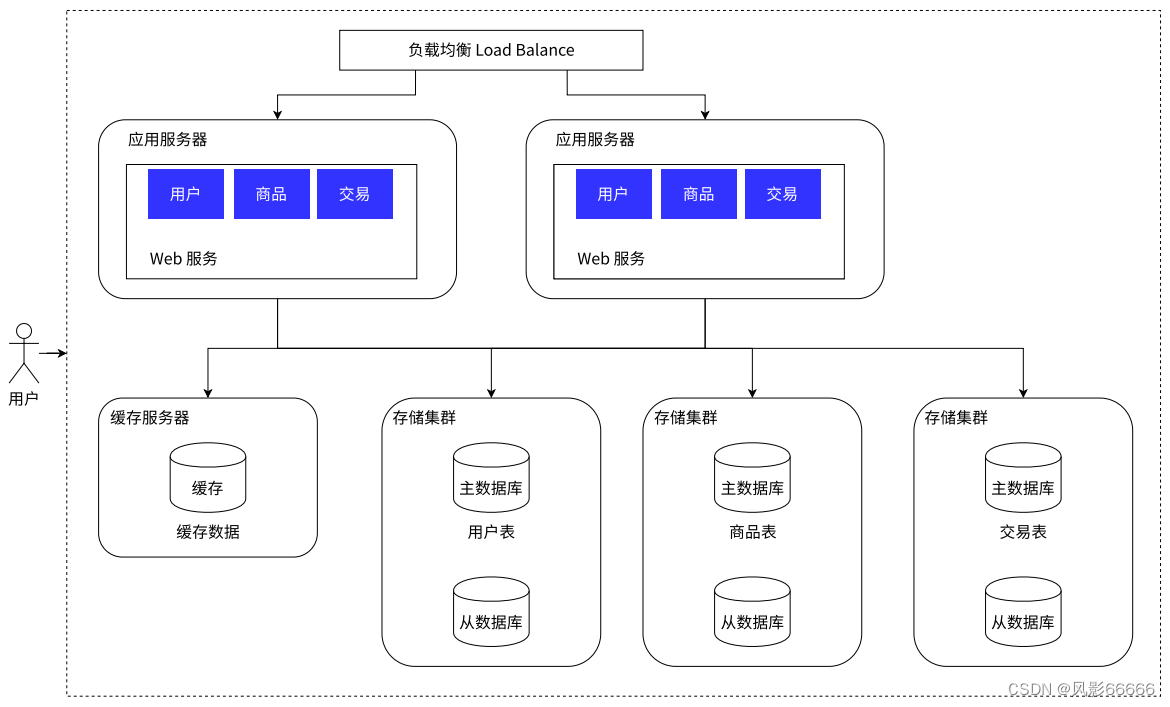
分库分表
当数据量更大时,一台服务器已经存不下了,就需要多台主机存储,同时能对数据库进行进一步的拆分,即分库分表。本来一台数据库服务器上有多个数据库(create database),现在引入多台数据库服务器,就能每个数据库服务器存储一个或者一部分数据库,甚至如果某个表特别大,一台主机存不下,也可以针对表进行拆分!具体分库分表如何实现,还要结合实际的业务场景来展开,因为业务决定技术。如下图所示
微服务架构
前面的应用服务器,里面可能做了很多的业务,这就可能导致这个服务器的代码变得非常复杂,而为了更方便代码的维护,就可以把这样的复杂的服务器,拆分成更多的,功能更单一的,但是更小的服务器,同时服务器的种类和数量就增加了!如下图所示
注意:微服务本质上是在解决"人"的问题
当应用服务器复杂了,就势必需要更多的人来维护,当人多了,就需要配套的管理,把这些人组织好,可以划分组织结构,分成多个组,每个组分别配备领导进行管理,分成多个组,就需要进行分工,而拆分成多组微服务,就利于人员的组织结构的分配了
微服务的优势
解决了人的问题;
使用微服务,可以更方便于功能的复用;
可以给不同的服务进行不同的部署
引入微服务,付出的代价?
系统性能的下降,而要想保证性能不下降太多,就需要引入更多、更好的硬件资源,而拆分出来更多的服务,多个功能之间要更依赖网络里通信,而如果用的网卡不是很好的那种,那网络通信的速度比硬盘还慢!
系统复杂程度提高,可用性受到影响,服务器更多了,出现问题的概念就更大了,这就需要一系列的手段,来保证系统的可用性,比如更丰富的监控报警,以及配套的运维人员
分布式系统的概念
应用/系统
一个应用,就是一个/组服务器程序
模块/组件
一个应用,里面有很多个功能,每个独立的功能,就可以称为是一个模块/组件
分布式
引入多个主机/服务器,协调配合完成一系列的工作(物理上的多台主机)
集群
引入多个主机/服务器,协调配合完成一系列的工作(逻辑上的多台主机)
主/从
分布式系统中一种比较典型的结构,多个服务器节点,其中一个是主,另外的则是从,从节点的数据要从主节点这里同步过来
中间件
和业务无关的服务(功能更通用的服务),比如数据库,缓存,消息队列
可用性
系统整体可用的时间/总的时间,也是一个系统的第一要务
响应时长
衡量服务器的性能,越小越好
吞吐 vs 并发
衡量系统的处理请求的能力,衡量性能的一种方式
Redis的特性

