网站图标在哪里修改一个网站源代码概多大
1.springcloud微服务架构搭建 之 《springboot自动装配Redis》
2.springcloud微服务架构搭建 之 《springboot集成nacos注册中心》
3.springcloud微服务架构搭建 之 《springboot自动装配ribbon》
4.springcloud微服务架构搭建 之 《springboot集成openFeign》
目录
1.项目引入hystirx
1.1.项目引入hystrix坐标配置
1.2.项目启动类启用断路器
2. HystrixCommand 注解
2.1 使用HystrixCommand 实现fallback
2.1.1 正常性测试
2.1.2 停掉cms服务,模拟服务不可用
2.2 通过DefaultProperties实现全局fallback
2.2.1 停到cms服务,模拟测试
2.3 通过自定义参数配置接口的熔断策略
3.开启feign集成hystrix
3.1 FeignClient 接口实现降级策略,FallbackFactory
3.1.1 服务正常测试
3.1.2 停掉api服务测试
3.1.3 继续模拟频繁调用接口,则会触发熔断
4.全局Hystrix配置
5.参考
1.项目引入hystirx
1.1.项目引入hystrix坐标配置
<!-- hystrix 配置 版本号:2.1.3.RELEASE-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId><version>${spring.cloud.version}</version>
</dependency>1.2.项目启动类启用断路器
package lilock.cn.user;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;@SpringBootApplication(scanBasePackages = {"lilock.cn.*"})
@EnableConfigurationProperties
@EnableDiscoveryClient
@EnableFeignClients(basePackages = {"lilock.cn"}) //启用feign调用
@EnableCircuitBreaker // 启用断路器
public class UserApplication {public static void main(String[] args) {SpringApplication.run(UserApplication.class,args);}
}
2. HystrixCommand 注解
Hystrix提供了HystrixCommand,用于配置关于Hystrix相关配置,如:回调方法、超时时间、熔断配置等。想要使用hystrix,必须是用@HystrixCommand注解
这种模式下的hystrix使用,配置都是基于 @HystrixCommand注解配置的,我们通过在方法上添加 @HystrixCommand 注解并配置注解的参数来实现配置。
2.1 使用HystrixCommand 实现fallback
/*** 接口熔断* @return*/@HystrixCommand(fallbackMethod = "testHystrixError")@GetMapping("/testHystrix")public String testHystrix(){log.info("testHystrix 接口调用 apiCmsServiceFeignClient.getHello");String value = apiCmsServiceFeignClient.getHello();return "[testHystrix] 验证断路器" + value;}public String testHystrixError(){log.info("{} testHystrixError 调用失败",System.currentTimeMillis());return "enable testHystrixError";}
2.1.1 正常性测试
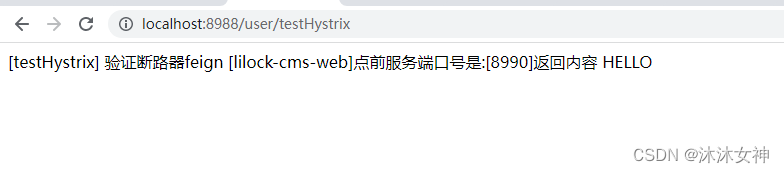
2.1.2 停掉cms服务,模拟服务不可用
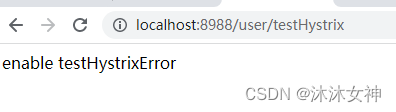
2.2 通过DefaultProperties实现全局fallback
时候一个类里面会有多个 Hystrix 方法,每个方法都是类似配置的话会冗余很多代码,这时候我们可以在类上使用 @DefaultProperties 注解来给整个类的 Hystrix 方法设置一个默认降级方法,特别标注的,降级走特别标注的方法,没有特别标注的,降级走默认方法
@RestController
@RequestMapping(path = "/user")
@Api(value = "系统用户",tags = {"系统用户"})
@Slf4j
@DefaultProperties(defaultFallback = "defaultFallBackMethod")
public class UserController {/**** 模拟全局配置fallback*/@HystrixCommand@GetMapping("/testHystrixTimeOutFallback")public BaseResult testHystrixTimeOutFallback(@RequestParam("time") long time){BaseResult<String> value = apiCmsHystrixServiceFeignClient.getHystrixTimeOut(time);log.info("testHystrixTimeOutFallback 接口调用 响应结果:{}",value);try{Thread.sleep(time);}catch (Exception e){}return value;}public BaseResult defaultFallBackMethod(){String errorMsg = System.currentTimeMillis() + "defaultFallBackMethod 调用失败触发熔断";log.error("{}",errorMsg);return BaseResult.faild(errorMsg);}
}2.2.1 停到cms服务,模拟测试

2.3 通过自定义参数配置接口的熔断策略
配置一个超时时间,并且fallback走公共模式
/*** 模拟带参数走服务熔断* @return*/@HystrixCommand(commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "1500")})@GetMapping("/testHystrixTimeDefault")public BaseResult testHystrixTimeDefault(long time){log.info("testHystrixTimeDefault 接口调用 apiCmsHystrixServiceFeignClient.testHystrixDefault");BaseResult<String> value = apiCmsHystrixServiceFeignClient.getHystrix();try{Thread.sleep(time);}catch (Exception e){}return value;}public BaseResult defaultFallBackMethod(){String errorMsg = System.currentTimeMillis() + "defaultFallBackMethod 调用失败触发熔断";log.error("{}",errorMsg);return BaseResult.faild(errorMsg);}接口sleep 1000ms 时间小于降级1500ms时间,正常返回