如上图,可以看出Redis是在内存中存储数据的,Redis主要是通过"键值对"的方式来存储组织数据,是一种"非关系型数据库",key都是string,value则可以是字符串、哈希表、列表、集合等等

如上图,针对Redis的操作,可用通过简单的交互式命令进行操作,也可以通过一些脚本的方式,批量执行一些操作(可以带有一些逻辑)
如上图,Redis提供了一组API,可以用C、C++和Rust语言在Redis原有的功能基础上再进行扩展,即编写动态链接库

如上图,为了使Redis存储的数据持久化,Redis会把数据存储再硬盘上,即内存为主,硬盘为辅

如上图,Redis作为一个分布式系统的中间件,能够支持集群是很关键的,这个水平扩展,类似于"分库分表"。
一个Redis能存储的数据是有限的,因为内存空间有限,就可以引入多台主机,部署多个Redis节点,每个Redis节点存储数据的一部分

如上图,Redis具有高可用特性,数据存在冗余/备份,Redis自身也是支持"主从"结构的,从节点就相当于主节点的备份了
为什么Redis快?
1、Redis数据存在内存中,就比访问硬盘的数据库,要快很多
2、Redis核心功能都是比较简单的逻辑,如比较简单的操作内存的数据结构
3、从网络角度,Redis使用了IO多路复用的方式
4、Redis使用的是单线程模型,减少了不必要的线程之间的竞争开销,因为Redis的核心任务主要是操作内存的数据结构,不会吃很多CPU
Redis的应用场景

如上图,Redis可以被当作数据库使用,虽然在大多数情况下,考虑到数据存储,优先考虑的是"大",但是仍然有一些场景,考虑的是"快",比如搜索引擎

如上图,Redis存的是部分数据,比如热点数据,全量数据都是以MySQL为主的,哪怕Redis的数据没了,还可以从MySQL那里加载回来
如上图,Redis可以作为消息队列,基于这个可以实现一个网络版本的生产者-消费者模型
如下图,在用户浏览某个网站时,访问不同的网页,负载均衡器有很大的可能将请求打到不同的应用服务器,而保存的session的只有一台服务器上有,这就会给用户带来不好的体验,毕竟要多次重新登录,此时有两种方式解决这个问题
1、想办法让负载均衡器,把同一个用户的请求始终打到同一台机器上,但就不能通过轮询的方式来选择应用服务器,而要用userld之类的方式来分配机器
2、把会话单独拎出来,放到一台独立的机器上存储(Redis)

Redis客户端
和MySQL一样,Redis也是一个客户端-服务器结构的程序,它的客户端和服务器可以在同一台主机上,也可以在不同主机上
Redis客户端的形态
命令行客户端redis-cli
图形化界面的客户端(桌面程序、web程序)
基于redis的API自行开发客户端(工作中最主要的形态),非常类似于MySQL的C语言API和JDBC
Redis命令
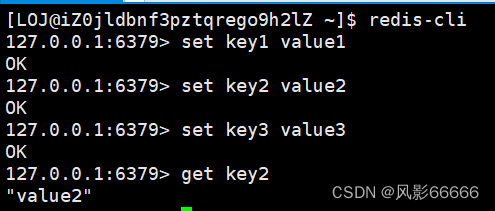
get和set命令
set:把key和value存储进去
get:根据key来获取value
set和get也是Redis最核心的两个命令
如下图,key和value都是字符串,即使没有加"“,当然,加”"或’'都是可以的
注意:Redis中的命令是不区分大小写的!!!
key不存在时,会直接返回空
Redis全局命令:能够搭配任意一个数据结构来使用的命令
keys命令
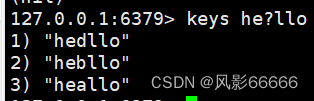
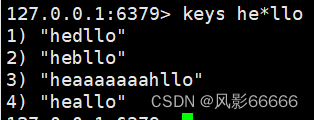
keys:用来查询当前服务器上匹配的key,后面接pattern,pattern方便查找我们想要的,keys类似于Linux中的grep命令
如下图,设置下面键值对,方便下面的演示
?:匹配任意一个字符
*:匹配0个或多个任意字符
[abcde]:只能匹配到a b c d e,别的不行,相当于给出固定的选项了

[^a]:排除a,只有a匹配不了,其他的都能匹配
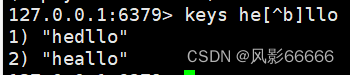
[a-b]:匹配a-b这个范围内的字符,包含两侧边界