接口sleep 2000ms时间大于降级1500ms时间,触发降级

3.开启feign集成hystrix
配置文件开启
feign:hystrix:enabled: true3.1 FeignClient 接口实现降级策略,FallbackFactory
fallbackFactory的好处是可以统一配置
当然Api接口上也可以单独配置@HystrixCommand
package lilock.cn.cms.api;import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import lilock.cn.cms.api.fallback.ApiCmsHystrixServiceFeignClientFallbackFactory;
import lilock.cn.common.resp.BaseResult;
import lilock.cn.common.ribbon.config.FeignConfig;
import lilock.cn.common.ribbon.constant.ApplicationServiceConstants;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;//FeignClient实现了FallbackFactory
@FeignClient(value = ApplicationServiceConstants.LILOCK_CMS_WEB,configuration = {FeignConfig.class},fallbackFactory = ApiCmsHystrixServiceFeignClientFallbackFactory.class)
public interface ApiCmsHystrixServiceFeignClient {@GetMapping("/getHystrix")BaseResult<String> getHystrix();@GetMapping("/getHystrixTimeOut")@HystrixCommandBaseResult<String> getHystrixTimeOut(@RequestParam long time);
}
3.1.1 服务正常测试
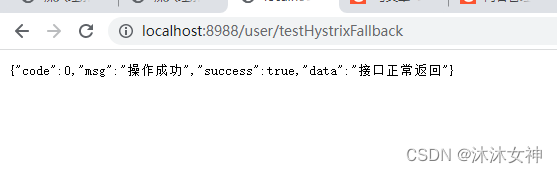
3.1.2 停掉api服务测试
可以看到触发了fallbackFactory的服务降级,服务降级之后还会继续调用下游api

3.1.3 继续模拟频繁调用接口,则会触发熔断
当降级的数量达到一定的百分比之后,接口就会触发熔断,触发熔断之后不会继续调用下游api

4.全局Hystrix配置
hystrix:command:#全局默认配置default:execution:timeout:#是否给方法执行设置超时时间,默认为true。一般我们不要改。enabled: trueisolation:#配置请求隔离的方式,这里是默认的线程池方式。还有一种信号量的方式semaphore,使用比较少。strategy: threadPoolsemaphore:maxConcurrentRequests: 1000thread:#方式执行的超时时间,默认为1000毫秒,在实际场景中需要根据情况设置timeoutInMilliseconds: 60000#发生超时时是否中断方法的执行,默认值为true。不要改。interruptOnTimeout: true#是否在方法执行被取消时中断方法,默认值为false。没有实际意义,默认就好!interruptOnCancel: false#熔断器相关配置##并发执行的最大线程数,默认10coreSize: 200#说明:是否允许线程池扩展到最大线程池数量,默认为false。allowMaximumSizeToDivergeFromCoreSize: true#说明:线程池中线程的最大数量,默认值是10。此配置项单独配置时并不会生效,需要启用allowMaximumSizeToDivergeFromCoreSizemaximumSize: 200#说明1:作业队列的最大值,默认值为-1。表示队列会使用SynchronousQueue,此时值为0,Hystrix不会向队列内存放作业。#说明2:如果此值设置为一个正int型,队列会使用一个固定size的LinkedBlockingQueue,此时在核心线程池都忙碌的情况下,会将作业暂时存放在此队列内,但是超出此队列的请求依然会被拒绝maxQueueSize: 20000#设置队列拒绝请求的阀值,默认为5。queueSizeRejectionThreshold: 30000circuitBreaker:#说明:是否启动熔断器,默认为true。我们使用Hystrix的目的就是为了熔断器,不要改,否则就不要引入Hystrix。enabled: true#说明1:启用熔断器功能窗口时间内的最小请求数,假设我们设置的窗口时间为10秒,#说明2:那么如果此时默认值为20的话,那么即便10秒内有19个请求都失败也不会打开熔断器。#说明3:此配置项需要根据接口的QPS进行计算,值太小会有误打开熔断器的可能,而如果值太大超出了时间窗口内的总请求数,则熔断永远也不会被触发#说明4:建议设置一般为:QPS*窗口描述*60%requestVolumeThreshold: 3000#说明1:熔断器被打开后,所有的请求都会被快速失败掉,但是何时恢复服务是一个问题。熔断器打开后,Hystrix会在经过一段时间后就放行一条请求#说明2:如果请求能够执行成功,则说明此时服务可能已经恢复了正常,那么熔断器会关闭;相反执行失败,则认为服务仍然不可用,熔断器保持打开。#说明3:所以此配置的作用是指定熔断器打开后多长时间内允许一次请求尝试执行,官方默认配置为5秒。sleepWindowInMilliseconds: 5000#说明1:该配置是指在通过滑动窗口获取到当前时间段内Hystrix方法执行失败的几率后,根据此配置来判断是否需要打开熔断器#说明2:这里官方的默认配置为50,即窗口时间内超过50%的请求失败后就会打开熔断器将后续请求快速失败掉errorThresholdPercentage: 70#说明:是否强制启用熔断器,默认false,没有什么场景需要这么配置,忽略!forceOpen: false#说明:是否强制关闭熔断器,默认false,没有什么场景需要这么配置,忽略!forceClosed: false5.参考
https://zhuanlan.zhihu.com/p/339535352
https://blog.csdn.net/weixin_40482816/article/details/119215962