注意:keys命令的时间复杂度是O(N),所以在生产环境上,一般都会禁止使用keys命令,尤其是大杀器keys *,它会查询出Redis中所有的key。生产环境上的key可能会非常多,而Redis是一个单线程的服务器,执行keys *的可能性非常长,使得Redis服务器被阻塞了,就无法给其他客户端提供服务了,这样的后果是灾难性的!
工作中会涉及到的几种环境
办公环境、开发环境、测试环境、线上环境/生产环境,操作线上环境的任何一个设备/程序都要怀着12分的谨慎!
exists命令
判断一个或多个key是否存在,时间复杂度O(1),返回值:key存在的个数,redis是按照哈希表的方式来组织的
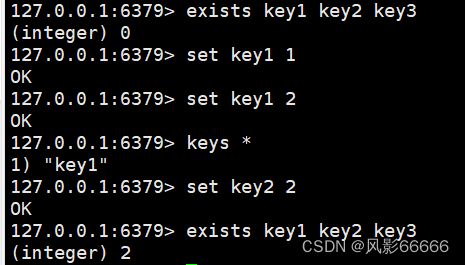
如上图,一次判断多个key,比起一次判断一个,效率会更高,因为redis是一个客户端—服务器结构的程序,而客户端与服务端是通过网络进行通信的,相对内存而言,网络通信很慢,所以走一次网络和走多次网络区别很大
del命令
删除指定的key,一次可以删除多个,时间复杂度O(1),返回值:删除掉的key的个数
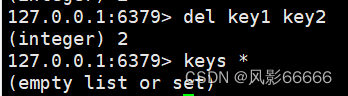
redis作为缓存时,误删了几个数据,相对于MySQL而言,影响不是很大,但如果把所有的数据或者一大半数据一下子干没了,影响就大了去了,本来redis是帮MySQL负重前行的,而redis数据被删了,就只能去MySQL中获取数据了,很容易把MySQL搞崩
redis作为数据库时,哪怕误删一个数据,影响都会很大
redis作为消息队列时,误删数据影响大不大,就需要具体问题具体分析了
expire命令
给指定的key设置过期时间,单位是秒,时间复杂度O(1),返回值:1表示设置成功,0表示设置失败
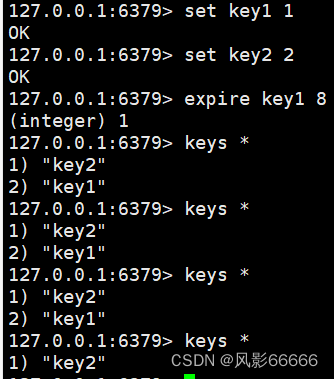
应用场景:手机验证码、外卖优惠券
注意:必须针对已经存在的key设置过期时间
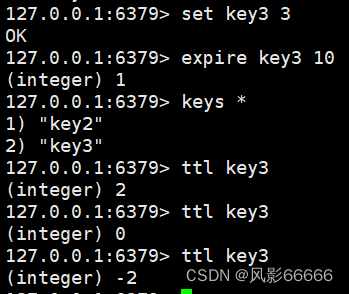
ttl命令(time to live)
查看当前key的过期时间还剩多少,时间复杂度O(1),-1表示没有关联过期时间,-2表示key不存在
redis中key的过期策略
如果直接遍历所有的key,显然是行不通的,效率太低了
redis整体的策略是定期删除和惰性删除
定性删除:每次抽取一部分,进行验证过期时间,保证这个抽取检查的过程足够快
为什么要对定性删除的时间,有明确的要求?
因为redis是单线程的程序,主要的任务执行命令,如果扫描过期key消耗的时间太多了,就可能导致正常处理请求命令就被阻塞了,类似于keys *
惰性删除:当某个key已经到过期时间了,但是暂时还没删它,key还存在,后面又一次访问,正好用到了这个key,于是这次访问就会让redis服务器触发删除key的操作,同时再返回一个nil
过期策略也可以通过定时器来实现!!!
定时器
概念:在某个时间达到之后,执行指定的任务
基于优先级队列实现定时器
假定现在又很多key都设置了过期时间,就可以把这些key加入到一个优先级队列中,指定优先级规则:过期时间早的,先出队列,队首元素,就是最早要过期的key,然后只需要给定时器分配一个线程,让这个线程取检查队首元素,看看是否过期即可,此时,扫描线程不需要遍历所有key,只需要盯住队首元素即可
在扫描线程检查队首元素过期时间的时候,也不能检查太频繁,可以根据当前时刻和队首元素的过期时间,设置一个等待,当时间差不多到了,系统再去唤醒这个线程,来新任务时,唤醒线程,重新设置阻塞时间即可!
基于时间轮实现定时器
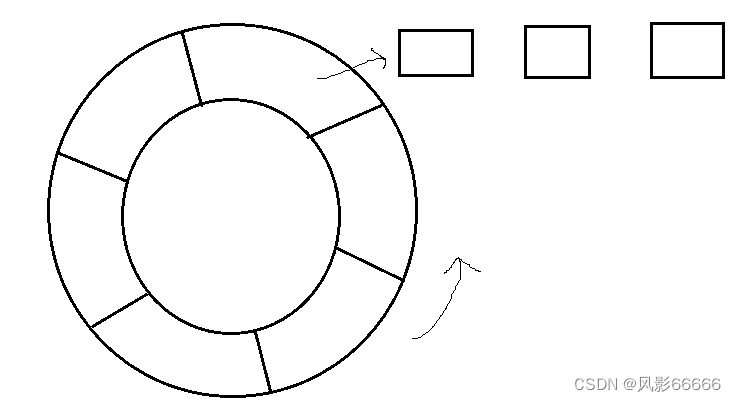
如上图,把时间划分成很多小段—划分的粒度,看实际需求
每个小段上都挂着一个链表,每个链表都代表一个要执行的任务(相当于一个函数指针,以及对应的参数啥的)
给定一个指针,指向时间轮中的一个格子,让它绕着这个时间轮旋转,每走到一个格子,就会尝试把这个格子上链表的任务尝试执行一下
注意:每个格子是多少时间,一共多少格子,都是需要根据实际场景,灵活调配的
type命令
查看这个key对应value的类型,有string、list、set、hash等等,时间复杂度O(1)